Искусственный интеллект
Adobe Research расширяет возможности редактирования лиц в Disentangled GAN

Нетрудно понять, почему запутанность Это проблема синтеза изображений, поскольку она часто встречается и в других сферах жизни. Например, удалить куркуму из карри гораздо сложнее, чем избавиться от маринованных огурцов в бургере, а уменьшить сладость в чашке кофе практически невозможно. Некоторые вещи просто идут в комплекте.
Аналогичным образом, запутанность является камнем преткновения для архитектур синтеза изображений, которые в идеале хотели бы разделить различные функции и концепции при использовании машинного обучения для создания или редактирования лиц (или Собаки, Лодкиили любой другой домен).
Если бы вы могли отделить нити, такие как возраст, пол, цвет волос, оттенок кожи, эмоцияи т. д., вы бы получили начало настоящей инструментарности и гибкости в фреймворке, который мог бы создавать и редактировать изображения лиц на действительно детальном уровне, не вовлекая нежелательных «пассажиров» в эти преобразования.

При максимальной запутанности (вверху слева) все, что вы можете сделать, это изменить образ изученной сети GAN на образ другого человека.
Это эффективное использование новейшей технологии компьютерного зрения искусственного интеллекта для достижения того, что было решено другими средствами. более тридцати лет назад.
При определенной степени разделения («среднее разделение» на изображении выше) можно вносить изменения в стиль, например, менять цвет волос, выражение лица, наносить косметику и ограниченный поворот головы, а также многое другое.

Источник: FEAT: редактирование лица с вниманием, февраль 2022 г., https://arxiv.org/pdf/2202.02713.pdf
За последние два года было предпринято несколько попыток создать интерактивную среду редактирования лица, позволяющую пользователю изменять характеристики лица с помощью ползунков и других традиционных взаимодействий с пользовательским интерфейсом, сохраняя при этом основные черты целевого лица нетронутыми при внесении дополнений или изменений. Однако это оказалось проблемой из-за запутанности основных функций/стилей в скрытом пространстве GAN.
Так, например, очки черта часто сочетается с в возрасте черта, означающая, что добавление очков может также «состарить» лицо, в то время как старение лица может добавить очки, в зависимости от степени примененного разделения высокоуровневых признаков (см. примеры в разделе «Тестирование» ниже).
В частности, стало практически невозможно изменить цвет волос и другие их параметры без пересчета прядей и их расположения, что создает «шипучий» переходный эффект.

Источник: демонстрация InterFaceGAN (CVPR 2020), https://www.youtube.com/watch?v=uoftpl3Bj6w.
Обход GAN от латентного к латентному
Новая бумага под руководством Adobe вошел для WACV 2022 предлагает новый подход к этим основным проблемам в статье озаглавленный От латентного к латентному: обученный преобразователь для сохранения идентичности, редактирование нескольких атрибутов лица в изображениях, созданных StyleGAN.

