Ângulo de Anderson
Criando uma Rede Adversária Generativa Personalizada com Esboços

Pesquisadores da Carnegie Mellon e do MIT desenvolveram uma nova metodologia que permite que um usuário crie sistemas de criação de imagens de Rede Adversária Generativa (GAN) personalizados simplesmente desenhando esboços indicativos.
Um sistema desse tipo poderia permitir que um usuário final criasse sistemas de geração de imagens capazes de gerar imagens muito específicas, como animais específicos, tipos de prédios – e até mesmo pessoas individuais. Atualmente, a maioria dos sistemas de geração de imagens GAN produz saídas amplas e fairly aleatórias, com pouca capacidade de especificar características particulares, como raça de animal, tipos de cabelo em pessoas, estilos de arquitetura ou identidades faciais reais.
A abordagem, descrita no artigo Desenhe seu próprio GAN, utiliza uma nova interface de desenho como uma função de “busca” eficaz para encontrar recursos e classes em bancos de dados de imagens que podem conter milhares de tipos de objetos, incluindo muitos subtipos que não são relevantes para a intenção do usuário. O GAN é então treinado nesse subconjunto de imagens.
Ao desenhar o tipo de objeto específico com o qual o usuário deseja calibrar o GAN, as capacidades gerativas da estrutura se tornam especializadas nessa classe. Por exemplo, se um usuário deseja criar uma estrutura que gere um tipo específico de gato (em vez de apenas um gato qualquer, como pode ser obtido com Este Gato Não Existe), os esboços de entrada servem como um filtro para descartar classes não relevantes de gato.

Fonte: https://peterwang512.github.io/GANSketching/
A pesquisa é liderada por Sheng Yu-Wang, da Universidade Carnegie Mellon, juntamente com o colega Jun-Yan Zhu e David Bau, do Laboratório de Ciência da Computação e Inteligência Artificial do MIT.
O método em si é chamado de “desenho GAN” e usa os esboços de entrada para alterar diretamente os pesos de um modelo GAN “template” para direcionar especificamente o domínio ou subdomínio identificado por meio de perda adversária entre domínios.
Diferentes métodos de regularização foram explorados para garantir que a saída do modelo seja diversa, mantendo uma alta qualidade de imagem. Os pesquisadores criaram aplicações de amostra que são capazes de interpololar o espaço latente e realizar procedimentos de edição de imagem.
Este [$class] Não Existe
Os sistemas de geração de imagens baseados em GAN se tornaram uma moda, se não um meme, nos últimos anos, com uma proliferação de projetos capazes de gerar imagens de coisas não existentes, incluindo pessoas, apartamentos para alugar, lanches, pés, cavalos, políticos e insetos, entre muitos outros.
Os sistemas de síntese de imagens baseados em GAN são criados compilando ou curando conjuntos de dados extensos que contenham imagens do domínio alvo, como faces ou cavalos; treinando modelos que generalizam uma variedade de recursos em todo o banco de dados; e implementando módulos geradores que possam produzir exemplos aleatórios com base nos recursos aprendidos.

