Artificial Intelligence
Zwiększanie wydajności modeli wielojęzycznych dzięki przewidywaniu wielu tokenów
Opublikowany
1 lat temuon

Duże modele językowe (LLM), takie jak GPT, LLaMA i inne, szturmem podbiły świat dzięki swojej niezwykłej zdolności rozumienia i generowania tekstu podobnego do ludzkiego. Jednak pomimo imponujących możliwości, standardowa metoda uczenia tych modeli, znana jako „przewidywanie następnego tokenu”, ma pewne nieodłączne ograniczenia.
W przewidywaniu następnego tokenu model jest szkolony w zakresie przewidywania następnego słowa w sekwencji, biorąc pod uwagę poprzednie słowa. Chociaż podejście to okazało się skuteczne, może prowadzić do modeli, które borykają się z zależnościami dalekiego zasięgu i złożonymi zadaniami rozumowania. Co więcej, niedopasowanie pomiędzy systemem szkolenia narzucającym nauczycielom a procesem generowania autoregresyjnego podczas wnioskowania może skutkować nieoptymalną wydajnością.
Niedawna praca naukowa autorstwa Gloeckle i in. (2024) z Meta AI wprowadza nowatorski paradygmat szkoleniowy zwany „przewidywanie wielu tokenów”, którego celem jest rozwiązanie tych ograniczeń i usprawnienie dużych modeli językowych. W tym poście na blogu zagłębimy się w podstawowe koncepcje, szczegóły techniczne i potencjalne implikacje tych przełomowych badań.
Przewidywanie pojedynczego tokenu: podejście konwencjonalne
Zanim zagłębimy się w szczegóły przewidywania wielu tokenów, konieczne jest zrozumienie konwencjonalnego podejścia, jakie stosowano do tej pory koń pociągowy dużego modelu językowego szkolenie na lata – przewidywanie pojedynczego tokenu, zwane także przewidywaniem następnego tokenu.
Paradygmat przewidywania następnego tokena
W paradygmacie przewidywania następnego tokena modele językowe są szkolone w zakresie przewidywania następnego słowa w sekwencji, biorąc pod uwagę poprzedni kontekst. Bardziej formalnie, model ma za zadanie maksymalizować prawdopodobieństwo wystąpienia następnego tokenu xt+1, biorąc pod uwagę poprzednie tokeny x1, x2,…, xt. Zwykle odbywa się to poprzez minimalizację strat entropii krzyżowej:
L = -Σt log P(xt+1 | x1, x2, …, xt)
Ten prosty, ale potężny cel szkoleniowy stał się podstawą wielu udanych dużych modeli językowych, takich jak GPT (Radford i in., 2018), BERT (Devlin i in., 2019) i ich wariantów.
Zmuszanie nauczycieli i pokolenie autoregresyjne
Przewidywanie następnego tokena opiera się na technice szkoleniowej zwanej „nauczyciel zmusza”, gdzie modelowi podczas szkolenia dostarczana jest podstawowa prawda dla każdego przyszłego tokena. Dzięki temu model może uczyć się z właściwego kontekstu i sekwencji docelowych, co ułatwia bardziej stabilny i efektywny trening.
Jednak podczas wnioskowania lub generowania model działa w sposób autoregresyjny, przewidując jeden token na raz na podstawie wcześniej wygenerowanych tokenów. To niedopasowanie pomiędzy systemem szkolenia (naciskanie przez nauczyciela) a systemem wnioskowania (generowanie autoregresyjne) może prowadzić do potencjalnych rozbieżności i nieoptymalnych wyników, szczególnie w przypadku dłuższych sekwencji lub złożonych zadań rozumowania.
Ograniczenia przewidywania następnego tokenu
Chociaż przewidywanie następnego tokena okazało się niezwykle skuteczne, ma również pewne nieodłączne ograniczenia:
- Krótkoterminowe skupienie: Przewidując jedynie następny token, model może mieć trudności z uchwyceniem długoterminowych zależności oraz ogólnej struktury i spójności tekstu, co może prowadzić do niespójności lub niespójnych pokoleń.
- Lokalne zatrzaskiwanie wzorców: Modele przewidywania następnego tokenu mogą opierać się na lokalnych wzorcach w danych szkoleniowych, co utrudnia uogólnianie na scenariusze lub zadania poza dystrybucją, które wymagają bardziej abstrakcyjnego rozumowania.
- Możliwości rozumowania: W przypadku zadań obejmujących rozumowanie wieloetapowe, myślenie algorytmiczne lub złożone operacje logiczne przewidywanie następnego elementu może nie zapewniać wystarczających odchyleń indukcyjnych lub reprezentacji, aby skutecznie wspierać takie możliwości.
