Artificial Intelligence
Jak trenować i używać modeli Hunyuan Video LoRA

W tym artykule dowiesz się, jak zainstalować i używać oprogramowania opartego na systemie Windows, które może szkolić Hunyuan wideo LoRA modele, umożliwiając użytkownikowi generowanie niestandardowych osobowości w modelu fundacji Hunyuan Video:
Kliknij aby zagrać. Przykłady z niedawnego wzrostu popularności celebrytów Hunyuan LoRA ze społeczności civit.ai.
W tej chwili istnieją dwie najpopularniejsze metody lokalnego generowania modeli Hunyuan LoRA:
1) diffusion-pipe-ui Struktura oparta na Dockerze, który polega na Podsystem Windows dla systemu Linux (WSL) do obsługi niektórych procesów.
2) Stroik Musubi, nowy dodatek do popularnego Kohya ss architektura szkolenia dyfuzyjnego. Musubi Tuner nie wymaga Dockera i nie zależy od WSL ani innych serwerów proxy opartych na Linuksie – ale może być trudno uruchomić go w systemie Windows.
Dlatego też niniejszy test skupi się na Musubi Tuner i na dostarczeniu całkowicie lokalnego rozwiązania do trenowania i generowania Hunyuan LoRA, bez korzystania ze stron internetowych opartych na API lub komercyjnych procesów wynajmu GPU, takich jak Runpod.
Kliknij aby zagrać. Próbki z treningu LoRA na Musubi Tuner do tego artykułu. Wszystkie uprawnienia udzielone przez osobę przedstawioną, w celu zilustrowania tego artykułu.
WYMAGANIA
Instalacja będzie wymagać co najmniej komputera z systemem Windows 10 i kartą NVIDIA serii 30+/40+, która ma co najmniej 12 GB pamięci VRAM (choć zaleca się 16 GB). Instalacja użyta w tym artykule została przetestowana na komputerze z 64 GB pamięci system RAM i karta graficzna NVIDIA 3090 z 24 GB pamięci VRAM. Testowano na dedykowanym systemie testowym przy użyciu świeżej instalacji systemu Windows 10 Professional, na partycji z 600+ GB wolnego miejsca na dysku.
OSTRZEŻENIE
Instalacja Musubi Tuner i jego wymagań wstępnych obejmuje również instalację oprogramowania i pakietów przeznaczonych dla deweloperów bezpośrednio na głównej instalacji systemu Windows na komputerze. Biorąc pod uwagę instalację ComfyUI, na końcowych etapach projekt ten będzie wymagał około 400-500 gigabajtów miejsca na dysku. Chociaż testowałem tę procedurę bez żadnych incydentów kilka razy w nowo zainstalowanych środowiskach testowych Windows 10, ani ja, ani unite.ai nie ponosimy odpowiedzialności za jakiekolwiek uszkodzenia systemów spowodowane przestrzeganiem tych instrukcji. Radzę wykonać kopię zapasową wszelkich ważnych danych przed podjęciem próby wykonania tego rodzaju procedury instalacyjnej.
rozważania
Czy ta metoda jest nadal aktualna?
Rynek generatywnej sztucznej inteligencji rozwija się bardzo dynamicznie i w tym roku możemy spodziewać się lepszych i bardziej usprawnionych metod tworzenia frameworków Hunyuan Video LoRA.
…lub nawet w tym tygodniu! Podczas gdy pisałem ten artykuł, twórca Kohya/Musubi wyprodukował musubi-tuner-gui, wyrafinowany interfejs graficzny Gradio dla Musubi Tuner:

Oczywiście przyjazny użytkownikowi GUI jest lepszy od plików BAT, których używam w tej funkcji – gdy tylko musubi-tuner-gui zacznie działać. Podczas gdy to piszę, pojawił się on online zaledwie pięć dni temu i nie mogę znaleźć żadnego wpisu o tym, że ktoś z powodzeniem go używa.
Zgodnie z wpisami w repozytorium, nowy interfejs graficzny ma zostać jak najszybciej wdrożony bezpośrednio do projektu Musubi Tuner, co oznaczałoby zakończenie jego obecnej egzystencji jako samodzielnego repozytorium GitHub.
Na podstawie obecnych instrukcji instalacji, nowy GUI jest klonowany bezpośrednio do istniejącego środowiska wirtualnego Musubi; i pomimo wielu wysiłków nie mogę go skojarzyć z istniejącą instalacją Musubi. Oznacza to, że po uruchomieniu okaże się, że nie ma silnika!
Gdy GUI zostanie zintegrowane z Musubi Tuner, problemy tego typu z pewnością zostaną rozwiązane. Chociaż autor przyznaje, że nowy projekt jest „naprawdę trudny”jest optymistą co do jego rozwoju i bezpośredniej integracji z Musubi Tuner.
Biorąc pod uwagę te problemy (dotyczące również domyślnych ścieżek w czasie instalacji i korzystania z Pakiet UV Python, co komplikuje pewne procedury w nowej wersji), prawdopodobnie będziemy musieli trochę poczekać na płynniejsze doświadczenie szkoleniowe Hunyuan Video LoRA. Mimo to wygląda to bardzo obiecująco!
Jeśli jednak nie możesz czekać i jesteś w stanie zakasać rękawy, możesz już teraz uruchomić lokalnie szkolenie wideo Hunyuan dotyczące standardu LoRA.
Zacznijmy.
Dlaczego warto zainstalować Wszystko na gołym metalu?
(Pomiń ten akapit, jeśli nie jesteś zaawansowanym użytkownikiem)
Zaawansowani użytkownicy będą się zastanawiać, dlaczego zdecydowałem się zainstalować tak wiele oprogramowania na gołej instalacji Windows 10 zamiast w środowisku wirtualnym. Powodem jest to, że podstawowy port Windows oparty na systemie Linux Pakiet Triton jest o wiele trudniejszy do uruchomienia w środowisku wirtualnym. Wszystkie inne instalacje bare-metal w samouczku nie mogły zostać zainstalowane w środowisku wirtualnym, ponieważ muszą one komunikować się bezpośrednio z lokalnym sprzętem.
Instalowanie pakietów i programów wymaganych wstępnie
W przypadku programów i pakietów, które muszą zostać zainstalowane na początku, kolejność instalacji ma znaczenie. Zaczynajmy.
1: Pobierz pakiet redystrybucyjny firmy Microsoft
Pobierz i zainstaluj pakiet Microsoft Redistributable ze strony https://aka.ms/vs/17/release/vc_redist.x64.exe.
Jest to prosta i szybka instalacja.

2: Zainstaluj program Visual Studio 2022
Pobierz wersję Microsoft Visual Studio 2022 Community z https://visualstudio.microsoft.com/downloads/?cid=learn-onpage-download-install-visual-studio-page-cta
Uruchom pobrany instalator:

Nie potrzebujemy każdego dostępnego pakietu, co byłoby ciężką i długą instalacją. Na początku Obciążenia strona, która się otwiera, zaznacz Rozwój pulpitu za pomocą C++ (patrz zdjęcie poniżej).

Teraz kliknij Poszczególne komponenty w lewym górnym rogu interfejsu i użyj pola wyszukiwania, aby znaleźć „Windows SDK”.

Domyślnie tylko Zestaw Windows 11 SDK jest zaznaczone. Jeśli korzystasz z systemu Windows 10 (ta procedura instalacji nie została przeze mnie przetestowana w systemie Windows 11), zaznacz najnowszą wersję systemu Windows 10, wskazaną na powyższym obrazku.
Wyszukaj „C++ CMake” i sprawdź, czy Narzędzia C++ CMake dla systemu Windows sprawdzone.

Ta instalacja zajmie co najmniej 13 GB miejsca.

