Inteligência artificial
Andrew Ng Critica a Cultura de Sobreajuste em Aprendizado de Máquina
Andrew Ng, uma das vozes mais influentes em aprendizado de máquina nas últimas décadas, está atualmente expressando preocupações sobre a extensão com que o setor enfatiza inovações na arquitetura de modelos sobre os dados – e especificamente, a extensão com que permite que resultados “sobreajustados” sejam retratados como soluções generalizadas ou avanços.
Essas são críticas abrangentes à cultura atual de aprendizado de máquina, emanando de uma de suas autoridades mais altas, e têm implicações para a confiança em um setor atormentado por medos sobre um terceiro colapso da confiança empresarial no desenvolvimento de IA em um espaço de sessenta anos.
Ng, um professor da Universidade de Stanford, também é um dos fundadores da deeplearning.ai, e em março publicou uma missiva no site da organização que destilou um discurso recente dele em um par de recomendações centrais:
Primeiramente, que a comunidade de pesquisa deve parar de reclamar que a limpeza de dados representa 80% dos desafios em aprendizado de máquina, e começar a desenvolver metodologias e práticas de MLOps robustas.
Em segundo lugar, que deve se afastar das “vitórias fáceis” que podem ser obtidas ajustando excessivamente os dados a um modelo de aprendizado de máquina, para que ele funcione bem naquele modelo, mas falhe em generalizar ou produzir um modelo amplamente implantável.
Aceitando o Desafio da Arquitetura e Cura de Dados
“Minha visão”, Ng escreveu, “é que, se 80 por cento do nosso trabalho é preparação de dados, então garantir a qualidade dos dados é o trabalho importante de uma equipe de aprendizado de máquina.”
Ele continuou:
“Em vez de contar com engenheiros para encontrar a melhor maneira de melhorar um conjunto de dados, espero que possamos desenvolver ferramentas de MLOps que ajudem a tornar a construção de sistemas de IA, incluindo a construção de conjuntos de dados de alta qualidade, mais repetível e sistemática.
“MLOps é um campo nascente, e diferentes pessoas o definem de maneira diferente. Mas acho que o princípio organizador mais importante das equipes e ferramentas de MLOps deve ser garantir o fluxo consistente e de alta qualidade de dados em todas as etapas de um projeto. Isso ajudará muitos projetos a funcionar mais suavemente.”
Falando no Zoom em uma sessão de Q&A ao vivo no final de abril, Ng abordou a falta de aplicabilidade nos sistemas de análise de radiologia de aprendizado de máquina:
“Verificou-se que, quando coletamos dados do Hospital de Stanford, então treinamos e testamos em dados do mesmo hospital, de fato, podemos publicar artigos mostrando [os algoritmos] são comparáveis a radiologistas humanos em detectar certas condições.
“…[Quando] você leva esse mesmo modelo, esse mesmo sistema de IA, para um hospital mais antigo na rua, com uma máquina mais antiga, e o técnico usa um protocolo de imagem ligeiramente diferente, esse desvio de dados causa o desempenho do sistema de IA a degrada significativamente. Em contraste, qualquer radiologista humano pode caminhar até o hospital mais antigo e fazer muito bem.”
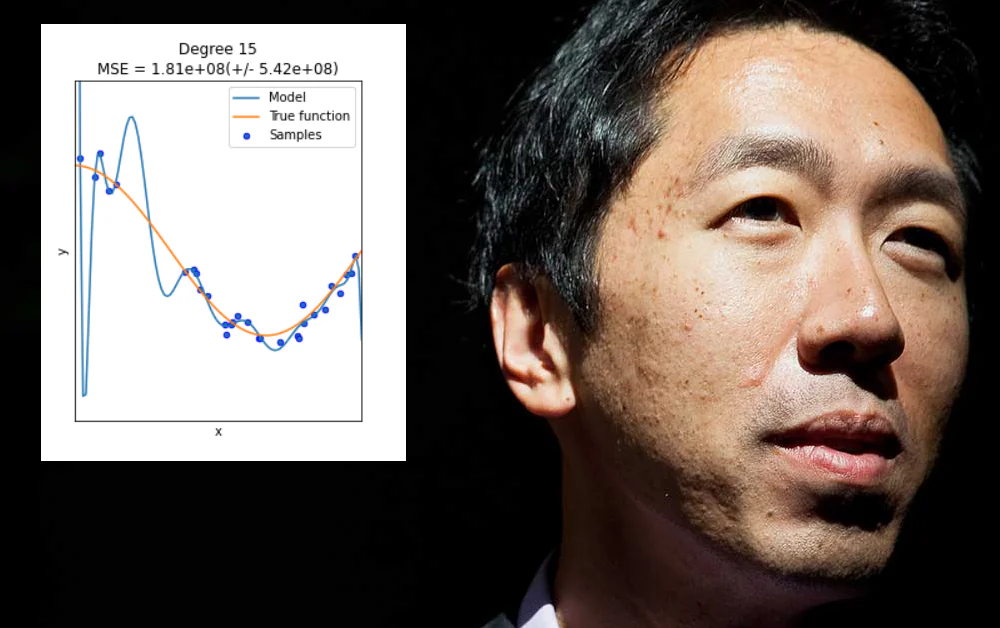
Subespecificação Não é uma Solução
Sobreajuste ocorre quando um modelo de aprendizado de máquina é projetado especificamente para acomodar as peculiaridades de um conjunto de dados particular (ou da forma como os dados são formatados). Isso pode envolver, por exemplo, especificar pesos que produzirão bons resultados a partir daquele conjunto de dados, mas não “generalizar” em outros dados.
