Inteligență artificială
UniTune: Alternativa Neurală de Editare a Imaginilor de la Google
Cercetarea Google, pare să atace editarea imaginilor pe baza textului din mai multe direcții și, probabil, așteaptă să vadă ce “funcționează”. La scurt timp după lansarea săptămânii trecute a hârtiei Imagic, gigantul căutării a propus o metodă latentă de difuzie suplimentară pentru efectuarea unor editări bazate pe IA pe imagini prin comenzi text, numită UniTune.
Pe baza exemplelor prezentate în noua lucrare a proiectului, UniTune a obținut un grad extraordinar de dezlegare a poziției semantice și a ideii de la conținutul real al imaginii:



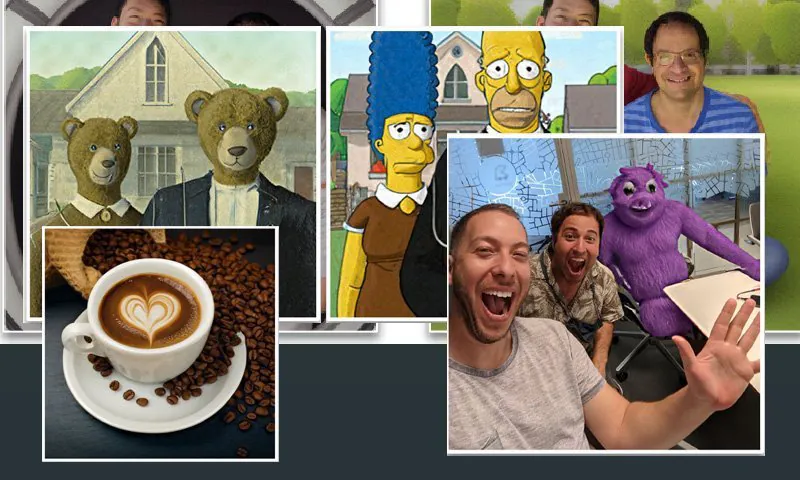
Comanda UniTune asupra compoziției semantice este remarcabilă. Observați cum, în rândul superior de imagini, fețele celor două persoane nu au fost distorsionate de transformarea extraordinară a restului imaginii sursă (dreapta). Sursă: https://arxiv.org/pdf/2210.09477.pdf
Ca fanii Stable Diffusion au învățat deja, aplicarea editărilor la secțiuni parțiale ale unei imagini fără a altera negativ restul imaginii poate fi o operațiune dificilă, uneori imposibilă. Deși distribuțiile populare, cum ar fi AUTOMATIC1111, pot crea măști pentru editări locale și restricționate, procesul este tortuos și adesea imprevizibil.
Răspunsul evident, cel puțin pentru un practician în domeniul viziunii computaționale, este de a interpune un strat de segmentare semantică care poate recunoaște și izola obiecte dintr-o imagine fără intervenția utilizatorului, și, într-adevăr, au existat câteva inițiative noi recent în această direcție.
O altă posibilitate pentru blocarea operațiunilor de editare a imaginilor neurale haotice este de a utiliza modulul Contrastive Language-Image Pre-training (CLIP) influent al OpenAI, care se află la baza modelelor de difuzie latentă, cum ar fi DALL-E 2 și Stable Diffusion, pentru a acționa ca un filtru în momentul în care un model text-Imagine este gata să trimită un render interpretat înapoi utilizatorului. În acest context, CLIP ar trebui să acționeze ca un sentinel și modul de control al calității, respingând renderurile malformed sau altfel inadecvate. Acest lucru urmează să fie instituit (legătură Discord) la portalul API-driven al Stability.ai, DreamStudio.
Cu toate acestea, deoarece CLIP este, în mod evident, atât vinovat, cât și soluție într-un astfel de scenariu (deoarece a informat, de asemenea, modul în care imaginea a evoluat), și deoarece cerințele de hardware pot depăși ceea ce este probabil disponibil local pentru un utilizator final, această abordare poate să nu fie ideală.
Limbaj Comprimat
UniTune propus în schimb “reglează” un model de difuzie existent – în acest caz, Imagen al Google, deși cercetătorii afirmă că metoda este compatibilă cu alte arhitecturi de difuzie latentă – astfel încât un token unic este injectat în el, care poate fi chemat prin includerea lui într-un prompt de text.
La prima vedere, acest lucru sună ca DreamBooth al Google, care în prezent este o obsesie printre fanii și dezvoltatorii Stable Diffusion, care poate injecta caractere sau obiecte noi într-un punct de control existent, adesea în mai puțin de o oră, pe baza a doar câteva imagini sursă; sau ca Textual Inversion, care creează fișiere “sidecar” pentru un punct de control, care sunt apoi tratate ca și cum ar fi fost antrenate inițial în model, și pot profita de resursele vaste ale modelului prin modificarea clasificatorului său de text, rezultând un fișier mic (în comparație cu punctele de control minimal prăjite de 2 GB ale DreamBooth).