Po zainstalowaniu programu Visual Studio, program spróbuje uruchomić się na komputerze. Pozwól mu się otworzyć w pełni. Gdy interfejs pełnoekranowy programu Visual Studio będzie wreszcie widoczny, zamknij program.
3: Zainstaluj program Visual Studio 2019
Niektóre z kolejnych pakietów dla Musubi oczekują starszej wersji Microsoft Visual Studio, podczas gdy inne wymagają nowszej.
Dlatego pobierz także bezpłatną wersję Community programu Visual Studio 19 ze strony firmy Microsoft (https://visualstudio.microsoft.com/vs/older-downloads/ – wymagane konto) lub Techspot (https://www.techspot.com/downloads/7241-visual-studio-2019.html).
Zainstaluj go z tymi samymi opcjami, co w przypadku programu Visual Studio 2022 (patrz procedura powyżej, z tym wyjątkiem, że Zestaw SDK systemu Windows jest już zaznaczone w instalatorze programu Visual Studio 2019).
Zobaczysz, że instalator programu Visual Studio 2019 już rozpoznaje nowszą wersję podczas instalacji:

Po zakończeniu instalacji i otwarciu i zamknięciu zainstalowanej aplikacji Visual Studio 2019 otwórz wiersz polecenia systemu Windows (wpisz CMD w polu Rozpocznij wyszukiwanie) i wpisz:
where cl
Wynikiem powinny być znane lokalizacje dwóch zainstalowanych edycji programu Visual Studio.

Jeśli zamiast tego otrzymasz INFO: Could not find files for the given pattern(s), Patrz Sprawdź ścieżkę poniżej tego artykułu i użyj tych instrukcji, aby dodać odpowiednie ścieżki programu Visual Studio do środowiska Windows.
Zapisz wszelkie zmiany wprowadzone zgodnie z Sprawdź ścieżki poniżej, a następnie spróbuj ponownie uruchomić polecenie where cl.
4: Zainstaluj zestawy narzędzi CUDA 11 + 12
Różne pakiety zainstalowane w Musubi wymagają różnych wersji NVIDIA CUDA, który przyspiesza i optymalizuje szkolenie na kartach graficznych NVIDIA.
Powód, dla którego zainstalowaliśmy wersje Visual Studio drugim polega na tym, że instalatory NVIDIA CUDA wyszukują i integrują się z dowolnymi istniejącymi instalacjami programu Visual Studio.
Pobierz pakiet instalacyjny CUDA serii 11+ z:
https://developer.nvidia.com/cuda-11-8-0-download-archive?target_os=Windows&target_arch=x86_64&target_version=11&target_type=exe_local (Ściągnij 'exe (lokalny') )
Pobierz pakiet instalacyjny CUDA Toolkit serii 12+ z:
https://developer.nvidia.com/cuda-downloads?target_os=Windows&target_arch=x86_64
Proces instalacji jest identyczny dla obu instalatorów. Zignoruj wszelkie ostrzeżenia dotyczące istnienia lub braku ścieżek instalacyjnych w zmiennych środowiskowych systemu Windows – zajmiemy się tym ręcznie później.
Zainstaluj NVIDIA CUDA Toolkit V11+
Uruchom instalator pakietu narzędzi CUDA Toolkit serii 11+.


At Opcje instalacjiwybierz Niestandardowy (zaawansowany) i kontynuuj.

Odznacz opcję NVIDIA GeForce Experience i kliknij Następna.

Opuść Wybierz lokalizację instalacji przy ustawieniach domyślnych (to jest ważne):

Kliknij Następna i pozwól na zakończenie instalacji.

Zignoruj wszelkie ostrzeżenia i uwagi instalatora dotyczące Nsight Visual Studio integracja, która nie jest potrzebna w naszym przypadku.
Zainstaluj NVIDIA CUDA Toolkit V12+
Powtórz cały proces dla oddzielnego instalatora 12+ NVIDIA Toolkit, który pobrałeś:

Proces instalacji tej wersji jest identyczny z tym opisanym powyżej (wersja 11+), z wyjątkiem jednego ostrzeżenia dotyczącego ścieżek środowiskowych, które można zignorować:

Po zakończeniu instalacji wersji CUDA 12+ otwórz wiersz poleceń w systemie Windows i wpisz:
nvcc --version
Powinno to potwierdzić informacje o zainstalowanej wersji sterownika:

Aby sprawdzić czy Twoja karta została rozpoznana wpisz i zatwierdź:
nvidia-smi

5: Zainstaluj GIT
GIT zajmie się instalacją repozytorium Musubi na Twoim komputerze lokalnym. Pobierz instalator GIT pod adresem:
https://git-scm.com/downloads/win („Instalator 64-bitowego Git dla systemu Windows”)

Uruchom instalator:

Użyj ustawień domyślnych dla Wybierz Komponenty:
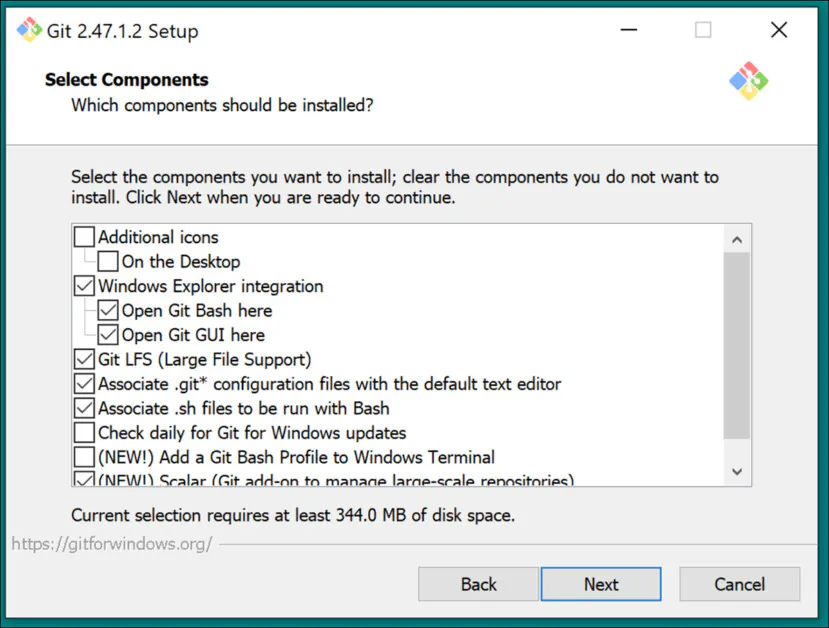
Pozostaw domyślny edytor Vim:

Pozwól GIT-owi decydować o nazwach gałęzi:

Użyj zalecanych ustawień dla ścieżka Środowisko:

Użyj zalecanych ustawień dla SSH:

Użyj zalecanych ustawień dla Zaplecze transportowe HTTPS:
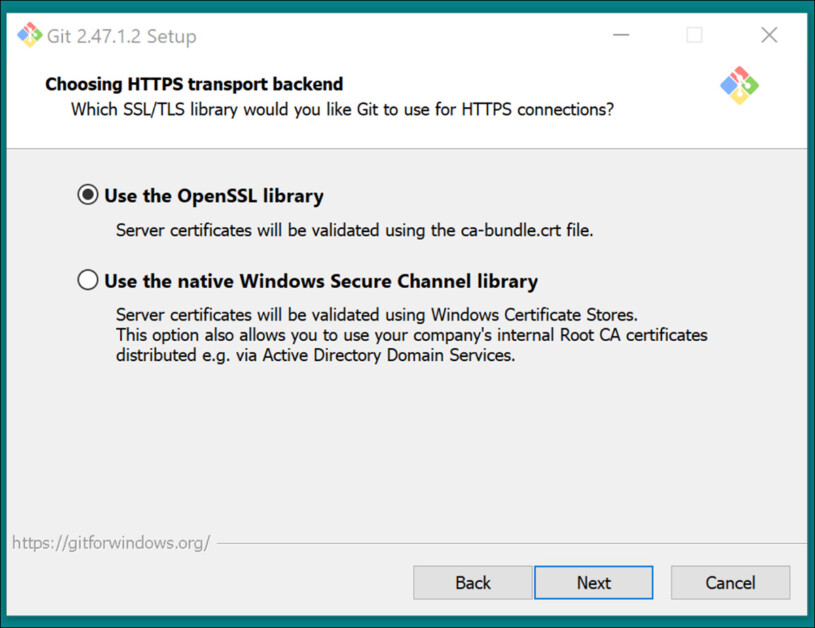
Użyj zalecanych ustawień dla konwersji zakończeń wierszy:

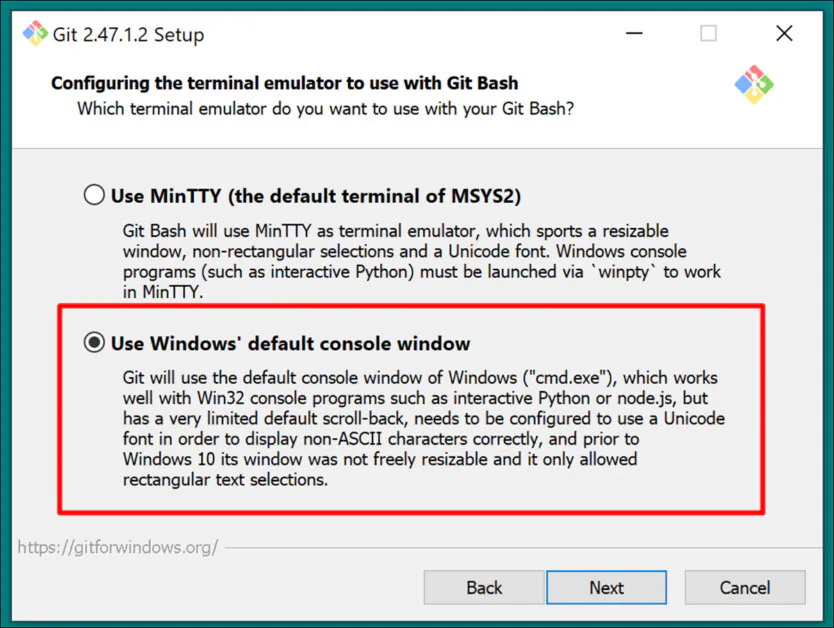
Wybierz domyślną konsolę systemu Windows jako emulator terminala:
Użyj ustawień domyślnych (Przewiń do przodu lub połącz) dla Git Pull:

Użyj Git-Credential Manager (ustawienie domyślne) dla Credential Helper:

In Konfigurowanie opcji dodatkowych, opuszczać Włącz buforowanie systemu plików zaznaczone i Włącz łącza symboliczne niezaznaczone (chyba że jesteś zaawansowanym użytkownikiem, który używa twardych linków do scentralizowanego repozytorium modeli).

Zakończ instalację i sprawdź, czy Git został zainstalowany prawidłowo, otwierając okno CMD i wpisując:
git --version

Logowanie do GitHub
Później, gdy spróbujesz sklonować repozytoria GitHub, możesz zostać poproszony o podanie swoich danych uwierzytelniających GitHub. Aby to przewidzieć, zaloguj się na swoje konto GitHub (utwórz je, jeśli to konieczne) w dowolnej przeglądarce zainstalowanej w systemie Windows. W ten sposób metoda uwierzytelniania 0Auth (okno pop-up) powinna zająć jak najmniej czasu.
Po tym początkowym wyzwaniu Twoje uwierzytelnienie powinno pozostać automatyczne.
6: Zainstaluj CMake
CMake 3.21 lub nowszy jest wymagany do części procesu instalacji Musubi. CMake to architektura programistyczna międzyplatformowa, która jest w stanie orkiestrować różne kompilatory i kompilować oprogramowanie z kodu źródłowego.
Pobierz go pod adresem:
https://cmake.org/download/ (Instalator Windows x64)
Uruchom instalator:

Zapewniać Dodaj Cmake do zmiennej środowiskowej PATH sprawdzone.

Naciśnij przycisk Następna.

Wpisz i wprowadź to polecenie w wierszu poleceń systemu Windows:
cmake --version
Jeśli program CMake został zainstalowany pomyślnie, wyświetli się coś takiego:
cmake version 3.31.4
CMake suite maintained and supported by Kitware (kitware.com/cmake).

7: Zainstaluj Pythona 3.10
Interpreter Pythona jest centralnym punktem tego projektu. Pobierz wersję 3.10 (najlepszy kompromis między różnymi wymaganiami pakietów Musubi) na:
https://www.python.org/downloads/release/python-3100/ ('Instalator systemu Windows (64-bitowy)')
Uruchom instalator i pozostaw ustawienia domyślne:
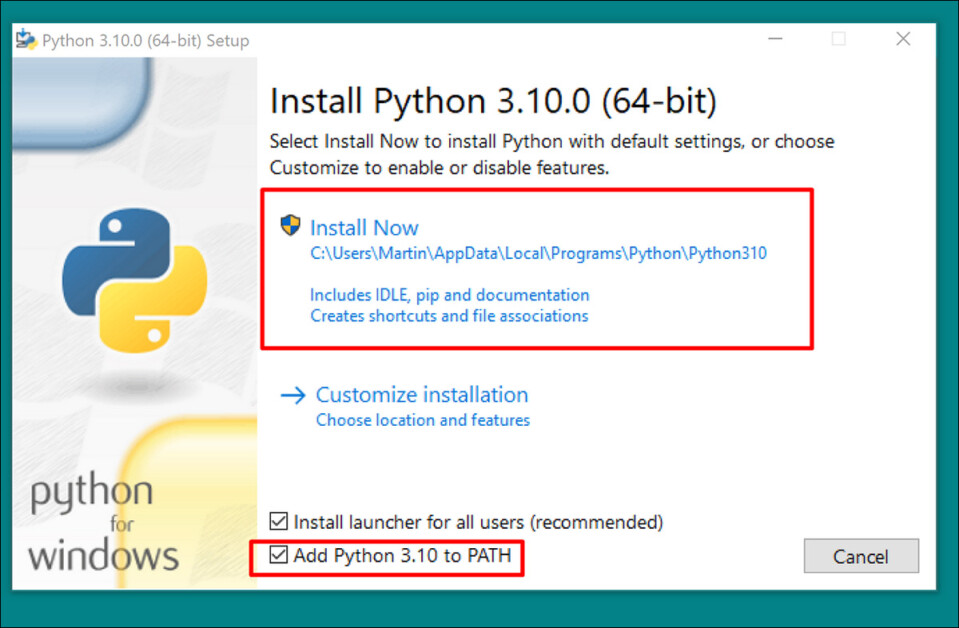

Na koniec procesu instalacji kliknij Wyłącz limit długości ścieżki (wymaga potwierdzenia administratora UAC):

W wierszu poleceń systemu Windows wpisz i wprowadź:
python --version
Powinno to skutkować Python 3.10.0

Sprawdź ścieżki
Klonowanie i instalacja frameworka Musubi, a także jego normalne działanie po instalacji, wymaga, aby jego komponenty znały ścieżkę do kilku ważnych komponentów zewnętrznych w systemie Windows, w szczególności CUDA.
Musimy więc otworzyć środowisko ścieżki i sprawdzić, czy zawiera wszystkie niezbędne elementy.
Szybkim sposobem na dostęp do elementów sterujących środowiska Windows jest wpisanie Edytuj zmienne środowiskowe systemu do paska wyszukiwania systemu Windows.

