Inteligência artificial
Não, eles não estavam estrangulando Claude – na verdade, foi pior

Tudo bem, vamos falar sobre o que está acontecendo com Claude, porque se você o usou no último mês, provavelmente notou que algo estava errado.
Nas últimas seis semanas, os usuários do Claude estão perdendo a cabeça. Desde o início de agosto, reclamações começaram a inundar o Reddit, o X e os fóruns de desenvolvedores. Os problemas estavam por todo o lado:
- Código que costumava funcionar perfeitamente foi quebrado de repente
- Claude alegaria ter feito alterações nos arquivos quando não o fez
- Caracteres aleatórios tailandeses ou chineses aparecendo em respostas em inglês
- Instruções sendo completamente ignoradas
- O mesmo prompt dando respostas de qualidade totalmente diferentes
- Usuários do Claude Code dizendo que ele parecia “lobotomizado” em comparação a antes
As reclamações ficaram tão graves que, no final de agosto, as pessoas estavam convencidas de que a Anthropic estava secretamente limitando o serviço de Claude para economizar dinheiro. Teorias da conspiração circulavam por toda parte – talvez estivessem reduzindo a qualidade durante os horários de pico, talvez tivessem trocado discretamente por um modelo mais barato, talvez isso fosse uma degradação intencional para gerenciar os custos do servidor.
Os usuários estavam pagando por Claude Pro e obter o que parecia ser o Claude Lite. Desenvolvedores que haviam criado fluxos de trabalho em torno do Claude estavam, de repente, vendo sua produtividade despencar. Dito isso, alguns usuários não estavam enfrentando nenhum problema, o que tornava tudo ainda mais confuso.
Anthropic finalmente admite: sim, tivemos problemas
Após semanas de reclamações dos usuários e crescente frustração, A Anthropic acaba de lançar um enorme post-mortem técnico que basicamente diz: "Você estava certo. Claude estava quebrado. Eis o que aconteceu."
E a resposta é interessante.
Acontece que não era um problema só. Eram três bugs de infraestrutura completamente distintos, todos ocorrendo ao mesmo tempo, criando uma tempestade perfeita de degradação da IA. Eles não estavam limitando o desempenho. Eles não estavam cortando custos. Eles apenas tiveram três problemas diferentes quebrando simultaneamente, de maneiras que levaram seis semanas para entender e consertar completamente.
Deixe-me detalhar exatamente o que deu errado, porque esta é, na verdade, uma visão útil de como esses sistemas de IA podem falhar de maneiras que ninguém prevê.
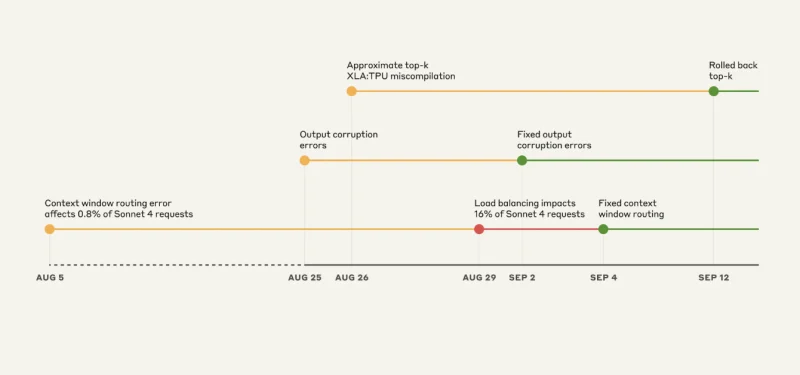
O colapso do triplo inseto: uma linha do tempo do caos
Fonte: Anthropic
Bug nº 1: O problema do servidor errado
Isso é quase engraçado se você não foi quem passou por isso. O Claude Sonnet 4 foi projetado para lidar com 200,000 contextos de token. Mas, a partir de 5 de agosto, algumas solicitações estavam sendo roteadas para servidores configurados para 1 milhão de contextos de token.
Inicialmente, apenas 0.8% das solicitações foram afetadas. Nada demais, certo? Errado.
Em 29 de agosto, uma atualização de rotina do balanceador de carga transformou esse pequeno problema em um grande problema. De repente, no pico, 16% das solicitações do Sonnet 4 estavam indo para os servidores errados. E o roteamento estava "pegajoso". Uma vez que você era roteado incorretamente, você continuava sendo roteado incorretamente.
O impacto:
- Cerca de 30% dos usuários do Claude Code que estavam ativos durante a janela tiveram pelo menos uma solicitação roteada incorretamente
- Tempos de resposta reduzidos para usuários afetados
- O mesmo usuário experimentaria o problema repetidamente, enquanto outros não teriam problemas
Bug #2: O Gerador de Personagens Aleatórios
Em 25 de agosto, a Anthropic implantou uma configuração incorreta em seus servidores TPU. O resultado foi que Claude começou a inserir aleatoriamente caracteres tailandeses e chineses nas respostas em inglês.
