Inteligência artificial
Não, Eles Não Estavam Limitando o Claude – Na Verdade, Era Pior

Vamos falar sobre o que tem acontecido com o Claude, porque se você estiver usando ele nos últimos 30 dias, provavelmente notou que algo estava errado.
Nos últimos seis semanas, os usuários do Claude estavam perdendo a cabeça. A partir de meados de agosto, reclamações começaram a inundar o Reddit, X e fóruns de desenvolvedores. Os problemas estavam por toda parte:
- Código que funcionava perfeitamente de repente estava quebrado
- O Claude alegava que fez alterações em arquivos quando não fez
- Caracteres tailandês ou chinês aleatórios aparecendo em respostas em inglês
- Instruções sendo completamente ignoradas
- A mesma solicitação dando respostas de qualidade muito diferentes
- Usuários do Claude Code dizendo que parecia “lobotomizado” em comparação com antes
As reclamações ficaram tão ruins que, no final de agosto, as pessoas estavam convencidas de que a Anthropic estava secretamente limitando o Claude para economizar dinheiro. Teorias da conspiração estavam por toda parte – talvez estivessem reduzindo a qualidade durante os horários de pico, talvez tivessem trocado silenciosamente por um modelo mais barato, talvez essa fosse uma degradação intencional para gerenciar os custos dos servidores.
Os usuários estavam pagando pelo Claude Pro e estavam recebendo o que parecia ser o Claude Lite. Desenvolvedores que haviam construído fluxos de trabalho em torno do Claude estavam assistindo à sua produtividade afundar. Com isso dito, alguns usuários não estavam experimentando nenhum problema, o que tornava tudo mais confuso.
A Anthropic Finalmente Admite: Sim, Tivemos Problemas
Depois de semanas de reclamações de usuários e frustração crescente, a Anthropic acaba de publicar um enorme relatório pós-morte técnico que basicamente diz: “Você estava certo. O Claude estava quebrado. Aqui está o que aconteceu.”
E a resposta é interessante.
Resulta que não foi um problema. Foram três bugs de infraestrutura completamente separados, todos atingindo ao mesmo tempo, criando uma tempestade perfeita de degradação do AI. Eles não estavam limitando. Não estavam cortando cantos. Eles simplesmente tinham três coisas quebradas simultaneamente de maneiras que levaram seis semanas para entender e consertar.
Vou explicar exatamente o que deu errado, porque isso é realmente um olhar útil sobre como esses sistemas de AI podem falhar de maneiras que ninguém antecipa.
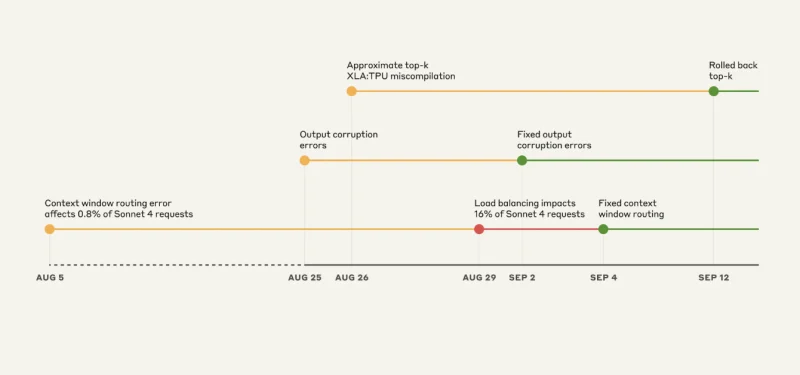
A Quebra Triplo-Bug: Uma Linha do Tempo do Caos
Fonte: Anthropic
Bug #1: O Problema do Servidor Errado
Isso é quase engraçado se você não estivesse experimentando. O Claude Sonnet 4 foi projetado para lidar com 200.000 contextos de token. Mas a partir de 5 de agosto, algumas solicitações estavam sendo encaminhadas para servidores configurados para 1 milhão de contextos de token.
Inicialmente, apenas 0,8% das solicitações foram afetadas. Não é grande coisa, certo? Errado.
Em 29 de agosto, uma atualização de balanceador de carga de rotina transformou esse problema menor em um grande problema. De repente, no pico, 16% das solicitações do Sonnet 4 estavam indo para os servidores errados. E o roteamento era “sticky”. Uma vez que você foi mal roteado, você continuou sendo mal roteado.
O impacto:
- Cerca de 30% dos usuários do Claude Code que estavam ativos durante a janela tiveram pelo menos uma solicitação mal roteada
- Os tempos de resposta afundaram para os usuários afetados
- O mesmo usuário experimentou o problema repetidamente enquanto outros tiveram zero problemas
Bug #2: O Gerador de Caracteres Aleatórios
Em 25 de agosto, a Anthropic implantou uma configuração errada em seus servidores TPU. O resultado foi que o Claude começou a inserir aleatoriamente caracteres tailandês e chinês em respostas em inglês.
Imagine pedir ao Claude para depurar seu código Python e receber isso:
def calculate_total(items):
total = 0
for item in items:
總計 += item.price # <- O que?
return ผลรวม
Isso afetou:
- Opus 4.1 e Opus 4: 25-28 de agosto
- Sonnet 4: 25 de agosto – 2 de setembro
A causa técnica foi um erro de geração de token que atribuiu alta probabilidade a caracteres que não tinham negócios ali. Ele literalmente quebrou o mecanismo fundamental de como o Claude seleciona a próxima palavra para dizer.