Kliknięcie tego spowoduje otwarcie Właściwości systemu panel sterowania. W prawym dolnym rogu Właściwości systemu, Kliknij Zmienne środowiskowe przycisk i okno o nazwie Zmienne środowiskowe otwiera się. W Zmienne systemowe panel w dolnej połowie tego okna, przewiń w dół, aby ścieżka i kliknij go dwukrotnie. Otworzy się okno o nazwie Edytuj zmienne środowiskowe. Przeciągnij szerokość tego okna, aby zobaczyć pełną ścieżkę zmiennych:

Oto najważniejsze wpisy:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.6\bin
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.6\libnvvp
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\bin
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\libnvvp
C:\Program Files (x86)\Microsoft Visual Studio\2019\Community\VC\Tools\MSVC\14.29.30133\bin\Hostx64\x64
C:\Program Files\Microsoft Visual Studio\2022\Community\VC\Tools\MSVC\14.42.34433\bin\Hostx64\x64
C:\Program Files\Git\cmd
C:\Program Files\CMake\bin
W większości przypadków prawidłowe zmienne ścieżki powinny już być obecne.
Dodaj wszystkie brakujące ścieżki, klikając Nowości po lewej stronie Edytuj zmienną środowiskową okno i wklejenie w poprawną ścieżkę:

NIE kopiuj i nie wklejaj ścieżek wymienionych powyżej; sprawdź, czy każda odpowiadająca jej ścieżka istnieje w Twojej instalacji systemu Windows.
Jeśli występują drobne różnice w ścieżkach (szczególnie w przypadku instalacji programu Visual Studio), należy użyć ścieżek wymienionych powyżej, aby znaleźć właściwe foldery docelowe (tj. x64 in Gospodarz64 w swojej własnej instalacji. Następnie wklej tych ścieżki do Edytuj zmienną środowiskową okno.
Następnie należy ponownie uruchomić komputer.
Instalowanie Musubi
Uaktualnij PIP
Użycie najnowszej wersji instalatora PIP może ułatwić niektóre etapy instalacji. W wierszu poleceń systemu Windows z uprawnieniami administratora (zobacz Elewacja, poniżej), wpisz i wprowadź:
pip install --upgrade pip
Elewacja
Niektóre polecenia mogą wymagać podwyższonych uprawnień (tj. aby były uruchamiane jako administrator). Jeśli otrzymasz komunikaty o błędach dotyczące uprawnień na następujących etapach, zamknij okno wiersza poleceń i otwórz je ponownie w trybie administratora, wpisując CMD do pola wyszukiwania systemu Windows, klikając prawym przyciskiem myszy Wiersz polecenia i wybierając Uruchom jako administrator:

W kolejnych etapach będziemy używać Windows Powershell zamiast wiersza poleceń Windows. Możesz go znaleźć, wpisując PowerShell do pola wyszukiwania systemu Windows i (w razie potrzeby) kliknij je prawym przyciskiem myszy, aby Uruchom jako administrator:

Zainstaluj Torch
W programie PowerShell wpisz i wprowadź:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
Bądź cierpliwy podczas instalacji wielu pakietów.
Po zakończeniu możesz zweryfikować instalację PyTorch obsługującą GPU, wpisując i wprowadzając:
python -c "import torch; print(torch.cuda.is_available())"
Powinno to skutkować:
C:\WINDOWS\system32>python -c "import torch;
print(torch.cuda.is_available())"
True
Zainstaluj Triton dla systemu Windows
Następnie instalacja Triton dla systemu Windows komponent. W podwyższonym Powershell wpisz (w jednym wierszu):
pip install https://github.com/woct0rdho/triton-windows/releases/download/v3.1.0-windows.post8/triton-3.1.0-cp310-cp310-win_amd64.whl
(Instalator triton-3.1.0-cp310-cp310-win_amd64.whl działa zarówno z procesorami Intel, jak i AMD, pod warunkiem, że architektura jest 64-bitowa, a środowisko jest zgodne z wersją Pythona)
Po uruchomieniu powinno to dać następujący wynik:
Successfully installed triton-3.1.0
Możemy sprawdzić, czy Triton działa, importując go do Pythona. Wprowadź to polecenie:
python -c "import triton; print('Triton is working')"
Powinno to dać następujący wynik:
Triton is working
Aby sprawdzić, czy Triton obsługuje procesor graficzny, wprowadź:
python -c "import torch; print(torch.cuda.is_available())"
Powinno to skutkować True:

Utwórz wirtualne środowisko dla Musubi
Od tej pory będziemy instalować wszelkie dalsze oprogramowanie w Wirtualne środowisko Pythona (lub wenw). Oznacza to, że wszystko, co musisz zrobić, aby odinstalować całe poniższe oprogramowanie, to przeciągnąć folder instalacyjny venv do kosza.
Utwórzmy ten folder instalacyjny: utwórz folder o nazwie Musubiego na pulpicie. Poniższe przykłady zakładają, że ten folder istnieje: C:\Users\[Your Profile Name]\Desktop\Musubi\.
W programie PowerShell przejdź do tego folderu, wpisując:
cd C:\Users\[Your Profile Name]\Desktop\Musubi
Chcemy, aby środowisko wirtualne miało dostęp do tego, co już zainstalowaliśmy (szczególnie Triton), dlatego użyjemy --system-site-packages flaga. Wpisz to:
python -m venv --system-site-packages musubi
Poczekaj, aż środowisko zostanie utworzone, a następnie aktywuj je, wpisując:
.\musubi\Scripts\activate
Od tego momentu możesz stwierdzić, że znajdujesz się w aktywowanym środowisku wirtualnym, ponieważ na początku wszystkich komunikatów pojawia się polecenie (musubi).

Sklonuj repozytorium
Przejdź do nowo utworzonego musubi folder (który znajduje się w środku Musubiego folder na pulpicie):
cd musubi
Teraz, gdy jesteśmy we właściwym miejscu, wprowadź następujące polecenie:
git clone https://github.com/kohya-ss/musubi-tuner.git
Poczekaj, aż klonowanie się zakończy (nie potrwa to długo).

Wymagania dotyczące instalacji
Przejdź do folderu instalacyjnego:
cd musubi-tuner
Wpisz:
pip install -r requirements.txt
Poczekaj, aż wszystkie instalacje zostaną ukończone (zajmie to więcej czasu).

Automatyzacja dostępu do Hunyuan Video Venv
Aby łatwo aktywować i uzyskać dostęp do nowego venv na potrzeby przyszłych sesji, wklej poniższy kod do Notatnika i zapisz go pod nazwą aktywuj.bat, zapisując to z Wszystkie pliki opcja (patrz obrazek poniżej).
@echo off
call C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\Scripts\activate
cd C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\musubi-tuner
cmd
(Zastąpić [Your Profile Name]z prawdziwą nazwą Twojego profilu użytkownika Windows)

Nie ma znaczenia, w jakiej lokalizacji zapiszesz ten plik.
Od teraz możesz kliknąć dwukrotnie aktywuj.bat i natychmiast rozpocząć pracę.