Em muitos casos, esses parâmetros são definidos em “aspectos não de dados” do conjunto de treinamento, como a resolução específica das informações coletadas, ou outras peculiaridades que não são garantidas para ocorrer em conjuntos de dados subsequentes.
Embora fosse bom, o sobreajuste não é um problema que possa ser resolvido ampliando cegamente o escopo ou a flexibilidade da arquitetura de dados ou do design do modelo, quando o que realmente é necessário são recursos amplamente aplicáveis e altamente relevantes que funcionem bem em uma variedade de ambientes de dados – um desafio mais espinhoso.
Em geral, esse tipo de “subespecificação” leva apenas aos problemas que Ng recentemente delineou, onde um modelo de aprendizado de máquina falha em dados não vistos. A diferença, neste caso, é que o modelo está falhando não porque os dados ou o formato dos dados são diferentes do conjunto de treinamento original sobreajustado, mas porque o modelo é muito flexível em vez de muito frágil.
No final de 2020, o artigo Subespecificação Apresenta Desafios para a Credibilidade no Aprendizado de Máquina Moderno fez críticas intensas a essa prática, e levava os nomes de nada menos que quarenta pesquisadores e cientistas de aprendizado de máquina do Google e do MIT, entre outras instituições.
O artigo critica o “aprendizado de atalho” e observa a maneira como os modelos subespecificados podem partir em direções selvagens com base no ponto de inicialização aleatória no qual o treinamento do modelo começa. Os contribuintes observam:
‘Vimos que a subespecificação é onipresente em pipelines de aprendizado de máquina práticos em muitos domínios. De fato, graças à subespecificação, aspectos substantivamente importantes das decisões são determinados por escolhas arbitrárias, como a semente aleatória usada para a inicialização de parâmetros.’
Implicações Econômicas de Mudar a Cultura
Apesar de suas credenciais acadêmicas, Ng não é um acadêmico etéreo, mas tem experiência industrial profunda e de alto nível como co-fundador do Google Brain e do Coursera, como ex-cientista-chefe de Big Data e IA da Baidu, e como fundador da Landing AI, que administra $175 milhões de USD para novas startups no setor.
Quando ele diz “Todo o IA, não apenas a saúde, tem uma lacuna de conceito para produção”, é destinado a ser um chamado de alerta para um setor cujo nível atual de hype e história manchada o caracterizou cada vez mais como um investimento de negócios incerto de longo prazo, atormentado por problemas de definição e escopo.
No entanto, sistemas de aprendizado de máquina proprietários que funcionam bem in situ e falham em outros ambientes representam o tipo de captura de mercado que poderia recompensar o investimento industrial. Apresentar o “problema de sobreajuste” no contexto de um perigo ocupacional oferece uma maneira desonesta de monetizar o investimento corporativo em pesquisa de código aberto e produzir (efetivamente) sistemas proprietários onde a replicação por concorrentes é possível, mas problemática.
Se essa abordagem funcionaria a longo prazo depende da extensão com que os verdadeiros avanços em aprendizado de máquina continuem a exigir niveis cada vez maiores de investimento, e se todas as iniciativas produtivas inevitavelmente migrarão para a FAANG em algum grau, devido aos recursos colossais necessários para hospedagem e operações.












