Inteligência artificial
SofGAN: Um Gerador de Faces GAN Que Oferece Maior Controle
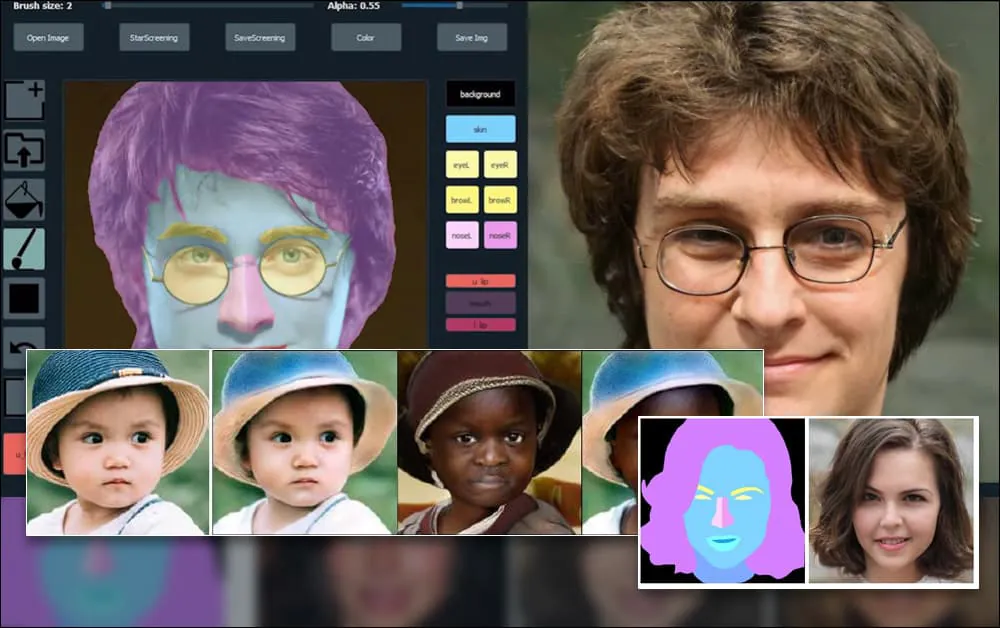
Pesquisadores em Xangai e nos EUA desenvolveram um sistema de geração de retratos baseado em GAN que permite aos usuários criar novas faces com um nível de controle até então indisponível sobre aspectos individuais, como cabelo, olhos, óculos, texturas e cor.
Para demonstrar a versatilidade do sistema, os criadores forneceram uma interface no estilo Photoshop, onde um usuário pode desenhar diretamente elementos de segmentação semântica que serão reinterpretados em imagens realistas, e que podem ser obtidos desenhando diretamente sobre fotografias existentes.
No exemplo abaixo, uma foto do ator Daniel Radcliffe é usada como modelo de traçado (e o objetivo não é produzir uma semelhança com ele, mas sim uma imagem fotorealista em geral). À medida que o usuário preenche os elementos, incluindo facetas discretas, como óculos, eles são identificados e interpretados na imagem de saída:
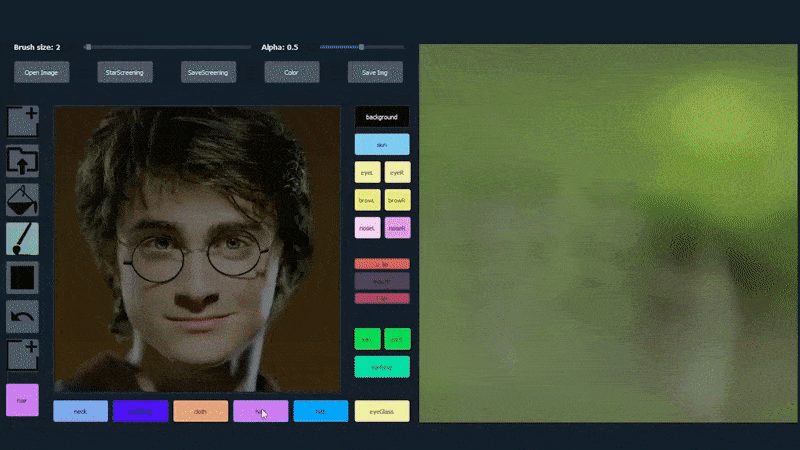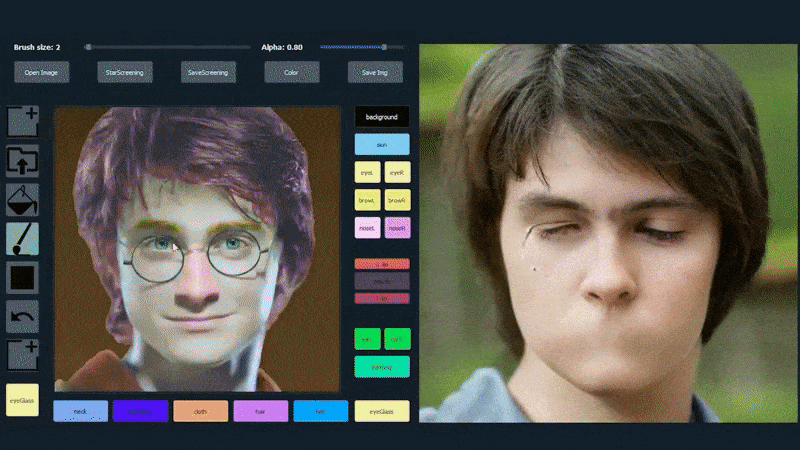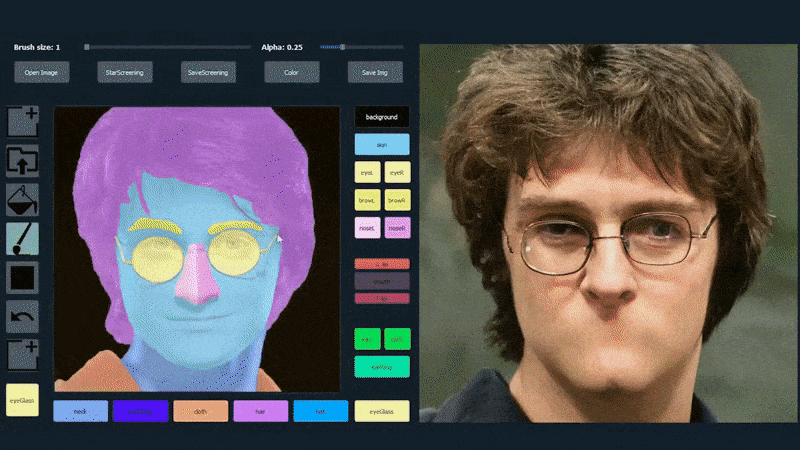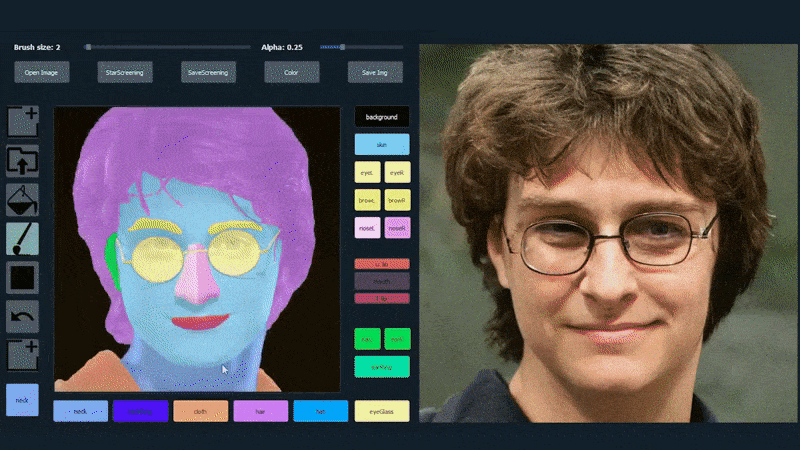
Usando uma imagem como material de traçado para um retrato gerado por SofGAN. Fonte: https://www.youtube.com/watch?v=xig8ZA3DVZ8
O artigo é intitulado SofGAN: Um Gerador de Imagens de Retrato com Estilo Dinâmico, e é liderado por Anpei Chen e Ruiyang Liu, juntamente com dois outros pesquisadores da ShanghaiTech University e outro da Universidade da Califórnia em San Diego.
Desembaralhando Recursos
A principal contribuição do trabalho não está tanto em fornecer uma experiência de usuário amigável, mas sim em ‘desembaralhar’ características de recursos faciais aprendidos, como pose e textura, o que permite que o SofGAN também gere faces que estão em ângulos indiretos em relação à visão da câmera.

