Inteligência artificial
Adobe Research estende a edição de faces GAN desembaraçadas

Não é difícil entender por que emaranhamento é um problema na síntese de imagens, porque frequentemente é um problema em outras áreas da vida; por exemplo, é muito mais difícil remover a cúrcuma de um curry do que descartar o picles de um hambúrguer, e é praticamente impossível desdoçar uma xícara de café. Algumas coisas simplesmente vêm junto.
Da mesma forma, o emaranhamento é um obstáculo para arquiteturas de síntese de imagens que idealmente gostariam de separar diferentes recursos e conceitos ao usar o aprendizado de máquina para criar ou editar faces (ou cães, barcos, ou qualquer outro domínio).
Se você pudesse separar fios como idade, gênero, cor do cabelo, tom de pele, emoção, e assim por diante, você teria o início de uma real instrumentalidade e flexibilidade em uma estrutura que poderia criar e editar imagens de rosto em um nível verdadeiramente granular, sem arrastar 'passageiros' indesejados para essas conversões.

No emaranhamento máximo (acima à esquerda), tudo o que você pode fazer é alterar a imagem de uma rede GAN aprendida para a imagem de outra pessoa.
Isso é efetivamente usar a mais recente tecnologia de visão computacional de IA para alcançar algo que foi resolvido por outros meios mais de trinta anos atrás.
Com algum grau de separação ('Separação Média' na imagem anterior), é possível realizar alterações baseadas em estilo, como cor do cabelo, expressão, aplicação cosmética e rotação limitada da cabeça, entre outros.

Fonte: FEAT: Edição de rosto com atenção, fevereiro de 2022, https://arxiv.org/pdf/2202.02713.pdf
Houve uma série de tentativas nos últimos dois anos para criar ambientes interativos de edição facial que permitem ao usuário alterar as características faciais com controles deslizantes e outras interações tradicionais da interface do usuário, mantendo intactos os principais recursos do rosto alvo ao fazer adições ou alterações. No entanto, isso provou ser um desafio devido ao emaranhado subjacente de recurso/estilo no espaço latente do GAN.
Por exemplo, a óculos A característica é freqüentemente confundida com o idade característica, o que significa que adicionar óculos também pode "envelhecer" o rosto, enquanto envelhecer o rosto pode adicionar óculos, dependendo do grau de separação aplicada de características de alto nível (veja "Testes" abaixo para exemplos).
Mais notavelmente, tem sido quase impossível alterar a cor do cabelo e outras facetas capilares sem que os fios e a disposição sejam recalculados, o que dá um efeito de transição "brilhante".

Fonte: InterFaceGAN Demo (CVPR 2020), https://www.youtube.com/watch?v=uoftpl3Bj6w
Latente para Latente GAN Traversal
Um novo papel liderado pela Adobe entrou para WACV 2022 oferece uma nova abordagem para essas questões subjacentes em um papel intitulado Latente para latente: um mapeador experiente para edição de preservação de identidade de vários atributos faciais em imagens geradas pelo StyleGAN.