Дополнительный материал из бумаги От латентного к латентному: обученный преобразователь для сохранения идентичности, редактирование нескольких атрибутов лица в изображениях, созданных StyleGAN. Здесь мы видим, что базовые характеристики в изученном лице не перетаскиваются в несвязанные изменения. См. полное видео, вставленное в конце статьи, для большей детализации и разрешения. Источник: https://www.youtube.com/watch?v=rf_61llRH0Q
Документ возглавляет научный сотрудник Adobe Сиаваш Ходададе вместе с четырьмя другими исследователями Adobe и исследователем с факультета компьютерных наук Университета Центральной Флориды.
Эта статья интересна отчасти тем, что Adobe уже некоторое время работает в этой области, и заманчиво представить, что эта функциональность войдет в проект Creative Suite в ближайшие несколько лет; но главным образом потому, что архитектура, созданная для проекта, использует другой подход к сохранению визуальной целостности в редакторе лиц GAN при внесении изменений.
Авторы заявляют:
«[Мы] обучаем нейронную сеть выполнять преобразование из латентного в латентное, которое находит скрытую кодировку, соответствующую изображению с измененным атрибутом. Поскольку метод является одноразовым, он не зависит от линейной или нелинейной траектории постепенного изменения атрибутов.
«Обучая сеть от начала до конца по полному конвейеру генерации, система может адаптироваться к скрытым пространствам готовых архитектур генераторов. Сохраняющие свойства, такие как сохранение личности человека, могут быть закодированы в виде обучающих потерь.
«После обучения латентно-латентной сети ее можно использовать повторно для произвольных изображений без повторного обучения».
Этот последний этап означает, что предлагаемая архитектура поставляется конечному пользователю в готовом виде. Для её реализации всё ещё требуется запустить нейронную сеть на локальных ресурсах, но новые изображения могут быть «загружены» и готовы к изменению практически мгновенно, поскольку фреймворк достаточно развязан и не требует дополнительного обучения, специфичного для конкретных изображений.
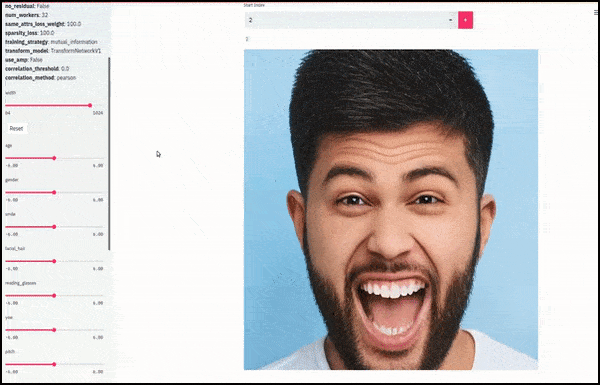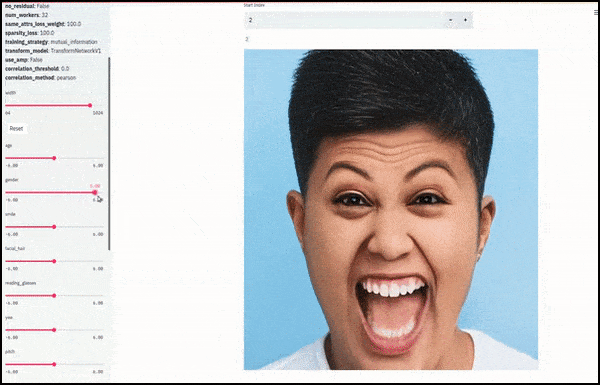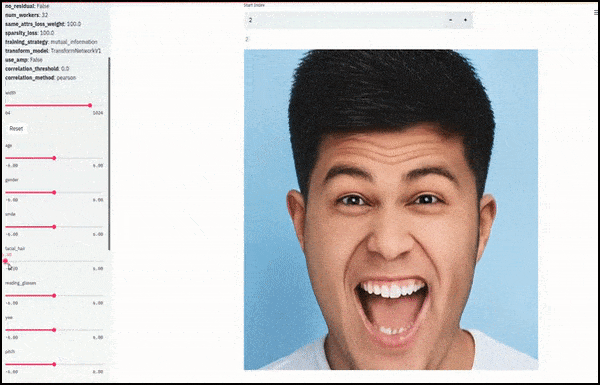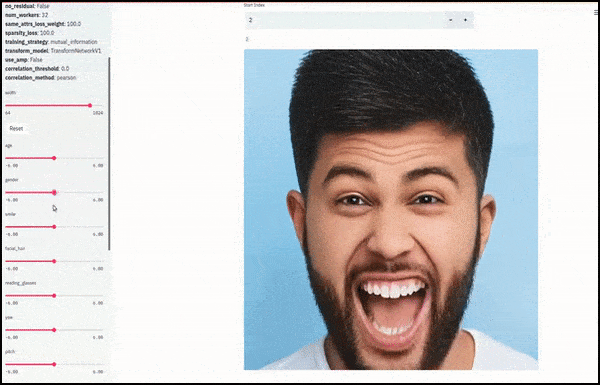
Пол и растительность на лице менялись, поскольку ползунки прокладывали случайные и произвольные пути в скрытом пространстве, а не просто «перемещались между конечными точками». Смотрите видео в конце статьи, чтобы увидеть больше преобразований в лучшем разрешении.
Среди основных достижений работы — способность сети «замораживать» идентичности в скрытом пространстве, изменяя только атрибут в целевом векторе, и предоставлять «корректирующие термины», сохраняющие преобразуемые идентичности.
По сути, предлагаемая сеть встроена в более широкую архитектуру, которая организует все обработанные элементы, проходящие через предварительно обученные компоненты с фиксированными весами, которые не будут вызывать нежелательных побочных эффектов при преобразованиях.
Поскольку тренировочный процесс зависит от тройни который может быть сгенерирован либо начальным изображением (под инверсия ГАН) или существующее начальное скрытое кодирование, весь процесс обучения не контролируется, а неявные действия обычного набора систем маркировки и курирования в таких системах эффективно встроены в архитектуру. Фактически, новая система использует готовые регрессоры атрибутов:
«Количество атрибутов, которыми наша сеть может независимо управлять, ограничено только возможностями распознавателя(ей) — если у нас есть распознаватель для атрибута, мы можем добавить его к произвольным лицам. В наших экспериментах мы обучили сеть латентно-латентных сигналов корректировать 35 различных атрибутов лица, что больше, чем любой предыдущий подход».
Система включает в себя дополнительную защиту от нежелательных преобразований с «побочными эффектами»: при отсутствии запроса на изменение атрибута латентно-латентная сеть сопоставляет латентный вектор с собой, что еще больше повышает стабильную устойчивость целевой идентичности.
Признание лица
Одна из повторяющихся проблем с GAN и редакторами лиц на основе кодировщика/декодера за последние несколько лет заключалась в том, что применяемые преобразования имеют тенденцию ухудшать сходство. Для борьбы с этим в проекте Adobe используется встроенная сеть распознавания лиц под названием Фейснет как дискриминатор.