De fapt, cercetătorii afirmă că UniTune a respins ambele abordări. Ei au constatat că Textual Inversion a omis prea multe detalii importante, în timp ce DreamBooth “a performant mai prost și a durat mai mult” decât soluția pe care au decis-o în final.
Cu toate acestea, UniTune utilizează aceeași abordare de “metaprompt” semantic încapsulat ca și DreamBooth, cu modificări antrenate chemate prin cuvinte unice alese de antrenor, care nu vor intra în conflict cu niciun termen care există într-un model public lansat cu atenție.
‘Pentru a efectua operațiunea de editare, vom eșantiona modelele fine-tune cu promptul “[rare_tokens] edit_prompt” (de exemplu, “beikkpic două câini într-un restaurant” sau “beikkpic un minion”).’
Procesul
Metoda UniTune trimite, în esență, imaginea originală printr-un model de difuzie cu un set de instrucțiuni despre cum ar trebui să fie modificată, utilizând depozitele vaste de date disponibile antrenate în model. În efect, puteți face acest lucru chiar acum cu funcționalitatea img2img a Stable Diffusion – dar nu fără a deforma sau a schimba în vreun fel părțile imaginii pe care ați prefera să le păstrați.
În timpul procesului UniTune, sistemul este fine-tune, adică UniTune forțează modelul să reia antrenamentul, cu majoritatea straturilor sale decongelate (a se vedea mai jos). În majoritatea cazurilor, fine-tuning-ul va scădea valorile generale de pierdere ale unui model de înaltă performanță, câștigat cu greu, în favoarea injectării sau rafinării unui alt aspect care este dorit să fie creat sau îmbunătățit.
Cu toate acestea, cu UniTune, pare că copia modelului care este acționată, deși poate cântări câteva gigaocteți sau mai mult, va fi tratată ca o “coajă” collaterală de unică folosință și va fi eliminată la sfârșitul procesului, după ce și-a îndeplinit un singur scop. Acest tip de tonaj de date casuale devine o criză de stocare de zi cu zi pentru fanii DreamBooth, ale căror modele, chiar și atunci când sunt tăiate, nu sunt mai mici de 2 GB pe subiect.
Similar cu Imagic, principala reglare în UniTune are loc la cele două straturi inferioare ale celor trei straturi din Imagen (64px, 64px>256px și 256px>1024px). Spre deosebire de Imagic, cercetătorii văd o valoare potențială în optimizarea reglării și pentru acest ultim și cel mai mare strat de superraționare (deși nu au încercat încă).
Pentru stratul inferior de 64px, modelul este împins spre imaginea de bază în timpul antrenamentului, cu multiple perechi de imagine/text introduse în sistem pentru 128 de iterații la o dimensiune de lot de 4 și cu Adafactor ca funcție de pierdere, care funcționează la o rată de învățare de 0,0001. Deși encoderul T5 este înghețat în timpul acestei reglări fine, el este, de asemenea, înghețat în timpul antrenamentului principal al Imagen.
Operațiunea de mai sus este apoi repetată pentru stratul 64>256px, utilizând aceeași procedură de augmentare a zgomotului folosită în antrenamentul original al Imagen.
Eșantionare
Există multe metode posibile de eșantionare prin care pot fi obținute modificările efectuate, inclusiv Ghidarea liberă a clasificatorului (CFG), o piesă principală și a Stable Diffusion. CFG definește, în esență, măsura în care modelul este liber să “urmeze imaginația” și să exploreze posibilitățile de rendering – sau, la setări mai mici, măsura în care ar trebui să se conformeze datelor de intrare și să facă modificări mai puțin dramatice.