Material suplementar do papel Latente para latente: um mapeador experiente para edição de preservação de identidade de vários atributos faciais em imagens geradas pelo StyleGAN. Aqui vemos que as características básicas na face aprendida não são arrastadas para mudanças não relacionadas. Veja o vídeo completo incorporado no final do artigo para obter melhores detalhes e resolução. Fonte: https://www.youtube.com/watch?v=rf_61llRH0Q
O artigo é liderado pelo cientista aplicado da Adobe, Siavash Khodadadeh, juntamente com outros quatro pesquisadores da Adobe e um pesquisador do Departamento de Ciência da Computação da Universidade da Flórida Central.
O artigo é interessante, em parte, porque a Adobe atua nesse espaço há algum tempo, e é tentador imaginar essa funcionalidade entrando em um projeto do Creative Suite nos próximos anos; mas principalmente porque a arquitetura criada para o projeto adota uma abordagem diferente para manter a integridade visual em um editor de rosto GAN enquanto as alterações estão sendo aplicadas.
Os autores declaram:
'[Nós] treinamos uma rede neural para realizar uma transformação latente em latente que encontra a codificação latente correspondente à imagem com o atributo alterado. Como a técnica é one-shot, ela não depende de uma trajetória linear ou não linear da mudança gradual dos atributos.
'Ao treinar a rede de ponta a ponta em todo o pipeline de geração, o sistema pode se adaptar aos espaços latentes das arquiteturas de geradores disponíveis no mercado. Propriedades de conservação, como manter a identidade da pessoa, podem ser codificadas na forma de perdas de treinamento.
'Depois que a rede latente-latente for treinada, ela pode ser reutilizada para imagens arbitrárias sem retreinamento.'
Esta última parte significa que a arquitetura proposta chega ao usuário final em um estado finalizado. Ela ainda precisa executar uma rede neural em recursos locais, mas novas imagens podem ser "inseridas" e estar prontas para alteração quase imediatamente, já que a estrutura é desacoplada o suficiente para não precisar de treinamento adicional específico para cada imagem.
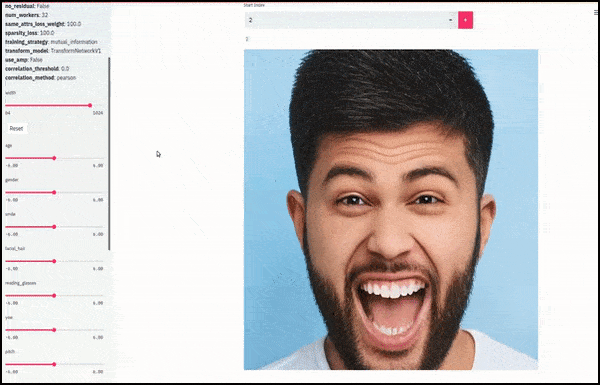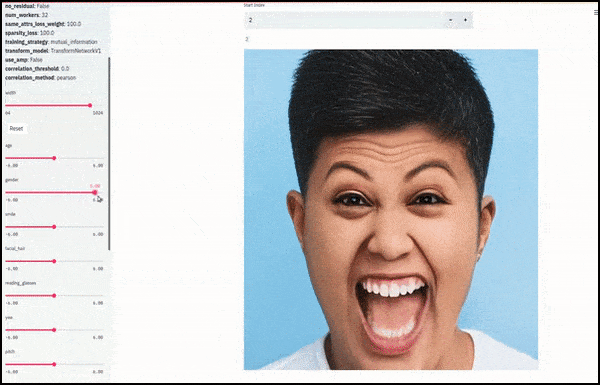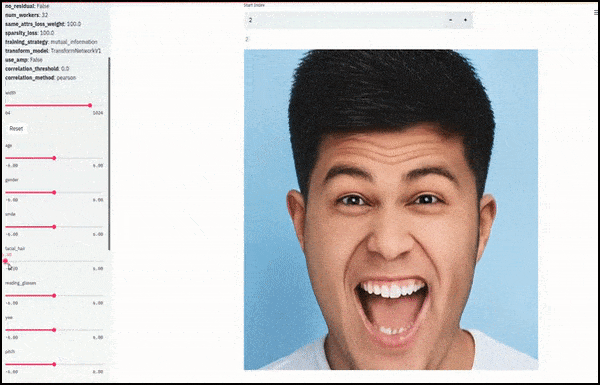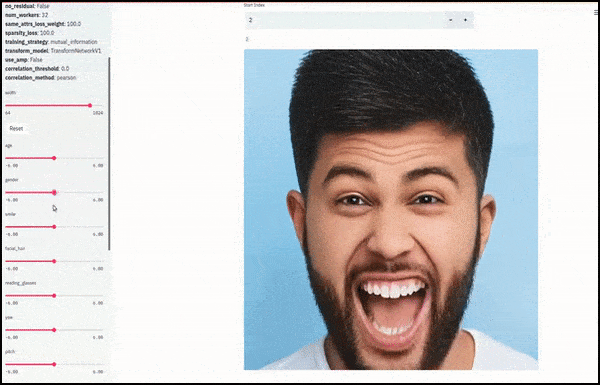
Gênero e pelos faciais mudaram conforme os controles deslizantes traçam caminhos aleatórios e arbitrários pelo espaço latente, não apenas "deslizando entre os pontos finais". Veja o vídeo incorporado no final do artigo para mais transformações em melhor resolução.
Entre as principais conquistas do trabalho está a capacidade da rede de 'congelar' identidades no espaço latente, alterando apenas o atributo em um vetor alvo, e fornecendo 'termos de correção' que conservam as identidades sendo transformadas.
Essencialmente, a rede proposta está inserida em uma arquitetura mais ampla que orquestra todos os elementos processados, que passam por componentes pré-treinados com pesos congelados que não produzirão efeitos laterais indesejados nas transformações.
Como o processo de treinamento depende trigêmeos que pode ser gerado por uma imagem de semente (sob inversão GAN) ou uma codificação latente inicial existente, todo o processo de treinamento não é supervisionado, com as ações tácitas da gama habitual de sistemas de rotulagem e curadoria em tais sistemas efetivamente embutidos na arquitetura. Na verdade, o novo sistema usa regressores de atributos disponíveis no mercado:
"[O] número de atributos que nossa rede pode controlar independentemente é limitado apenas pelas capacidades do(s) reconhecedor(es) – se alguém tiver um reconhecedor para um atributo, podemos adicioná-lo a rostos arbitrários. Em nossos experimentos, treinamos a rede latente-latente para permitir o ajuste de 35 atributos faciais diferentes, mais do que qualquer abordagem anterior."
O sistema incorpora uma proteção adicional contra transformações de 'efeitos colaterais' indesejadas: na ausência de uma solicitação de alteração de atributo, a rede latente para latente mapeará um vetor latente para si mesma, aumentando ainda mais a persistência estável da identidade de destino.
Reconhecimento facial
Um problema recorrente com GAN e editores de face baseados em codificador/decodificador dos últimos anos é que as transformações aplicadas tendem a degradar a semelhança. Para combater isso, o projeto da Adobe usa uma rede de reconhecimento facial incorporada chamada FaceNet como discriminador.

