
Artificial Intelligence
GPT-4o OpenAI: multimodalny model sztucznej inteligencji przekształcający interakcję człowiek-maszyna

OpenAI wypuściło swój najnowszy i najbardziej zaawansowany model językowy w historii – GPT-4o, znany również jako „Omni" Model. Ten rewolucyjny system sztucznej inteligencji stanowi ogromny krok naprzód, a jego możliwości zacierają granicę między ludzką a sztuczną inteligencją.
Sercem GPT-4o jest jego natywna multimodalność, pozwalająca na płynne przetwarzanie i generowanie treści w postaci tekstu, dźwięku, obrazów i wideo. Ta integracja wielu modalności w jeden model jest pierwszą w swoim rodzaju i obiecującą zmianę sposobu, w jaki współpracujemy z asystentami AI.
Ale GPT-4o to znacznie więcej niż tylko system multimodalny. Charakteryzuje się on oszałamiającą poprawą wydajności w porównaniu ze swoim poprzednikiem, GPT-4, i pozostawia w tyle konkurencyjne modele, takie jak Gemini 1.5 Pro, Claude 3 i Llama 3-70B. Przyjrzyjmy się bliżej temu, co czyni ten model sztucznej inteligencji prawdziwie przełomowym.
Niezrównana wydajność i efektywność
Jednym z najbardziej imponujących aspektów GPT-4o są jego bezprecedensowe możliwości wydajnościowe. Według ocen OpenAI, model ten ma imponującą przewagę 60 punktów ELO nad poprzednim liderem, GPT-4 Turbo. Ta znacząca przewaga stawia GPT-4o w lidze samej w sobie, przewyższając nawet najbardziej zaawansowane modele AI dostępne obecnie na rynku.
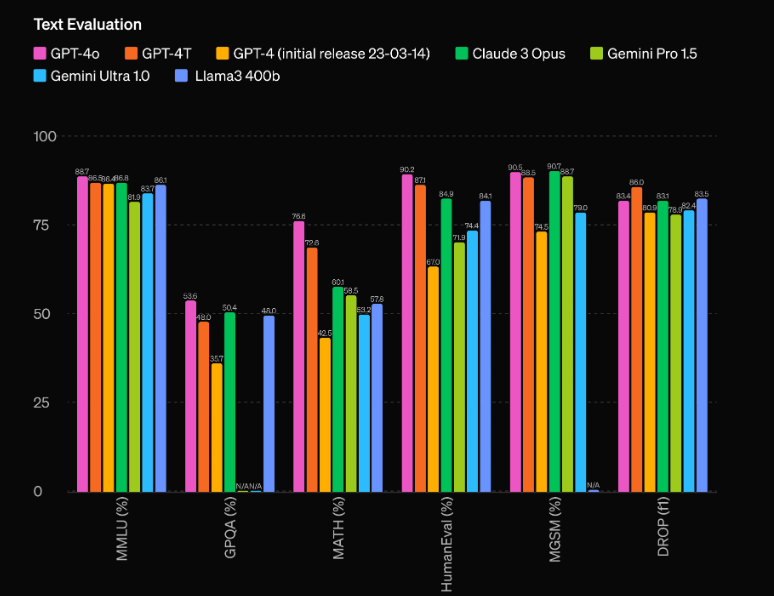
Ale sama wydajność to nie jedyny obszar, w którym GPT-4o błyszczy. Model ten charakteryzuje się również imponującą wydajnością, działając z dwukrotnie większą prędkością niż GPT-4 Turbo, a jego koszt eksploatacji jest o połowę niższy. To połączenie doskonałej wydajności i opłacalności sprawia, że GPT-4o jest niezwykle atrakcyjną propozycją dla deweloperów i firm, które chcą zintegrować najnowocześniejsze możliwości sztucznej inteligencji ze swoimi aplikacjami.
Możliwości multimodalne: łączenie tekstu, dźwięku i obrazu
Być może najbardziej przełomowym aspektem GPT-4o jest jego natywna multimodalność, która pozwala na płynne przetwarzanie i generowanie treści w wielu modalnościach, w tym w tekście, dźwięku i obrazie. Ta integracja wielu modalności w jeden model jest nowością tego rodzaju i może zrewolucjonizować sposób interakcji z asystentami AI.
Dzięki GPT-4o użytkownicy mogą prowadzić naturalne rozmowy w czasie rzeczywistym, posługując się mową, a model natychmiast rozpoznaje i reaguje na sygnały audio. Ale możliwości na tym się nie kończą – GPT-4o może również interpretować i generować treści wizualne, otwierając świat możliwości dla aplikacji, od analizy i generowania obrazu po rozumienie i tworzenie wideo.
Jednym z najbardziej imponujących przykładów multimodalnych możliwości GPT-4o jest jego zdolność do analizy sceny lub obrazu w czasie rzeczywistym, precyzyjnego opisywania i interpretowania postrzeganych elementów wizualnych. Ta funkcja ma ogromne znaczenie dla zastosowań takich jak technologie wspomagające dla osób niedowidzących, a także w takich dziedzinach jak bezpieczeństwo, monitoring i automatyzacja.
Jednak multimodalne możliwości GPT-4o wykraczają poza samo rozumienie i generowanie treści w różnych modalnościach. Model ten potrafi również płynnie łączyć te modalności, tworząc prawdziwie wciągające i angażujące doświadczenia. Na przykład, podczas demonstracji na żywo OpenAI, GPT-4o był w stanie wygenerować utwór na podstawie warunków wejściowych, łącząc swoją wiedzę z zakresu języka, teorii muzyki i generowania dźwięku w spójny i imponujący wynik.
Używanie GPT0 przy użyciu Pythona
import openai
# Replace with your actual API key
OPENAI_API_KEY = "your_openai_api_key_here"
# Function to extract the response content
def get_response_content(response_dict, exclude_tokens=None):
if exclude_tokens is None:
exclude_tokens = []
if response_dict and response_dict.get("choices") and len(response_dict["choices"]) > 0:
content = response_dict["choices"][0]["message"]["content"].strip()
if content:
for token in exclude_tokens:
content = content.replace(token, '')
return content
raise ValueError(f"Unable to resolve response: {response_dict}")
# Asynchronous function to send a request to the OpenAI chat API
async def send_openai_chat_request(prompt, model_name, temperature=0.0):
openai.api_key = OPENAI_API_KEY
message = {"role": "user", "content": prompt}
response = await openai.ChatCompletion.acreate(
model=model_name,
messages=[message],
temperature=temperature,
)
return get_response_content(response)
# Example usage
async def main():
prompt = "Hello!"
model_name = "gpt-4o-2024-05-13"
response = await send_openai_chat_request(prompt, model_name)
print(response)
if __name__ == "__main__":
import asyncio
asyncio.run(main())
Mam:
- Zaimportowano moduł openai bezpośrednio zamiast używać klasy niestandardowej.
- Zmieniono nazwę funkcji openai_chat_resolve na get_response_content i wprowadzono kilka drobnych zmian w jej implementacji.
- Zastąpiono klasę AsyncOpenAI funkcją openai.ChatCompletion.acreate, która jest oficjalną metodą asynchroniczną udostępnianą przez bibliotekę OpenAI Python.
- Dodano przykładową funkcję główną, która pokazuje, jak używać funkcji send_openai_chat_request.
Pamiętaj, że aby kod działał poprawnie, musisz zastąpić „your_openai_api_key_here” rzeczywistym kluczem OpenAI API.