Korzystanie z tunera Musubi
Pobieranie modeli
Proces szkolenia Hunyuan Video LoRA wymaga pobrania co najmniej siedmiu modeli, aby obsługiwać wszystkie możliwe opcje optymalizacji dla wstępnego buforowania i szkolenia Hunyuan video LoRA. Łącznie te modele ważą ponad 60 GB.
Aktualne instrukcje dotyczące pobierania można znaleźć na stronie https://github.com/kohya-ss/musubi-tuner?tab=readme-ov-file#model-download
Jednakże w chwili pisania tego tekstu instrukcja pobierania wygląda następująco:
clip_l.safetensors
llava_llama3_fp16.safetensors
llava_llama3_fp8_scaled.safetensors
można pobrać pod adresem:
https://huggingface.co/Comfy-Org/HunyuanVideo_repackaged/tree/main/split_files/text_encoders
mp_rank_00_model_states.pt
mp_rank_00_model_states_fp8.pt
mp_rank_00_model_states_fp8_map.pt
można pobrać pod adresem:
https://huggingface.co/tencent/HunyuanVideo/tree/main/hunyuan-video-t2v-720p/transformers
pytorch_model.pt
można pobrać pod adresem:
https://huggingface.co/tencent/HunyuanVideo/tree/main/hunyuan-video-t2v-720p/vae
Chociaż możesz umieścić je w dowolnym wybranym przez siebie katalogu, dla zachowania spójności z późniejszymi skryptami umieśćmy je w:
C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\musubi-tuner\models\
Jest to zgodne z układem katalogów przed tym punktem. Wszelkie polecenia lub instrukcje w dalszej części będą zakładać, że to tutaj znajdują się modele; i nie zapomnij zastąpić [Twoja nazwa profilu] prawdziwą nazwą folderu profilu Windows.
Przygotowanie zbioru danych
Ignorując kontrowersje społeczności w tej kwestii, można uczciwie powiedzieć, że będziesz potrzebować od 10 do 100 zdjęć do zestawu danych treningowych dla Hunyuan LoRA. Bardzo dobre wyniki można uzyskać nawet przy 15 obrazach, o ile obrazy są dobrze wyważone i dobrej jakości.
Hunyuan LoRA można trenować zarówno na obrazach, jak i bardzo krótkich klipach wideo o niskiej rozdzielczości, a nawet na mieszance obu tych metod – choć korzystanie z klipów wideo jako danych treningowych jest trudne, nawet w przypadku karty o pojemności 24 GB.
Jednakże klipy wideo są naprawdę przydatne tylko wtedy, gdy Twoja postać porusza się w tak niezwykły sposób, że modelka fundacji Hunyuan Video może o tym nie wiedzieć, lub być w stanie zgadnąć.
Przykładami mogą być Roger Rabbit, ksenomorf, Maska, Spider-Man lub inne osobowości posiadające wyjątkowy charakterystyczny ruch.
Ponieważ Hunyuan Video wie już, jak poruszają się zwykli mężczyźni i kobiety, klipy wideo nie są konieczne, aby uzyskać przekonującą postać typu ludzkiego Hunyuan Video LoRA. Dlatego użyjemy statycznych obrazów.
Przygotowanie obrazu
The Bucket List
Wersja TLDR:
Najlepiej jest albo używać obrazów o tym samym rozmiarze dla całego zestawu danych, albo stosować podział 50/50 między dwoma różnymi rozmiarami, tj. 10 obrazów o wymiarach 512 x 768 pikseli i 10 o wymiarach 768 x 512 pikseli.
Szkolenie może się udać, nawet jeśli tego nie zrobisz – Hunyuan Video LoRAs potrafią być zaskakująco wyrozumiałe.
Dłuższa wersja
Podobnie jak w przypadku układów LoRA Kohya-ss dla statycznych systemów generatywnych, takich jak stabilna dyfuzja, wiadro służy do rozkładania obciążenia na obrazy o różnych rozmiarach, co pozwala na używanie większych obrazów bez powodowania błędów braku pamięci w czasie treningu (tj. podział „dzieli” obrazy na fragmenty, które może obsłużyć GPU, zachowując jednocześnie semantyczną integralność całego obrazu).
Dla każdego rozmiaru obrazu, który uwzględnisz w swoim zestawie danych treningowych (tj. 512x768px), zostanie utworzony zasobnik lub „podzadanie” dla tego rozmiaru. Jeśli więc masz następujący rozkład obrazów, w ten sposób uwaga zasobnika staje się niezrównoważona i istnieje ryzyko, że niektóre zdjęcia zostaną bardziej uwzględnione w treningu niż inne:
2x obrazy 512x768px
7x obrazy 768x512px
1x obraz 1000x600px
3x obrazy 400x800px
Możemy zauważyć, że uwaga widzów podzielona jest nierówno pomiędzy te obrazy:

Dlatego należy albo trzymać się jednego formatu, albo starać się, aby dystrybucja różnych rozmiarów była w miarę równomierna.
W obu przypadkach należy unikać bardzo dużych obrazów, ponieważ mogą one spowolnić proces szkolenia, przynosząc nieznaczne korzyści.
Dla uproszczenia dla wszystkich zdjęć w moim zbiorze danych zastosowałem rozdzielczość 512x768px.
Zrzeczenie się: Modelka (osoba) wykorzystana w zbiorze danych udzieliła mi pełnego pozwolenia na wykorzystanie tych zdjęć w tym celu i wyraziła zgodę na wszystkie dane wyjściowe oparte na sztucznej inteligencji przedstawiające jej podobiznę przedstawioną w tym artykule.

Mój zbiór danych składa się z 40 obrazów w formacie PNG (chociaż JPG też jest w porządku). Moje obrazy były przechowywane w C:\Users\Martin\Desktop\DATASETS_HUNYUAN\examplewoman
Powinieneś utworzyć Pamięć podręczna folder wewnątrz folderu z obrazem szkoleniowym:

Teraz utwórzmy specjalny plik, który skonfiguruje szkolenie.
Pliki TOML
Procesy szkolenia i wstępnego buforowania Hunyuan Video LoRAs pobierają ścieżki plików z płaskiego pliku tekstowego z .toml rozbudowa.
W moim teście plik TOML znajduje się w C:\Users\Martin\Desktop\DATASETS_HUNYUAN\training.toml
Zawartość mojego szkolenia TOML wygląda następująco:
[general]
resolution = [512, 768]
caption_extension = ".txt"
batch_size = 1
enable_bucket = true
bucket_no_upscale = false
[[datasets]]
image_directory = "C:\\Users\\Martin\\Desktop\\DATASETS_HUNYUAN\\examplewoman"
cache_directory = "C:\\Users\\Martin\\Desktop\\DATASETS_HUNYUAN\\examplewoman\\cache"
num_repeats = 1
(Podwójne ukośniki odwrotne dla katalogów obrazów i pamięci podręcznej nie zawsze są konieczne, ale mogą pomóc uniknąć błędów w przypadkach, gdy w ścieżce znajduje się spacja. Trenowałem modele z plikami .toml, które używały pojedynczych ukośników do przodu i do tyłu)
Możemy zobaczyć w resolution sekcja, że będą brane pod uwagę dwie rozdzielczości – 512px i 768px. Możesz również pozostawić 512 i nadal uzyskać dobre wyniki.
Podpisy
Hunyuan Video to jest XNUMX+model fundamentu wizji, więc potrzebujemy opisowych podpisów dla tych obrazów, które zostaną uwzględnione podczas treningu. Proces treningu zakończy się niepowodzeniem bez podpisów.
Istnieje wielość systemów napisów open source, których moglibyśmy użyć do tego zadania, ale zachowajmy prostotę i użyjmy tagui system. Chociaż jest przechowywany w GitHub i chociaż pobiera bardzo ciężkie modele głębokiego uczenia przy pierwszym uruchomieniu, jest on dostępny w formie prostego pliku wykonywalnego Windows, który ładuje biblioteki Pythona i prosty interfejs graficzny.
Po uruchomieniu Taggui użyj Plik > Załaduj katalog aby przejść do zestawu danych obrazów i opcjonalnie wpisać identyfikator tokena (w tym przypadku przykładowa kobieta) który zostanie dodany do wszystkich podpisów:

(Pamiętaj o wyłączeniu Załaduj w 4-bitach gdy Taggui zostanie uruchomiony po raz pierwszy – jeśli ta opcja pozostanie włączona, pojawią się błędy podczas tworzenia napisów)
Wybierz obraz w lewej kolumnie podglądu i naciśnij CTRL+A, aby wybrać wszystkie obrazy. Następnie naciśnij przycisk Start Auto-Captioning po prawej stronie:

Zobaczysz, że Taggui pobiera modele w małym CLI w prawej kolumnie, ale tylko jeśli jest to pierwsze uruchomienie captionera. W przeciwnym razie zobaczysz podgląd napisów.