Arquitetura do projeto, veja no canto inferior esquerdo para inclusão do FaceNet. Fonte: Latente para latente: um mapeador experiente para edição de preservação de identidade de vários atributos faciais em imagens geradas pelo StyleGAN, Acesso livre.
(Em uma nota pessoal, isso parece um movimento encorajador em direção à integração de identificação facial padrão e até sistemas de reconhecimento de expressão em redes generativas, sem dúvida o melhor caminho a seguir para superar o pixel cego>mapeamento de pixel que domina as arquiteturas deepfake atuais em detrimento da fidelidade de expressão e outros domínios importantes no setor de geração de face.)
Acessar todas as áreas no Espaço Latente
Outra característica impressionante do framework é sua capacidade de transitar arbitrariamente entre transformações potenciais no espaço latente, conforme a vontade do usuário. Vários sistemas anteriores que ofereciam interfaces exploratórias frequentemente deixavam o usuário essencialmente "navegando" entre cronogramas fixos de transformação de recursos – uma experiência impressionante, mas frequentemente bastante linear ou proscritiva.

Desde Melhorando o equilíbrio de GAN aumentando a consciência espacial: aqui o usuário percorre uma gama de pontos de transição potenciais entre dois locais do espaço latente, mas dentro dos limites de locais pré-treinados no espaço latente. Para aplicar outros tipos de transformação com base no mesmo material, é necessária a reconfiguração e/ou retreinamento. Fonte: https://genforce.github.io/eqgan/
Além de ser receptivo a imagens totalmente novas, o usuário também pode "congelar" manualmente os elementos que deseja conservar durante o processo de transformação. Dessa forma, o usuário pode garantir que (por exemplo) os fundos não se movam ou que os olhos permaneçam abertos ou fechados.
Dados
A rede de regressão de atributos foi treinada em três redes: FFHQ, CelebAMask-HQ, e uma rede local gerada por GAN obtida pela amostragem de 400,000 vetores do espaço Z de EstiloGAN-V2.
As imagens fora de distribuição (OOD) foram filtradas e os atributos extraídos usando o Microsoft API de rosto, com a divisão resultante do conjunto de imagens 90/10, deixando 721,218 imagens de treinamento e 72,172 imagens de teste para comparação.
Testes
Embora a rede experimental tenha sido inicialmente configurada para acomodar 35 transformações potenciais, elas foram reduzidas para oito, a fim de realizar testes análogos em estruturas comparáveis. InterFaceGAN, GANSpace e Fluxo de estilo.
Os oito atributos selecionados foram Idade, calvície, Barba, Expressão, Gênero, Óculos, Passo e Guinada. Foi necessário reequipar as estruturas concorrentes para alguns dos oito atributos que não foram fornecidos na distribuição original, como adicionar calvície e ferrolhos de sobrepor podem ser usados para proteger uma porta de embutir pelo lado de fora. Alguns kits de corrente de segurança também permitem travamento externo com chave ou botão giratório. barba para InterFaceGAN.
Como esperado, um maior nível de emaranhamento ocorreu nas arquiteturas rivais. Por exemplo, em um teste, o InterFaceGAN e o StyleFlow alteraram o gênero do sujeito quando solicitado a se inscrever idade:

Duas das estruturas concorrentes incluíram uma mudança de gênero na transformação de "idade", alterando também a cor do cabelo sem solicitação direta do usuário.
Além disso, dois dos rivais descobriram que óculos e idade são facetas inseparáveis:

Óculos e mudança de cor de cabelo sem nenhum custo extra!
Não é uma vitória uniforme para a pesquisa: como pode ser visto no vídeo que acompanha o artigo, a estrutura é a menos eficaz ao tentar extrapolar ângulos diversos (guinada), enquanto o GANSpace tem um resultado geral melhor para idade e a imposição de óculos. A estrutura latente para latente empatou com GANSpace e StyleFlow em relação à adição de pitch (ângulo da cabeça).

Resultados calculados com base em uma calibração do Detector facial MTCNN. Resultados mais baixos são melhores.
Para mais detalhes e melhor resolução dos exemplos, confira o vídeo que acompanha o artigo abaixo.
Publicado pela primeira vez em 16 de fevereiro de 2022.












