Inteligență artificială
Modelul de inteligență artificială GPT-4o al OpenAI: Transformarea interacțiunii om-mașină

OpenAI a lansat cel mai recent și avansat model de limbaj – GPT-4o, cunoscut și sub numele de modelul “Omni“. Acest sistem revoluționar de inteligență artificială reprezintă un salt uriaș înainte, cu capacități care estompează granița dintre inteligența umană și cea artificială.
La baza GPT-4o se află natura sa multimodală nativă, care îi permite să proceseze și să genereze conținut în mod transparent, traversând texte, audio, imagini și video. Această integrare a mai multor modalități într-un singur model este o premieră și promite să schimbe radical modul în care interacționăm cu asistenții inteligenți artificiali.
Dar GPT-4o este mult mai mult decât doar un sistem multimodal. El se mândrește cu o îmbunătățire spectaculoasă a performanței față de predecesorul său, GPT-4, și lăsă în urmă modelele concurente, cum ar fi Gemini 1.5 Pro, Claude 3 și Llama 3-70B. Să explorăm mai în detaliu ce face acest model de inteligență artificială cu adevărat revoluționar.
Performanță și Eficiență fără precedent
Unul dintre cele mai impresionante aspecte ale GPT-4o este capacitatea sa de performanță fără precedent. Conform evaluărilor OpenAI, modelul are o avansare remarcabilă de 60 de puncte Elo față de precedentul lider, GPT-4 Turbo. Acest avantaj semnificativ plasează GPT-4o într-o ligă a sa, strălucind chiar și printre cele mai avansate modele de inteligență artificială disponibile în prezent.
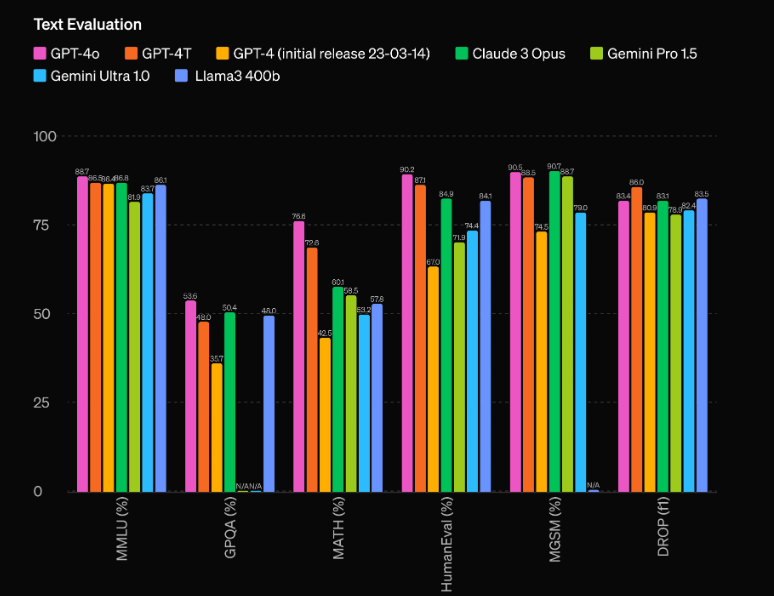
Dar performanța brută nu este singurul domeniu în care GPT-4o strălucește. Modelul se mândrește și cu o eficiență impresionantă, funcționând la dublul vitezei GPT-4 Turbo, în timp ce costă doar jumătate din prețul de funcționare. Această combinație de performanță superioară și eficiență face din GPT-4o o propunere extrem de atractivă pentru dezvoltatori și afaceri care doresc să integreze capacități de inteligență artificială de ultimă generație în aplicațiile lor.
Capacități Multimodale: Combinarea Textului, Audio și Viziunii
Poate cel mai revoluționar aspect al GPT-4o este natura sa multimodală nativă, care îi permite să proceseze și să genereze conținut în mod transparent, traversând multiple modalități, incluzând text, audio și viziune. Această integrare a mai multor modalități într-un singur model este o premieră și promite să revoluționeze modul în care interacționăm cu asistenții inteligenți artificiali.
Cu GPT-4o, utilizatorii pot angaja în conversații naturale și în timp real, utilizând vorbirea, modelul recunoscând și răspunzând instantaneu la intrările audio. Dar capacitățile nu se opresc aici – GPT-4o poate interpreta și genera conținut vizual, deschizând o lume de posibilități pentru aplicații care variază de la analiza și generarea de imagini la înțelegerea și crearea de video.
Una dintre cele mai impresionante demonstrații ale capacităților multimodale ale GPT-4o este abilitatea sa de a analiza o scenă sau imagine în timp real, descriind și interpretând elementele vizuale pe care le percepe. Această funcție are implicații profunde pentru aplicații precum tehnologiile asistive pentru persoanele cu deficiențe de vedere, precum și în domenii cum ar fi securitatea, supravegherea și automatizarea.
Dar capacitățile multimodale ale GPT-4o se extind dincolo de simpla înțelegere și generare de conținut în diferite modalități. Modelul poate combina în mod transparent aceste modalități, creând experiențe imersive și angajante. De exemplu, în timpul demo-ului live, GPT-4o a putut genera o melodie pe baza condițiilor de intrare, combinând înțelegerea limbajului, teoria muzicală și generarea audio într-o ieșire coerentă și impresionantă.
Utilizarea GPT0 cu Python
import openai
# Înlocuiți cu cheia dvs. API actuală
OPENAI_API_KEY = "cheia_dvs_api_aici"
# Funcție pentru a extrage conținutul răspunsului
def get_response_content(response_dict, exclude_tokens=None):
if exclude_tokens is None:
exclude_tokens = []
if response_dict and response_dict.get("choices") and len(response_dict["choices"]) > 0:
content = response_dict["choices"][0]["message"]["content"].strip()
if content:
for token in exclude_tokens:
content = content.replace(token, '')
return content
raise ValueError(f"Imposibil de rezolvat răspunsul: {response_dict}")
# Funcție asincronă pentru a trimite o cerere către API-ul de chat OpenAI
async def send_openai_chat_request(prompt, model_name, temperature=0.0):
openai.api_key = OPENAI_API_KEY
message = {"role": "user", "content": prompt}
response = await openai.ChatCompletion.acreate(
model=model_name,
messages=[message],
temperature=temperature,
)
return get_response_content(response)
# Exemplu de utilizare
async def main():
prompt = "Salut!"
model_name = "gpt-4o-2024-05-13"
response = await send_openai_chat_request(prompt, model_name)
print(response)
if __name__ == "__main__":
import asyncio
asyncio.run(main())
Am:
- Importat modulul openai direct, în loc de a utiliza o clasă personalizată.
- Redenumit funcția openai_chat_resolve în get_response_content și am făcut câteva modificări minore la implementarea sa.
- Înlocuit clasa AsyncOpenAI cu funcția openai.ChatCompletion.acreate, care este metoda asincronă oficială oferită de biblioteca Python OpenAI.
- Adăugat o funcție main de exemplu care demonstrează cum se utilizează funcția send_openai_chat_request.
Vă rugăm să rețineți că trebuie să înlocuiți “cheia_dvs_api_aici” cu cheia dvs. API actuală pentru ca codul să funcționeze corect.