Bug #3: O Bug do Compilador Invisível
Isso é o assustador do ponto de vista de engenharia. Havia um bug latente no compilador XLA do Google que estava dormindo. Quando a Anthropic implantou código para melhorar a seleção de token em 25 de agosto, eles acidentalmente o acionaram.
O que esse bug fez foi genuinamente estranho – ele faria com que o Claude excluísse involuntariamente o token mais provável ao gerar texto. O Claude sabia a resposta certa, mas foi fisicamente impedido de dizê-la.
A parte realmente confusa? Eles haviam trabalhado em torno desse bug em dezembro de 2024 sem perceber. Quando “consertaram” o que pensavam ser a causa raiz em agosto, removeram o trabalho-around e soltaram o problema real.
Por Que Levou Seis Semanas para Consertar
Você pode estar se perguntando: como uma empresa como a Anthropic, com engenheiros de classe mundial, leva seis semanas para descobrir isso?
A resposta revela apenas quão complexos esses sistemas realmente são:
1. Controles de Privacidade Bloquearam a Depuração
“Nossos controles internos de privacidade e segurança limitam como e quando os engenheiros podem acessar interações do usuário com o Claude, em particular quando essas interações não são relatadas a nós como feedback.”
Eles literalmente não podiam ver o que estava quebrando a menos que os usuários relatassem explicitamente com feedback. Bom para a privacidade, terrível para a depuração.
2. Os Bugs Se Esconderam
O Claude muitas vezes se recuperava de erros individuais, fazendo com que a degradação parecesse variância normal em vez de falha sistemática. Seus benchmarks e avaliações não estavam pegando porque o modelo se autocorrigia o suficiente para passar nos testes.
3. Caos Multiplataforma
O Claude roda em AWS Trainium, NVIDIA GPUs e Google TPUs – três plataformas de hardware completamente diferentes. Cada bug se manifestou de maneira diferente em cada plataforma:
- AWS Bedrock: 0,18% das solicitações do Sonnet 4 afetadas no pico
- Google Vertex AI: Abaixo de 0,0004% afetado
- API direta: Até 16% afetado
Isso fez com que parecesse vários problemas não relacionados em vez de três bugs específicos.
4. Sintomas Sobrepostos
Com três bugs ativos simultaneamente, os sintomas estavam por toda parte. Um usuário poderia receber caracteres tailandês, outro poderia receber respostas degradadas, um terceiro poderia ver desempenho perfeito. Não havia um padrão claro para seguir.
O Que Isso Realmente Significa para a Confiabilidade do AI
Essa saga toda revela algo crucial sobre o estado atual dos sistemas de AI: eles são muito mais frágeis do que parecem.
Não estamos falando apenas do modelo de AI em si. Estamos falando de:
- Infraestrutura de roteamento que pode enviar solicitações para o lugar errado
- Implementações específicas de hardware que se comportam de maneira diferente
- Bugs de compilador que podem permanecer dormentes por meses
- Balanceadores de carga que podem amplificar problemas menores em grandes falhas
Um erro de configuração, um bug de compilador, um erro de roteamento – e de repente seu assistente de AI esquece como codificar ou começa a falar línguas que não deve.
Está Realmente Consertado?
A Anthropic diz que resolveu todos os três problemas em 16 de setembro. Eles:
- Consertaram a lógica de roteamento
- Reverteram as configurações problemáticas
- Mudaram de operações top-k aproximadas para exatas (aceitando um impacto no desempenho para precisão)
- Adicionaram monitoramento contínuo de produção
Mas os usuários ainda estão relatando problemas. Alguns desenvolvedores alegam que o Claude Code ainda se sente degradado em comparação com seu desempenho anterior. Seja:
- Efeitos residuais dos bugs
- Novos problemas que ainda não foram identificados
- Viés psicológico após semanas de problemas
- Ou degradação real contínua
…não sabemos ainda.
A Linha de Fundo
Essa situação é um caso de estudo perfeito de como os sistemas de AI complexos podem falhar de maneiras completamente inesperadas. Três bugs separados, todos acionados dentro de semanas um do outro, criaram uma percepção de degradação de qualidade maciça que levou seis semanas para diagnosticar e consertar.
Podemos dar crédito à Anthropic pela transparência. Publicar um relatório pós-morte técnico detalhado é mais do que a maioria das empresas faria. Mas também mostra apenas quão errado as coisas podem dar sob o capô desses sistemas em que estamos cada vez mais dependentes.
Para qualquer pessoa que constrói em cima do Claude ou de qualquer LLM: você precisa de redundância, validação e planos de backup. Porque, como acabamos de ver, mesmo os melhores sistemas de AI podem ter três problemas diferentes simultaneamente, e pode levar semanas antes que alguém descubra o que está realmente acontecendo.
A infraestrutura que suporta esses modelos de AI é tão importante quanto os modelos em si. E agora, essa infraestrutura está mostrando alguns problemas de crescimento sérios.