- Nieefektywność próbki: Ze względu na lokalny charakter przewidywania następnego tokena modele mogą wymagać większych zbiorów danych szkoleniowych w celu zdobycia niezbędnej wiedzy i umiejętności rozumowania, co prowadzi do potencjalnej nieefektywności próbki.
Ograniczenia te zmotywowały badaczy do zbadania alternatywnych paradygmatów szkoleniowych, takich jak przewidywanie wielu tokenów, których celem jest usunięcie niektórych z tych niedociągnięć i odblokowanie nowych możliwości dla dużych modeli językowych.
Porównując konwencjonalne podejście do przewidywania następnego tokena z nowatorską techniką przewidywania wielu tokenów, czytelnicy mogą lepiej docenić motywację i potencjalne korzyści płynące z tej drugiej, przygotowując grunt pod głębszą eksplorację tego przełomowego badania.
Co to jest przewidywanie wielu tokenów?
Kluczową ideą przewidywania wielu tokenów jest uczenie modeli językowych, aby przewidywały jednocześnie wiele przyszłych tokenów, a nie tylko następny token. W szczególności podczas uczenia model ma za zadanie przewidzieć kolejnych n tokenów w każdej pozycji w korpusie szkoleniowym, przy użyciu n niezależnych głowic wyjściowych działających na szczycie wspólnego łącza modelu.
Na przykład w przypadku konfiguracji przewidywania obejmującej 4 tokeny model zostanie przeszkolony w zakresie przewidywania kolejnych 4 tokenów jednocześnie, biorąc pod uwagę poprzedni kontekst. Takie podejście zachęca model do uchwycenia zależności o dłuższym zasięgu i lepszego zrozumienia ogólnej struktury i spójności tekstu.
Przykład zabawki
Aby lepiej zrozumieć koncepcję przewidywania wielotokenowego, rozważmy prosty przykład. Załóżmy, że mamy następujące zdanie:
„Szybki brązowy lis przeskakuje leniwego psa”.
W standardowym podejściu do przewidywania następnego tokenu model zostałby przeszkolony w zakresie przewidywania następnego słowa w poprzednim kontekście. Na przykład, biorąc pod uwagę kontekst „Szybki brązowy lis przeskakuje”, model miałby za zadanie przewidzieć następne słowo „leniwy”.
Jednak w przypadku przewidywania wielu tokenów model zostałby przeszkolony w zakresie przewidywania wielu przyszłych słów jednocześnie. Na przykład, jeśli ustawimy n=4, model zostanie przeszkolony, aby przewidywać jednocześnie kolejne 4 słowa. Biorąc pod uwagę ten sam kontekst „Szybki brązowy lis przeskakuje”, model miałby za zadanie przewidzieć sekwencję „leniwy pies”. (Zwróć uwagę na spację po słowie „pies”, aby wskazać koniec zdania).
Ucząc model, aby przewidywał wiele przyszłych tokenów jednocześnie, zachęca się do wychwytywania zależności dalekiego zasięgu i lepszego zrozumienia ogólnej struktury i spójności tekstu.
Dane Techniczne
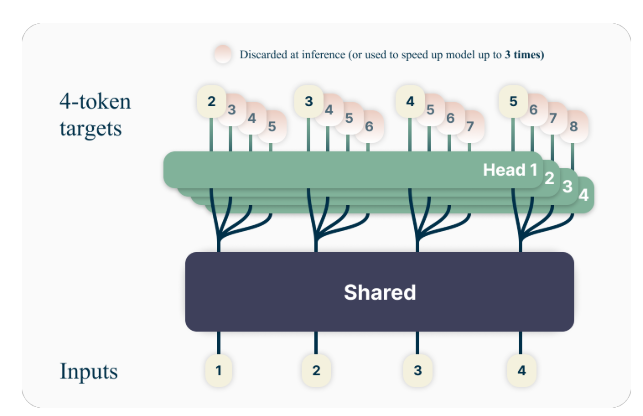
Autorzy proponują prostą, ale skuteczną architekturę implementacji przewidywania wielotokenowego. Model składa się ze wspólnej magistrali transformatora, która tworzy ukrytą reprezentację kontekstu wejściowego, po którym następuje n niezależne warstwy transformatorów (głowice wyjściowe), które przewidują odpowiednie przyszłe tokeny.