Incomum entre os geradores de faces baseados em Redes Adversárias Generativas, o SofGAN pode alterar o ângulo de visão à vontade, dentro dos limites do conjunto de ângulos presentes nos dados de treinamento. Fonte: https://arxiv.org/pdf/2007.03780.pdf
Como as texturas agora estão desembaralhadas da geometria, a forma e a textura do rosto também podem ser manipuladas como entidades separadas. Em essência, isso permite a alteração da raça de uma face de origem, uma prática escandalosa que agora tem uma aplicação potencialmente útil, para a criação de conjuntos de dados de aprendizado de máquina racialmente equilibrados.

O SofGAN também suporta envelhecimento artificial e ajuste de estilo consistente com atributos em um nível granular não visto em sistemas de segmentação semelhantes > imagem, como o GauGAN da NVIDIA e o sistema de renderização neural baseado em jogos da Intel.

O SofGAN é capaz de implementar o envelhecimento como um estilo iterativo.
Outra inovação na metodologia do SofGAN é que o treinamento não requer imagens reais emparelhadas com segmentação, mas pode ser treinado diretamente em imagens reais não emparelhadas.
Os pesquisadores afirmam que a arquitetura de ‘desembaralhamento’ do SofGAN foi inspirada em sistemas de renderização de imagens tradicionais, que descompõem os elementos individuais de uma imagem. Em fluxos de trabalho de efeitos visuais, os elementos para uma composição são rotineiramente quebrados em componentes mínimos, com especialistas dedicados a cada componente.
Campo de Ocupação Semântico (SOF)
Para alcançar isso em um quadro de síntese de imagem de aprendizado de máquina, os pesquisadores desenvolveram um campo de ocupação semântico (SOF), uma extensão do campo de ocupação tradicional que individua os elementos componentes de retratos faciais. O SOF foi treinado em mapas de segmentação semântica de várias vistas calibradas, mas sem nenhuma supervisão de verdade fundamental.

Múltiplas iterações a partir de um único mapa de segmentação (abaixo à esquerda).
Além disso, mapas de segmentação 2D são obtidos por meio de ray-tracing da saída do SOF, antes de serem texturizados por um gerador GAN. Os mapas de segmentação semântica ‘sintéticos’ também são codificados em um espaço de baixa dimensionalidade por meio de um codificador de três camadas para garantir a continuidade da saída quando a visão é alterada.
O esquema de treinamento mistura espacialmente dois estilos aleatórios para cada região semântica:

A arquitetura para SofGAN.
Os pesquisadores afirmam que o SofGAN alcança uma distância de Frechet Inception (FID) mais baixa do que as abordagens atuais de estado da arte (SOTA), bem como uma métrica de semelhança de imagem de patch aprendida (LPIPS) mais alta.
As abordagens StyleGAN anteriores frequentemente foram impedidas pelo emaranhamento de recursos, no qual os elementos que compõem uma imagem estão irretrievavelmente ligados uns aos outros, causando a aparição de elementos indesejados ao lado de um elemento desejado (por exemplo, brincos podem aparecer quando uma forma de orelha é renderizada que foi informada no tempo de treinamento por uma imagem que apresentava brincos).

Ray marching é usado para calcular o volume de mapas de segmentação semântica, permitindo múltiplas vistas.
Conjuntos de Dados e Treinamento
Três conjuntos de dados foram usados no desenvolvimento de várias implementações do SofGAN: CelebAMask-HQ, um repositório de 30.000 imagens de alta resolução tiradas do conjunto de dados CelebA-HQ; NVIDIA’s Flickr-Faces-HQ (FFHQ), que contém 70.000 imagens, onde os pesquisadores rotularam as imagens com um analisador de faces pré-treinado; e um grupo autoproduzido de 122 digitalizações de retratos com regiões semânticas rotuladas manualmente.
O SOF é composto por três sub-módulos treináveis – a hiper-rede, um ray marcher (veja a imagem acima) e um classificador. O gerador StyleGAN do projeto é configurado de forma semelhante ao StyleGAN2 em certos aspectos. Aumento de dados é aplicado por meio de escalonamento e recorte aleatórios, e o treinamento apresenta regularização de caminho a cada quatro etapas. O procedimento de treinamento inteiro levou 22 dias para atingir 800.000 iterações em quatro GPUs RTX 2080 Ti sobre CUDA 10.1.
O artigo não menciona a configuração das placas 2080, que podem acomodar entre 11gb-22gb de VRAM cada, o que significa que a VRAM total empregada para a maior parte de um mês para treinar o SofGAN está em algum lugar entre 44Gb e 88Gb.
Os pesquisadores observam que resultados generalizados, de alto nível, aceitáveis começaram a surgir bastante cedo no treinamento, em 1500 iterações, três dias no treinamento. O resto do treinamento foi ocupado com o aumento lento em direção à obtenção de detalhes finos, como facetas de cabelo e olho.
O SofGAN geralmente alcança resultados mais realistas a partir de um único mapa de segmentação do que os métodos rivais, como o SPADE da NVIDIA e o Pix2PixHD, e o SEAN.

Abaixo está o vídeo lançado pelos pesquisadores. Vídeos adicionais auto-hospedados estão disponíveis na página do projeto.
https://www.youtube.com/watch?v=xig8ZA3DVZ8