Saída de esboços no DeepFacePencil, que permite que os usuários criem faces fotorealistas a partir de esboços. Muitos projetos semelhantes de esboço-para-imagem existem. Fonte: https://arxiv.org/pdf/2008.13343.pdf
Os recursos de alta dimensionalidade são os primeiros a serem concretizados durante o processo de treinamento e são equivalentes às primeiras pinceladas amplos de cor de um pintor em uma tela. Esses recursos de alta dimensionalidade eventualmente se correlacionarão com recursos mais detalhados (por exemplo, o brilho do olho e os bigodes afiados de um gato, em vez de apenas um blob bege genérico que representa a cabeça).
Eu Sei o que Você Quer Dizer…
Ao mapear a relação entre essas formas seminais iniciais e as interpretações detalhadas que são obtidas muito mais tarde no processo de treinamento, é possível inferir relações entre imagens “vagas” e “específicas”, permitindo que os usuários criem imagens complexas e fotorealistas a partir de esboços crus.
Recentemente, a NVIDIA lançou uma versão para desktop de sua pesquisa de longo prazo GauGAN sobre geração de paisagens baseada em GAN, que demonstra facilmente esse princípio:
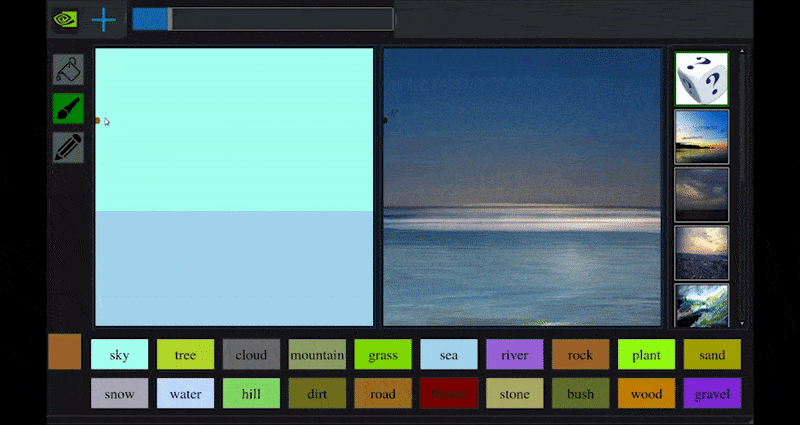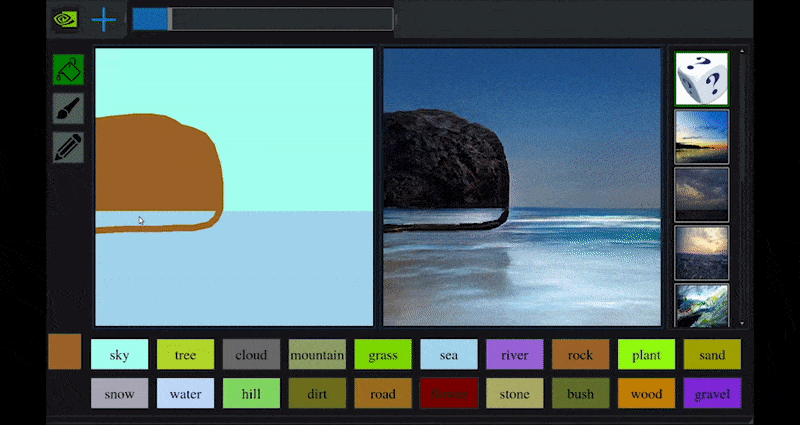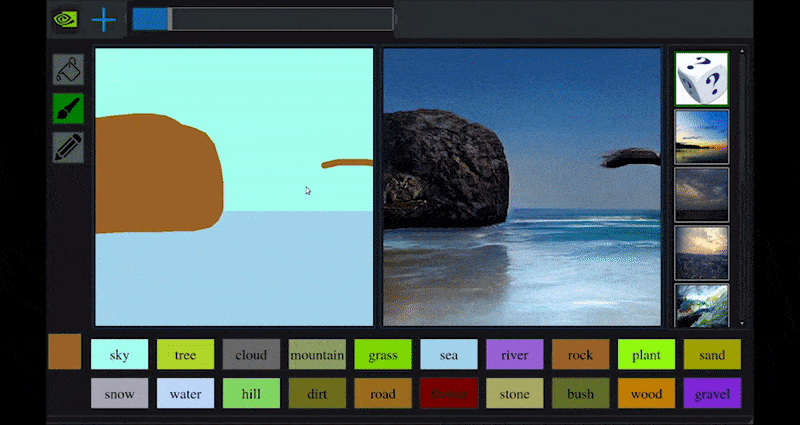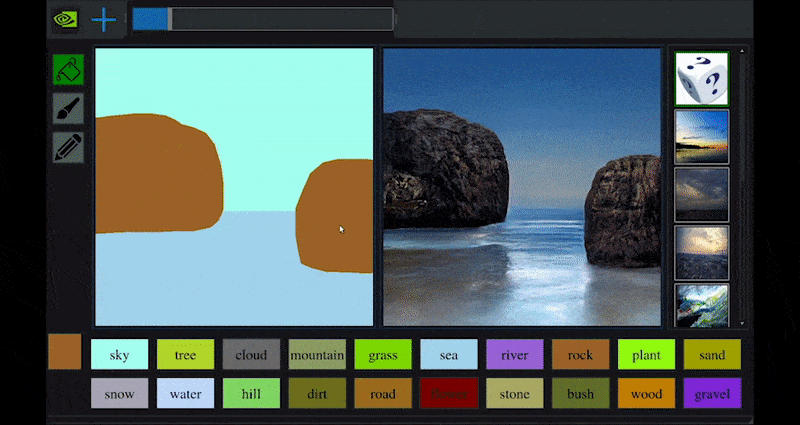
Pinceladas aproximadas são traduzidas em imagens cênicas ricas por meio do GauGAN da NVIDIA e agora do aplicativo NVIDIA Canvas. Fonte: https://rossdawson.com/futurist/implications-of-ai/future-of-ai-image-synthesis/
Da mesma forma, vários sistemas, como o DeepFacePencil, usaram o mesmo princípio para criar geradores de imagens induzidos por esboços para vários domínios.