Teraz każde zdjęcie ma swój podpis w formacie .txt zawierający opis zawartości obrazu:

Możesz kliknąć Opcje zaawansowane w Taggui, aby zwiększyć długość i styl napisów, ale to wykracza poza zakres tego przeglądu.
Zakończmy Taggui i przejdźmy do…
Utajone wstępne buforowanie
Aby uniknąć nadmiernego obciążenia procesora graficznego w czasie szkolenia, konieczne jest utworzenie dwóch typów wstępnie buforowanych plików – jeden w celu przedstawienia ukrytego obrazu pochodzącego z samych obrazów, a drugi w celu oceny kodowania tekstu odnoszącego się do zawartości napisów.
Aby uprościć wszystkie trzy procesy (2x pamięć podręczna + szkolenie), możesz użyć interaktywnych plików .BAT, które będą zadawać Ci pytania i wykonywać procesy po podaniu przez Ciebie niezbędnych informacji.
W przypadku ukrytego buforowania wstępnego skopiuj poniższy tekst do Notatnika i zapisz go jako plik .BAT (czyli nazwij go jakoś tak latent-precache.bat), jak poprzednio, upewniając się, że typ pliku w menu rozwijanym w Zapisz jako dialog jest Wszystkie pliki (zobacz obrazek poniżej):
@echo off
REM Activate the virtual environment
call C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\Scripts\activate.bat
REM Get user input
set /p IMAGE_PATH=Enter the path to the image directory:
set /p CACHE_PATH=Enter the path to the cache directory:
set /p TOML_PATH=Enter the path to the TOML file:
echo You entered:
echo Image path: %IMAGE_PATH%
echo Cache path: %CACHE_PATH%
echo TOML file path: %TOML_PATH%
set /p CONFIRM=Do you want to proceed with latent pre-caching (y/n)?
if /i "%CONFIRM%"=="y" (
REM Run the latent pre-caching script
python C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\musubi-tuner\cache_latents.py --dataset_config %TOML_PATH% --vae C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\musubi-tuner\models\pytorch_model.pt --vae_chunk_size 32 --vae_tiling
) else (
echo Operation canceled.
)
REM Keep the window open
pause
(Upewnij się, że wymieniłeś [Twoja nazwa profilu] z prawdziwą nazwą folderu profilu Windows)

Teraz możesz uruchomić plik .BAT w celu automatycznego buforowania danych ukrytych:

Gdy pojawi się monit dotyczący różnych pytań w pliku BAT, wklej lub wpisz ścieżkę do zestawu danych, folderów pamięci podręcznej i pliku TOML.
Wstępne buforowanie tekstu
Utworzymy drugi plik BAT, tym razem służący do wstępnego buforowania tekstu.
@echo off
REM Activate the virtual environment
call C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\Scripts\activate.bat
REM Get user input
set /p IMAGE_PATH=Enter the path to the image directory:
set /p CACHE_PATH=Enter the path to the cache directory:
set /p TOML_PATH=Enter the path to the TOML file:
echo You entered:
echo Image path: %IMAGE_PATH%
echo Cache path: %CACHE_PATH%
echo TOML file path: %TOML_PATH%
set /p CONFIRM=Do you want to proceed with text encoder output pre-caching (y/n)?
if /i "%CONFIRM%"=="y" (
REM Use the python executable from the virtual environment
python C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\musubi-tuner\cache_text_encoder_outputs.py --dataset_config %TOML_PATH% --text_encoder1 C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\musubi-tuner\models\llava_llama3_fp16.safetensors --text_encoder2 C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\musubi-tuner\models\clip_l.safetensors --batch_size 16
) else (
echo Operation canceled.
)
REM Keep the window open
pause
Zmień nazwę swojego profilu Windows i zapisz ją jako pamięć podręczna tekstu.bat (lub inną nazwę, jaką sobie wybierzesz), w dowolnym dogodnym miejscu, zgodnie z procedurą dla poprzedniego pliku BAT.
Uruchom nowy plik BAT, postępuj zgodnie z instrukcjami, a niezbędne pliki z zakodowanym tekstem pojawią się w Pamięć podręczna folder:

Szkolenie Hunyuan Video Lora
Szkolenie rzeczywistej obsługi LoRA zajmie znacznie więcej czasu niż te dwa procesy przygotowawcze.
Choć istnieje wiele zmiennych, o które możemy się martwić (takich jak rozmiar partii, powtórzenia, epoki oraz to, czy używać modeli pełnych, czy skwantowanych), odłożymy te rozważania na inny dzień i przyjrzymy się bliżej zawiłościom tworzenia LoRA.
Na razie ograniczmy nieco liczbę wyborów i przeszkolimy LoRA na ustawieniach „mediana”.
Utworzymy trzeci plik BAT, tym razem w celu rozpoczęcia treningu. Wklej go do Notatnika i zapisz jako plik BAT, tak jak poprzednio, jako szkolenie.bat (lub jakakolwiek inna nazwa, jaką chcesz):
@echo off
REM Activate the virtual environment
call C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\Scripts\activate.bat
REM Get user input
set /p DATASET_CONFIG=Enter the path to the dataset configuration file:
set /p EPOCHS=Enter the number of epochs to train:
set /p OUTPUT_NAME=Enter the output model name (e.g., example0001):
set /p LEARNING_RATE=Choose learning rate (1 for 1e-3, 2 for 5e-3, default 1e-3):
if "%LEARNING_RATE%"=="1" set LR=1e-3
if "%LEARNING_RATE%"=="2" set LR=5e-3
if "%LEARNING_RATE%"=="" set LR=1e-3
set /p SAVE_STEPS=How often (in steps) to save preview images:
set /p SAMPLE_PROMPTS=What is the location of the text-prompt file for training previews?
echo You entered:
echo Dataset configuration file: %DATASET_CONFIG%
echo Number of epochs: %EPOCHS%
echo Output name: %OUTPUT_NAME%
echo Learning rate: %LR%
echo Save preview images every %SAVE_STEPS% steps.
echo Text-prompt file: %SAMPLE_PROMPTS%
REM Prepare the command
set CMD=accelerate launch --num_cpu_threads_per_process 1 --mixed_precision bf16 ^
C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\musubi-tuner\hv_train_network.py ^
--dit C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\musubi-tuner\models\mp_rank_00_model_states.pt ^
--dataset_config %DATASET_CONFIG% ^
--sdpa ^
--mixed_precision bf16 ^
--fp8_base ^
--optimizer_type adamw8bit ^
--learning_rate %LR% ^
--gradient_checkpointing ^
--max_data_loader_n_workers 2 ^
--persistent_data_loader_workers ^
--network_module=networks.lora ^
--network_dim=32 ^
--timestep_sampling sigmoid ^
--discrete_flow_shift 1.0 ^
--max_train_epochs %EPOCHS% ^
--save_every_n_epochs=1 ^
--seed 42 ^
--output_dir "C:\Users\[Your Profile Name]\Desktop\Musubi\Output Models" ^
--output_name %OUTPUT_NAME% ^
--vae C:/Users/[Your Profile Name]/Desktop/Musubi/musubi/musubi-tuner/models/pytorch_model.pt ^
--vae_chunk_size 32 ^
--vae_spatial_tile_sample_min_size 128 ^
--text_encoder1 C:/Users/[Your Profile Name]/Desktop/Musubi/musubi/musubi-tuner/models/llava_llama3_fp16.safetensors ^
--text_encoder2 C:/Users/[Your Profile Name]/Desktop/Musubi/musubi/musubi-tuner/models/clip_l.safetensors ^
--sample_prompts %SAMPLE_PROMPTS% ^
--sample_every_n_steps %SAVE_STEPS% ^
--sample_at_first
echo The following command will be executed:
echo %CMD%
set /p CONFIRM=Do you want to proceed with training (y/n)?
if /i "%CONFIRM%"=="y" (
%CMD%
) else (
echo Operation canceled.
)
REM Keep the window open
cmd /k
Jak zwykle pamiętaj o zastąpieniu wszystkich wystąpień of [Twoja nazwa profilu] z prawidłową nazwą profilu Windows.
Upewnij się, że katalog C:\Users\[Your Profile Name]\Desktop\Musubi\Output Models\ istnieje, a jeśli nie istnieje, utwórz go w tej lokalizacji.
Podglądy szkoleń
Niedawno włączono bardzo podstawową funkcję podglądu treningu dla trenera Musubi, która umożliwia wymuszenie wstrzymania modelu treningu i generowanie obrazów na podstawie zapisanych przez Ciebie monitów. Są one zapisywane w automatycznie tworzonym folderze o nazwie Próba, w tym samym katalogu, w którym zapisywane są wytrenowane modele.