Архитектура проекта, см. в левом нижнем углу включение FaceNet. Источник: От латентного к латентному: обученный преобразователь для сохранения идентичности, редактирование нескольких атрибутов лица в изображениях, созданных StyleGAN, Открытый доступ.
(Отлично, это кажется обнадеживающим шагом к интеграции стандартных систем идентификации по лицу и даже системы распознавания выражений в генеративные сети, что, возможно, является лучшим способом преодоления слепой пиксель>картирование пикселей которая доминирует в современных архитектурах дипфейков за счет точности выражения и других важных областей в секторе генерации лиц.)
Доступ ко всем областям в скрытом пространстве
Ещё одной впечатляющей особенностью фреймворка является его способность произвольно перемещаться между потенциальными преобразованиями в латентном пространстве по желанию пользователя. Несколько предыдущих систем, предоставлявших исследовательские интерфейсы, часто заставляли пользователя, по сути, «перемещаться» между фиксированными временными шкалами преобразований объектов — впечатляющий, но зачастую довольно линейный или ограничивающий опыт.

С Улучшение равновесия GAN за счет повышения пространственной осведомленности: здесь пользователь просматривает диапазон потенциальных точек перехода между двумя местоположениями в скрытом пространстве, но в пределах предварительно обученных местоположений в скрытом пространстве. Для применения других видов преобразования на основе того же материала необходима реконфигурация и/или переобучение. Источник: https://genforce.github.io/eqgan/
Помимо возможности обработки совершенно новых изображений, пользователь также может вручную «заморозить» элементы, которые он хочет сохранить в процессе преобразования. Таким образом, пользователь может гарантировать, что, например, фон не сместится, а глаза останутся открытыми или закрытыми.
Цены
Сеть атрибутивной регрессии обучалась на трех сетях: ФФШК, CelebAMask-HQ, и локальная сеть, сгенерированная GAN, полученная путем выборки 400,000 XNUMX векторов из Z-пространства СтильGAN-V2.
Изображения, не относящиеся к распространению (OOD), были отфильтрованы, а атрибуты извлечены с помощью Microsoft API лица, с результирующим набором изображений, разделенным на 90/10, оставив 721,218 72,172 обучающих изображений и XNUMX XNUMX тестовых изображения для сравнения.
Тестирование
Хотя экспериментальная сеть изначально была настроена на 35 потенциальных преобразований, они были сокращены до восьми, чтобы провести аналогичное тестирование на сопоставимых платформах. ИнтерфейсГАН, ГАНСпейс и СтильФлоу.
Восемь выбранных атрибутов были Возраст, Облысение, Борода, Выражение, пол, Бокалы , Pitch и Рыскание. Было необходимо переоснастить конкурирующие платформы для некоторых из восьми атрибутов, которые не были предусмотрены в исходном дистрибутиве, таких как добавление облысение и борода к InterFaceGAN.
Как и ожидалось, в конкурирующих архитектурах возник более высокий уровень запутанности. Например, в одном тесте InterFaceGAN и StyleFlow изменили пол испытуемого, когда его попросили подать заявку. возраст:

Две конкурирующие платформы добавили изменение пола в преобразование «возраста», а также изменили цвет волос без прямого указания пользователя.
Кроме того, двое соперников обнаружили, что очки и возраст неразделимы:

Очки и смена цвета волос без дополнительной оплаты!
Это не однозначная победа исследования: как можно увидеть в прилагаемом видео, встроенном в конец статьи, фреймворк наименее эффективен при попытке экстраполяции различных углов (рыскания), в то время как GANSpace показывает лучший общий результат для возраст и введение очки. Латентная структура, связанная с GANSpace и StyleFlow в отношении добавления шага (угла головы).

Результаты рассчитаны на основе калибровки Детектор лиц MTCNN. Чем ниже результаты, тем лучше.
Для получения более подробной информации и лучшего разрешения примеров посмотрите прилагаемое к статье видео ниже.
Впервые опубликовано 16 февраля 2022 г.