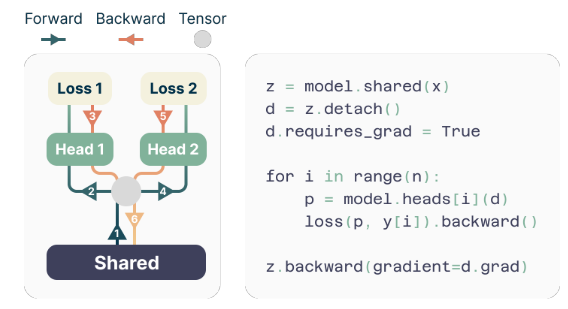
Podczas szkolenia przejścia do przodu i do tyłu są starannie koordynowane, aby zminimalizować zużycie pamięci GPU. Wspólne łącze oblicza ukrytą reprezentację, a następnie każda głowica wyjściowa sekwencyjnie wykonuje przejście do przodu i do tyłu, gromadząc gradienty na poziomie łącza. Takie podejście pozwala uniknąć jednoczesnej materializacji wszystkich wektorów logitowych i ich gradientów, redukując szczytowe zużycie pamięci GPU O(nV + d) do O(V + d), Gdzie V jest wielkość słownictwa i d jest wymiar ukrytej reprezentacji.
Implementacja oszczędzająca pamięć
Jednym z wyzwań w szkoleniu predyktorów wielotokenowych jest zmniejszenie wykorzystania pamięci GPU. Od wielkość słownictwa (V) jest zwykle znacznie większy niż wymiar ukrytej reprezentacji (D), wektory logitowe stają się wąskim gardłem w wykorzystaniu pamięci GPU.
Aby sprostać temu wyzwaniu, autorzy proponują implementację oszczędzającą pamięć, która dokładnie dostosowuje sekwencję operacji do przodu i do tyłu. Zamiast materializować jednocześnie wszystkie logity i ich gradienty, implementacja sekwencyjnie oblicza przejścia do przodu i do tyłu dla każdej niezależnej głowicy wyjściowej, gromadząc gradienty na poziomie magistrali.
Takie podejście pozwala uniknąć jednoczesnego przechowywania w pamięci wszystkich wektorów logitowych i ich gradientów, co zmniejsza szczytowe wykorzystanie pamięci GPU O(nV + d) do O(V + d), Gdzie n to liczba przewidywanych przyszłych tokenów.
Zalety przewidywania wielu tokenów
W artykule badawczym przedstawiono kilka istotnych zalet stosowania przewidywania wielotokenowego do uczenia dużych modeli językowych:
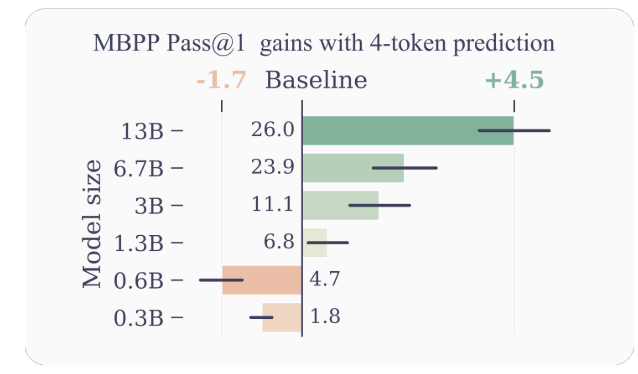
- Poprawiona wydajność próbki: Zachęcając model do przewidywania wielu przyszłych tokenów jednocześnie, przewidywanie wielu tokenów napędza model w kierunku lepszej wydajności próby. Autorzy wykazują znaczną poprawę wydajności zadań związanych ze zrozumieniem i generowaniem kodu, przy czym modele o parametrach do 13B rozwiązują średnio około 15% więcej problemów.
- Szybsze wnioskowanie: Dodatkowe głowice wyjściowe przeszkolone w zakresie przewidywania wielu tokenów można wykorzystać do dekodowania samospekulacyjnego, czyli wariantu dekodowania spekulatywnego, który umożliwia równoległe przewidywanie tokenów. Skutkuje to nawet 3-krotnie szybszym czasem wnioskowania w szerokim zakresie wielkości partii, nawet w przypadku dużych modeli.
- Promowanie zależności dalekiego zasięgu: Przewidywanie wielu tokenów zachęca model do przechwytywania zależności i wzorców o dłuższym zasięgu w danych, co jest szczególnie korzystne w przypadku zadań wymagających zrozumienia i rozumowania w szerszych kontekstach.
- Rozumowanie algorytmiczne: Autorzy przedstawiają eksperymenty dotyczące zadań syntetycznych, które wykazują wyższość wielotokenowych modeli predykcyjnych w opracowywaniu głowic indukcyjnych i możliwości wnioskowania algorytmicznego, szczególnie w przypadku modeli o mniejszych rozmiarach.
- Spójność i konsekwencja: Ucząc model przewidywania wielu przyszłych tokenów jednocześnie, przewidywanie wielu tokenów zachęca do opracowywania spójnych i spójnych reprezentacji. Jest to szczególnie przydatne w przypadku zadań wymagających generowania dłuższego, bardziej spójnego tekstu, takich jak opowiadanie historii, kreatywne pisanie lub generowanie instrukcji instruktażowych.