Similar cu Textual Inversion (mai puțin cu DreamBooth), UniTune este receptiv la aplicarea unor stiluri grafice distincte asupra imaginilor originale, precum și editări mai fotorealistice.
Cercetătorii au experimentat, de asemenea, cu tehnica “început târziu” a SDEdit, în care sistemul este încurajat să păstreze detaliile originale prin faptul că este doar parțial “zgomot” de la început, dar mai degrabă menține caracteristicile sale esențiale. Deși cercetătorii au folosit-o doar pe stratul inferior (64px), ei cred că ar putea fi o tehnică de eșantionare utilă în viitor.
Cercetătorii au exploatat, de asemenea, prompt-to-prompt ca o tehnică textului suplimentară pentru a condiționa modelul:
‘În setarea “prompt la prompt”, am găsit că o tehnică pe care o numim Ghidare a promptului este deosebit de utilă pentru a regla fidelitatea și expresivitatea. ‘
‘Ghidarea promptului este similară cu Ghidarea liberă a clasificatorului, cu excepția faptului că punctul de referință este un prompt diferit și nu modelul necondiționat. Acest lucru îndrumă modelul spre diferența dintre cele două prompturi.’

Prompt-la-prompt în UniTune, izolând în mod eficient zonele care trebuie modificate.
Cu toate acestea, ghidarea promptului, spun autorii, a fost necesară doar ocazional în cazurile în care CFG a eșuat în a obține rezultatul dorit.
O altă abordare de eșantionare inovatoare întâlnită în timpul dezvoltării UniTune a fost interpolarea, în care zonele imaginii sunt suficient de distincte, astfel încât atât imaginea originală, cât și cea modificată, sunt foarte asemănătoare în compoziție, permițând o interpolare “naivă” să fie utilizată.

Interpolarea poate face procesele mai intense ale UniTune redundante în cazurile în care zonele care trebuie transformate sunt discrete și bine delimitate.
Autorii sugerează că interpolarea ar putea funcționa atât de bine, pentru un număr mare de imagini sursă țintă, încât ar putea fi utilizată ca setare implicită și observă, de asemenea, că are puterea de a efectua transformări extraordinare în cazurile în care nu trebuie negociate ocluzii complexe prin metode mai intensive.
UniTune poate efectua editări locale cu sau fără măști de editare, dar poate decide, de asemenea, unilateral unde să plaseze editările, cu o combinație neobișnuită de putere interpretativă și esențializare robustă a datelor de intrare:

În imaginea de sus din a doua coloană, UniTune, însărcinat cu inserarea unui ‘tren roșu în fundal’, l-a plasat într-o poziție potrivită și autentică. Observați în celelalte exemple cum integritatea semantică a imaginii sursă este menținută, chiar și în mijlocul unor schimbări extraordinare în conținutul de pixeli și stilurile de bază ale imaginilor.
Latency
Deși prima iterație a oricărui sistem nou va fi lentă, și deși este posibil ca implicarea comunității sau angajamentul corporativ (nu este, de obicei, ambele) să accelereze și să optimizeze o rutină care consumă multe resurse, atât UniTune, cât și Imagic efectuează unele manevre majore de învățare automată pentru a crea aceste editări uimitoare, și este discutabilă măsura în care un astfel de proces care consumă resurse ar putea vreodată fi redus la utilizare casnică, în loc de acces prin API (deși acesta din urmă poate fi mai de dorit pentru Google).
În acest moment, timpul de tur-retur de la intrare la rezultat este de aproximativ 3 minute pe un GPU T4, cu aproximativ 30 de secunde suplimentare pentru inferență (ca orice rutină de inferență). Autorii recunosc că acesta este un timp de latență ridicat și abia calificat ca “interactiv”, dar observă, de asemenea, că modelul rămâne disponibil pentru editări suplimentare odată ce este inițial reglat, până când utilizatorul este terminat cu procesul, ceea ce reduce timpul pe editare.
Publicat pentru prima dată pe 21 octombrie 2022.













{kind=link}
{kind=link}
{kind=link}