Aby to umożliwić, musisz zapisać co najmniej jeden monit w pliku tekstowym. Utworzony przez nas trening BAT poprosi Cię o podanie lokalizacji tego pliku; dlatego możesz nazwać plik monitu w dowolny sposób i zapisać go w dowolnym miejscu.
Poniżej przedstawiono kilka przykładów pliku, który na żądanie procedury szkoleniowej wygeneruje trzy różne obrazy:

Jak widać w powyższym przykładzie, na końcu monitu można umieścić flagi, które będą miały wpływ na obrazy:
–w jest szerokość (domyślnie 256px, jeśli nie ustawiono, zgodnie z dokumenty)
-jego wysokość (domyślnie 256px, jeśli nie ustawiono)
–f jest liczba klatek. Jeżeli ustawione na 1, tworzony jest obraz; jeżeli ustawione na więcej niż jeden, tworzony jest film wideo.
–d to ziarno. Jeśli nie jest ustawione, jest losowe; ale powinieneś je ustawić, aby zobaczyć rozwijający się monit.
–s to liczba kroków generacji, domyślnie 20.
See oficjalna dokumentacja po dodatkowe flagi.
Chociaż podglądy treningowe mogą szybko ujawnić pewne problemy, które mogą skłonić Cię do anulowania treningu i ponownego rozważenia danych lub konfiguracji, oszczędzając w ten sposób czas, pamiętaj, że każdy dodatkowy monit jeszcze bardziej spowalnia trening.
Ponadto, im większa szerokość i wysokość obrazu podglądu treningu (ustawionego we flagach wymienionych powyżej), tym bardziej spowolni to proces treningu.
Uruchom plik szkoleniowy BAT.
Pytanie #1 jest 'Wprowadź ścieżkę do konfiguracji zestawu danych. Wklej lub wpisz poprawną ścieżkę do pliku TOML.
Pytanie #2 to 'Wprowadź liczbę epok do trenowania'. Jest to zmienna prób i błędów, ponieważ zależy od ilości i jakości obrazów, a także podpisów i innych czynników. Generalnie lepiej ustawić ją za wysoko niż za nisko, ponieważ zawsze możesz zatrzymać trening za pomocą Ctrl+C w oknie treningu, jeśli uważasz, że model jest wystarczająco zaawansowany. Ustaw ją na 100 na początku i zobacz, jak to pójdzie.
Pytanie #3 jest 'Wprowadź nazwę modelu wyjściowego'. Nazwij swój model! Najlepiej byłoby zachować nazwę stosunkowo krótką i prostą.
Pytanie #4 to 'Wybierz tempo uczenia się', którego wartość domyślna to 1e-3 (opcja 1). To dobre miejsce na początek, w oczekiwaniu na dalsze doświadczenie.
Pytanie #5 to 'Jak często (w krokach) zapisywać obrazy podglądu. Jeśli ustawisz tę wartość zbyt nisko, zobaczysz niewielki postęp między zapisami obrazów podglądu, a to spowolni szkolenie.
Pytanie #6 jest 'Jaka jest lokalizacja pliku tekstowego monitu dla podglądów szkoleniowych?'. Wklej lub wpisz ścieżkę do pliku tekstowego monitu.
Następnie BAT pokazuje polecenie, które zostanie wysłane do modelu Hunyuan i pyta, czy chcesz kontynuować, t/n.
Rozpocznij trening:
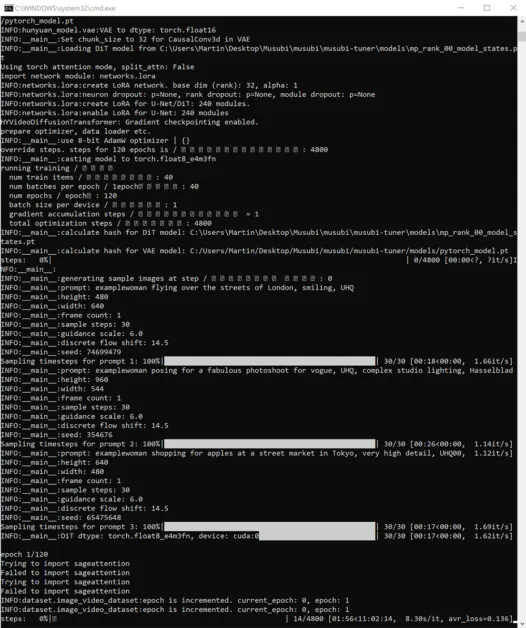
Jeśli w tym czasie sprawdzisz sekcję GPU na karcie Wydajność Menedżera zadań systemu Windows, zobaczysz, że proces ten wykorzystuje około 16 GB pamięci VRAM.

Może to nie być wartość przypadkowa, ponieważ jest to ilość pamięci VRAM dostępna na wielu kartach graficznych NVIDIA, a kod źródłowy mógł zostać zoptymalizowany tak, aby zadania mieściły się w 16 GB, ze względu na korzyści dla posiadaczy takich kart.
Mimo to, bardzo łatwo jest zwiększyć to wykorzystanie, wysyłając bardziej wygórowane flagi do polecenia szkoleniowego.
Podczas treningu w prawym dolnym rogu okna CMD wyświetlana jest liczba pokazująca, ile czasu minęło od rozpoczęcia treningu, a także szacunkowy całkowity czas treningu (który będzie się znacznie różnił w zależności od ustawionych flag, liczby obrazów treningowych, liczby obrazów podglądu treningu i kilku innych czynników).

Typowy czas szkolenia wynosi około 3–4 godzin przy średnich ustawieniach, w zależności od dostępnego sprzętu, liczby obrazów, ustawień flag i innych czynników.
Korzystanie z wytrenowanych modeli LoRA w Hunyuan Video
Wybór punktów kontrolnych
Po zakończeniu szkolenia będziesz mieć przykładowy punkt kontrolny dla każdej epoki szkolenia.

Użytkownik może zmienić częstotliwość zapisywania, aby zapisywać dane częściej lub rzadziej, zależnie od potrzeb, poprzez zmianę --save_every_n_epochs [N] liczba w pliku treningowym BAT. Jeśli dodałeś niską liczbę dla saves-per-steps podczas konfigurowania treningu z BAT, będzie duża liczba zapisanych plików punktów kontrolnych.
Który punkt kontrolny wybrać?
Jak wspomniano wcześniej, najwcześniej wyszkolone modele będą najbardziej elastyczne, podczas gdy późniejsze punkty kontrolne mogą oferować najwięcej szczegółów. Jedynym sposobem na przetestowanie tych czynników jest uruchomienie kilku LoRA i wygenerowanie kilku filmów. W ten sposób możesz dowiedzieć się, które punkty kontrolne są najbardziej produktywne i reprezentują najlepszą równowagę między elastycznością a wiernością.
Wygodny interfejs użytkownika
Najpopularniejszym (choć nie jedynym) środowiskiem do korzystania z Hunyuan Video LoRA jest obecnie Wygodny interfejs użytkownika, edytor oparty na węzłach z rozbudowanym interfejsem Gradio, który działa w przeglądarce internetowej.