A arquitetura do DeepFacePencil.
Simplificando Esboço-para-Imagem
A abordagem de “desenho GAN” do novo artigo busca remover a carga formidável de coleta e curadoria de dados que normalmente está envolvida no desenvolvimento de estruturas de imagem GAN, usando a entrada do usuário para definir qual subconjunto de imagens deve constituir os dados de treinamento.
O sistema foi projetado para exigir apenas um pequeno número de esboços de entrada para calibrar a estrutura. O sistema efetivamente reverte a funcionalidade do PhotoSketch, uma iniciativa de pesquisa conjunta de 2019 por pesquisadores da Carnegie Mellon, Adobe, Uber ATG e Argo AI, que é incorporada no novo trabalho. O PhotoSketch foi projetado para criar esboços artísticos a partir de imagens e já contém o mapeamento eficaz de relações de criação de imagens vagas-específicas.
Para a parte de geração do processo, o novo método modifica apenas os pesos do StyleGAN2. Como os dados de imagem sendo usados são apenas um subconjunto dos dados disponíveis, modificar apenas a rede de mapeamento obtém resultados desejáveis.
O método foi avaliado em vários subdomínios populares, incluindo equitação, igrejas e gatos.

O conjunto de dados LSUN da Universidade de Princeton de 2016 foi usado como o material principal a partir do qual derivar subdomínios alvo. Para estabelecer um sistema de mapeamento de esboços robusto para as excentricidades da entrada do usuário real, o sistema é treinado em imagens do conjunto de dados QuickDraw desenvolvido pela Microsoft entre 2021-2016.
Embora o mapeamento de esboços entre PhotoSketch e QuickDraw sejam bastante diferentes, os pesquisadores descobriram que sua estrutura tem sucesso em atravessar ambos com facilidade em poses relativamente simples, embora poses mais complicadas (como gatos deitados) sejam mais desafiadoras, enquanto a entrada do usuário abstrata (por exemplo, desenhos muito crus) também prejudica a qualidade dos resultados.

Espaço Latente e Edição de Imagem Natural
Os pesquisadores desenvolveram duas aplicações com base no trabalho principal: edição de espaço latente e edição de imagem. A edição de espaço latente oferece controles de usuário interpretáveis que são facilitados no momento do treinamento e permitem um amplo grau de variação, permanecendo fiel ao domínio alvo e agradavelmente consistente em variações.

Interpolação suave do espaço latente com os modelos personalizados do GAN Sketching.
O componente de edição de espaço latente foi alimentado pelo projeto GANSpace de 2020, uma iniciativa conjunta da Universidade Aalto, Adobe e NVIDIA.
Uma única imagem também pode ser alimentada no modelo personalizado, facilitando a edição de imagem natural. Nessa aplicação, uma única imagem é projetada no GAN personalizado, não apenas permitindo a edição direta, mas também preservando a edição de espaço latente de nível superior, se isso também foi usado.

Aqui, uma imagem real foi usada como entrada no GAN (modelo de gato), que edita a entrada para corresponder aos esboços submetidos. Isso permite a edição de imagem via esboço.
Embora configurável, o sistema não é projetado para funcionar em tempo real, pelo menos em termos de treinamento e calibração. Atualmente, o GAN Sketching exige 30.000 iterações de treinamento. O sistema também exige acesso aos dados de treinamento originais para o modelo original.
Em casos em que o conjunto de dados é de código aberto e tem uma licença que permite a cópia local, isso poderia ser acomodado incluindo os dados de origem em um pacote instalado localmente, embora isso ocuparia um espaço de disco considerável; ou acessando ou processando dados remotamente, via uma abordagem baseada em nuvem, o que introduz sobrecargas de rede e (no caso de processamento ocorrendo na nuvem) possíveis considerações de custo de computação.

Transformações de modelos FFHQ personalizados treinados em apenas 4 esboços humanos.