Imagine pedir para Claude depurar seu código Python e receber isto:
def calculate_total(items):
total = 0
for item in items:
總計 += item.price # <- What?
return ผลรวม
Isso afetou:
- Opus 4.1 e Opus 4: 25 a 28 de agosto
- Soneto 4: 25 de agosto – 2 de setembro
A causa técnica foi um erro de geração de tokens que atribuiu alta probabilidade a caracteres que não deveriam estar ali. Isso literalmente quebrou o mecanismo fundamental de como Claude seleciona a próxima palavra a ser dita.
Bug #3: O Bug do Compilador Invisível
Este é o ponto assustador do ponto de vista da engenharia. Havia um bug latente no compilador XLA do Google que estava adormecido. Quando a Anthropic implementou o código para melhorar a seleção de tokens em 25 de agosto, eles o acionaram acidentalmente.
O que esse bug fez foi genuinamente bizarro: fez com que Claude excluísse involuntariamente o token mais provável ao gerar o texto. Claude sabia a resposta certa, mas estava fisicamente impedido de dizê-la.
A parte realmente complicada? Eles conseguiram contornar esse bug em dezembro de 2024 sem perceber. Quando "consertaram" o que pensavam ser a causa raiz em agosto, removeram a solução alternativa e revelaram o problema real.
Por que demorou seis semanas para consertar
Você deve estar se perguntando: como uma empresa como a Anthropic, com engenheiros de nível internacional, leva seis semanas para descobrir isso?
A resposta revela o quão complexos esses sistemas realmente são:
1. Controles de privacidade bloqueados Depuração
“Nossos controles internos de privacidade e segurança limitam como e quando os engenheiros podem acessar as interações do usuário com Claude, em particular quando essas interações não são relatadas a nós como feedback.”
Eles literalmente não conseguiam ver o que estava quebrando, a menos que os usuários relatassem explicitamente no feedback. Ótimo para privacidade, péssimo para depuração.
2. Os insetos se esconderam
Claude frequentemente se recuperava de erros individuais, fazendo com que a degradação parecesse uma variância normal em vez de uma falha sistemática. Seus benchmarks e avaliações não estavam detectando isso porque o modelo se autocorrigia apenas o suficiente para passar nos testes.
3. Caos multiplataforma
Claude roda no AWS Trainium, NVIDIA GPUs e TPUs do Google – três plataformas de hardware completamente diferentes. Cada bug se manifestou de forma diferente em cada plataforma:
- AWS Bedrock: 0.18% das solicitações do Sonnet 4 afetadas no pico
- Google Vertex AI: Abaixo de 0.0004% afetado
- API direta: até 16% afetados
Isso fez com que parecesse haver vários problemas não relacionados, em vez de três bugs específicos.
4. Sintomas sobrepostos
Com três bugs ativos simultaneamente, os sintomas eram muito variados. Um usuário podia receber caracteres tailandeses, outro podia receber respostas degradadas e um terceiro podia apresentar desempenho perfeito. Não havia um padrão claro a seguir.
O que isso realmente significa para a confiabilidade da IA
Toda essa saga revela algo crucial sobre o estado atual dos sistemas de IA: eles são muito mais frágeis do que parecem.
Não estamos falando apenas do modelo de IA em si. Estamos falando de:
- Infraestrutura de roteamento que pode enviar solicitações para o lugar errado
- Implementações específicas de hardware que se comportam de maneira diferente
- Erros do compilador que podem permanecer adormecidos por meses
- Balanceadores de carga que podem transformar pequenos problemas em grandes interrupções
Uma configuração incorreta, um bug do compilador, um erro de roteamento – e de repente seu assistente de IA esquece como codificar ou começa a falar línguas que não deveria.
Está realmente consertado?
A Anthropic afirma ter resolvido todos os três problemas até 16 de setembro. Eles têm:
- Corrigiu a lógica de roteamento
- Reverteu as configurações problemáticas
- Mudou de operações top-k aproximadas para exatas (tendo um impacto negativo no desempenho em termos de precisão)
- Monitoramento contínuo da produção adicionado
BUT os usuários ainda estão relatando problemasAlguns desenvolvedores afirmam que o Claude Code ainda parece degradado em comparação com seu desempenho anterior. Seja:
- Efeitos persistentes dos insetos
- Novos problemas que não foram identificados
- Viés psicológico após semanas de problemas
- Ou degradação contínua real
…ainda não sabemos.
Concluindo!
Esta situação é um estudo de caso perfeito de como sistemas complexos de IA podem falhar de maneiras completamente inesperadas. Três bugs distintos, todos acionados com semanas de diferença, criaram uma percepção de degradação massiva da qualidade que levou seis semanas para ser diagnosticada e corrigida.
Podemos dar algum crédito à Anthropic pela transparência. Publicar um relatório técnico detalhado sobre o assunto é mais do que a maioria das empresas faria. Mas também mostra o quanto pode dar errado nos bastidores desses sistemas nos quais confiamos cada vez mais.
Para quem está desenvolvendo com base no Claude ou em qualquer LLM: você precisa de redundância, validação e planos de backup. Porque, como acabamos de ver, mesmo os melhores sistemas de IA podem ter três problemas diferentes simultaneamente, e pode levar semanas até que alguém descubra o que realmente está acontecendo.
A infraestrutura que dá suporte a esses modelos de IA é tão importante quanto os próprios modelos. E, no momento, essa infraestrutura está apresentando sérias dificuldades de crescimento.