Źródło: https://github.com/comfyanonymous/ComfyUI
Instrukcje instalacji są przejrzyste i dostępne w oficjalnym repozytorium GitHub (dodatkowe modele będą musiały zostać pobrane).
Konwersja modeli dla ComfyUI
Twoje wytrenowane modele są zapisywane w formacie (diffusers), który nie jest zgodny z większością implementacji ComfyUI. Musubi jest w stanie przekonwertować model do formatu zgodnego z ComfyUI. Skonfigurujmy plik BAT, aby to zaimplementować.
Przed uruchomieniem tego pliku BAT utwórz C:\Users\[Your Profile Name]\Desktop\Musubi\CONVERTED\ folder, którego oczekuje skrypt.
@echo off
REM Activate the virtual environment
call C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\Scripts\activate.bat
:START
REM Get user input
set /p INPUT_PATH=Enter the path to the input Musubi safetensors file (or type "exit" to quit):
REM Exit if the user types "exit"
if /i "%INPUT_PATH%"=="exit" goto END
REM Extract the file name from the input path and append 'converted' to it
for %%F in ("%INPUT_PATH%") do set FILENAME=%%~nF
set OUTPUT_PATH=C:\Users\[Your Profile Name]\Desktop\Musubi\Output Models\CONVERTED\%FILENAME%_converted.safetensors
set TARGET=other
echo You entered:
echo Input file: %INPUT_PATH%
echo Output file: %OUTPUT_PATH%
echo Target format: %TARGET%
set /p CONFIRM=Do you want to proceed with the conversion (y/n)?
if /i "%CONFIRM%"=="y" (
REM Run the conversion script with correctly quoted paths
python C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\musubi-tuner\convert_lora.py --input "%INPUT_PATH%" --output "%OUTPUT_PATH%" --target %TARGET%
echo Conversion complete.
) else (
echo Operation canceled.
)
REM Return to start for another file
goto START
:END
REM Keep the window open
echo Exiting the script.
pause
Podobnie jak w przypadku poprzednich plików BAT, zapisz skrypt w Notatniku jako „Wszystkie pliki”, nadając mu nazwę konwertuj.bat (lub cokolwiek chcesz).
Po zapisaniu kliknij dwukrotnie nowy plik BAT. Zostaniesz poproszony o podanie lokalizacji pliku, który chcesz przekonwertować.

Wklej lub wpisz ścieżkę do przeszkolonego pliku, który chcesz przekonwertować, kliknij yi naciśnij enter.
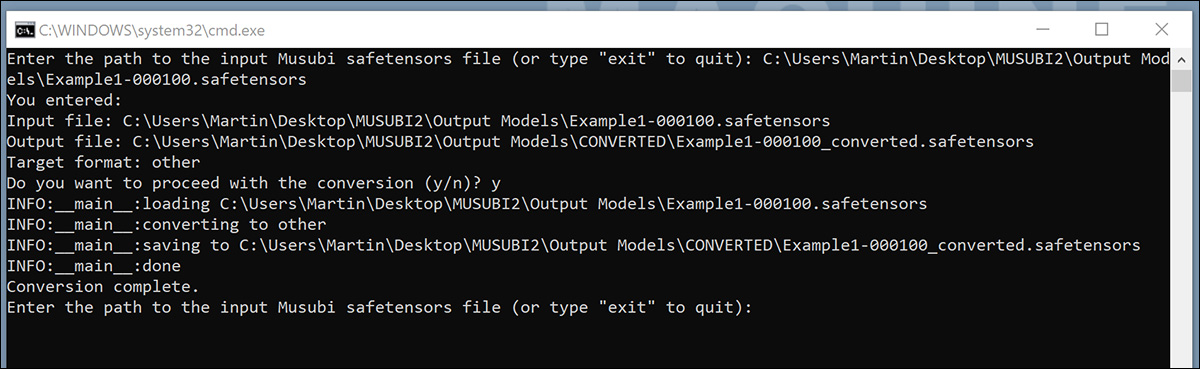
Po zapisaniu przekonwertowanego pliku LoRA do PRZEKSZTAŁCONY folder, skrypt zapyta, czy chcesz przekonwertować inny plik. Jeśli chcesz przetestować wiele punktów kontrolnych w ComfyUI, przekonwertuj wybrane modele.
Po przekonwertowaniu wystarczającej liczby punktów kontrolnych zamknij okno poleceń BAT.
Teraz możesz skopiować przekonwertowane modele do folderu models\loras w instalacji ComfyUI.
Zazwyczaj prawidłowa lokalizacja wygląda następująco:
C:\Users\[Your Profile Name]\Desktop\ComfyUI\models\loras\
Tworzenie Hunyuan Video LoRAs w ComfyUI
Chociaż oparte na węzłach przepływy pracy ComfyUI początkowo wydają się skomplikowane, ustawienia innych bardziej doświadczonych użytkowników można załadować, przeciągając obraz (utworzony za pomocą ComfyUI innego użytkownika) bezpośrednio do okna ComfyUI. Przepływy pracy można również eksportować jako pliki JSON, które można importować ręcznie lub przeciągać do okna ComfyUI.
Niektóre importowane przepływy pracy będą miały zależności, które mogą nie istnieć w Twojej instalacji. Dlatego zainstaluj Menedżer ComfyUI, który może automatycznie pobierać brakujące moduły.

Źródło: https://github.com/ltdrdata/ComfyUI-Manager
Aby załadować jeden z przepływów pracy używanych do generowania filmów z modeli w tym samouczku, pobierz ten plik JSON i przeciągnij go do okna ComfyUI (choć o wiele lepsze przykłady przepływu pracy można znaleźć w społecznościach Reddit i Discord, które przyjęły Hunyuan Video, a mój własny jest adaptacją jednego z nich).
To nie miejsce na obszerny samouczek dotyczący korzystania z ComfyUI, warto jednak wspomnieć o kilku istotnych parametrach, które będą miały wpływ na dane wyjściowe, jeśli pobierzesz i użyjesz układu JSON, do którego link zamieściłem powyżej.

1) Szerokość i wysokość
Im większy obraz, tym dłużej potrwa generowanie i tym większe ryzyko wystąpienia błędu braku pamięci (OOM).
2) Długość
To jest wartość liczbowa dla liczby klatek. Ile sekund to daje, zależy od liczby klatek na sekundę (ustawionej na 30 fps w tym układzie). Możesz przeliczyć sekundy>klatki na podstawie fps w Omnicalculatorze.
3) Wielkość partii
Im wyższy rozmiar partii, tym szybciej może nadejść wynik, ale tym większe obciążenie VRAM. Ustaw go zbyt wysoko, a możesz otrzymać OOM.
4) Kontrola po wygenerowaniu
Kontroluje losowe ziarno. Opcje dla tego podwęzła to: ustalony, przyrost, dekrementacja i randomizować. Jeśli zostawisz to w ustalony i nie zmieniaj monitu tekstowego, otrzymasz ten sam obraz za każdym razem. Jeśli zmienisz monit tekstowy, obraz zmieni się w ograniczonym zakresie. przyrost i dekrementacja ustawienia pozwalają na eksplorację pobliskich wartości nasion, podczas gdy randomizować daje Ci zupełnie nową interpretację polecenia.
5) Imię Lora
Przed próbą generowania musisz wybrać tutaj zainstalowany model.
6) Żeton
Jeśli wytrenowałeś swój model tak, aby wyzwalał koncepcję za pomocą tokena (takiego jak 'przykładowa osoba'), wpisz to słowo wyzwalające w swoim poleceniu.
7) Kroki
Reprezentuje to liczbę kroków, które system zastosuje w procesie dyfuzji. Wyższe kroki mogą zapewnić lepsze szczegóły, ale istnieje pułap skuteczności tego podejścia, a próg ten może być trudny do znalezienia. Typowy zakres kroków wynosi około 20–30.
8) Rozmiar kafelka
Definiuje to, ile informacji jest przetwarzanych jednorazowo podczas generowania. Domyślnie jest ustawione na 256. Podniesienie tej wartości może przyspieszyć generowanie, ale podniesienie jej zbyt wysoko może prowadzić do szczególnie frustrującego doświadczenia OOM, ponieważ następuje na samym końcu długiego procesu.
9) Nakładanie się czasowe
Hunyuan Generowanie wideo ludzi może prowadzić do „ghostingu” lub nieprzekonującego ruchu, jeśli jest ustawiony zbyt nisko. Ogólnie rzecz biorąc, obecna mądrość jest taka, że powinno się ustawić wyższą wartość niż liczba klatek, aby uzyskać lepszy ruch.
Podsumowanie
Chociaż dalsze badanie wykorzystania ComfyUI wykracza poza zakres tego artykułu, doświadczenie społeczności na Reddicie i Discordzie może ułatwić naukę, a istnieje kilka przewodniki online które wprowadzają podstawy.
Pierwsze opublikowanie: czwartek, 23 stycznia 2025 r.