- Ulepszona generalizacja: Eksperymenty autorów dotyczące zadań syntetycznych sugerują, że modele predykcyjne z wieloma tokenami wykazują lepsze możliwości uogólniania, szczególnie w ustawieniach poza dystrybucją. Potencjalnie wynika to ze zdolności modelu do wychwytywania wzorców i zależności o dłuższym zasięgu, co może pomóc w skuteczniejszej ekstrapolacji na niewidoczne scenariusze.

Przykłady i intuicje
Aby zapewnić więcej intuicji, dlaczego przewidywanie wielu tokenów działa tak dobrze, rozważmy kilka przykładów:
- Generowanie kodu: W kontekście generowania kodu przewidywanie wielu tokenów jednocześnie może pomóc modelowi zrozumieć i wygenerować bardziej złożone struktury kodu. Na przykład podczas generowania definicji funkcji przewidywanie tylko następnego tokenu może nie zapewnić wystarczającego kontekstu, aby model mógł poprawnie wygenerować całą sygnaturę funkcji. Jednak prognozując wiele tokenów jednocześnie, model może lepiej uchwycić zależności między nazwą funkcji, parametrami i typem zwracanym, co prowadzi do dokładniejszego i spójnego generowania kodu.
- Rozumowanie w języku naturalnym: Rozważmy scenariusz, w którym model językowy ma za zadanie odpowiedzieć na pytanie wymagające rozumowania na podstawie wielu kroków lub fragmentów informacji. Przewidując jednocześnie wiele tokenów, model może lepiej uchwycić zależności między różnymi komponentami procesu rozumowania, co prowadzi do bardziej spójnych i dokładnych odpowiedzi.
- Generowanie długich tekstów: Podczas generowania długiego tekstu, takiego jak opowiadania, artykuły lub raporty, utrzymanie spójności i spójności przez dłuższy okres może stanowić wyzwanie w przypadku modeli językowych trenowanych za pomocą przewidywania następnego tokenu. Przewidywanie oparte na wielu tokenach zachęca model do opracowania reprezentacji, które oddają ogólną strukturę i przepływ tekstu, co potencjalnie prowadzi do bardziej spójnych i konsekwentnych generacji długich formularzy.
Ograniczenia i przyszłe kierunki
Chociaż wyniki przedstawione w artykule są imponujące, istnieje kilka ograniczeń i otwartych pytań, które wymagają dalszych badań:
- Optymalna liczba tokenów: W artykule zbadano różne wartości n (liczba przyszłych tokenów do przewidzenia) i stwierdzono, że n=4 sprawdza się dobrze w przypadku wielu zadań. Jednak optymalna wartość n może zależeć od konkretnego zadania, zbioru danych i rozmiaru modelu. Opracowanie opartych na zasadach metod określania optymalnego n może prowadzić do dalszej poprawy wydajności.
- Rozmiar słownictwa i tokenizacja: Autorzy zauważają, że optymalny rozmiar słownictwa i strategia tokenizacji dla modeli predykcji z wieloma tokenami mogą różnić się od tych stosowanych w modelach predykcji następnego tokenu. Zbadanie tego aspektu może prowadzić do lepszych kompromisów między długością skompresowanej sekwencji a wydajnością obliczeniową.
- Pomocnicze straty przewidywania: Autorzy sugerują, że ich praca może pobudzić zainteresowanie opracowaniem nowych pomocniczych strat w przewidywaniu dla dużych modeli językowych, wykraczających poza standardowe przewidywanie następnego tokena. Badanie alternatywnych strat pomocniczych i ich kombinacji za pomocą przewidywania wielu tokenów jest ekscytującym kierunkiem badań.
- Rozumienie teoretyczne: Chociaż artykuł dostarcza pewnych intuicji i dowodów empirycznych na skuteczność przewidywania wieloznacznego, cenne byłoby głębsze teoretyczne zrozumienie, dlaczego i jak to podejście działa tak dobrze.
Podsumowanie
Artykuł badawczy „Better & Faster Large Language Models via Multi-token Prediction” autorstwa Gloeckle i in. wprowadza nowatorski paradygmat uczenia się, który może znacznie poprawić wydajność i możliwości dużych modeli językowych. Ucząc modele, aby przewidywały wiele przyszłych tokenów jednocześnie, przewidywanie wielu tokenów zachęca do rozwoju zależności dalekiego zasięgu, zdolności wnioskowania algorytmicznego i lepszej wydajności próby.
Implementacja techniczna zaproponowana przez autorów jest elegancka i wydajna obliczeniowo, dzięki czemu możliwe jest zastosowanie tego podejścia do uczenia modeli językowych na dużą skalę. Co więcej, możliwość wykorzystania samospekulacyjnego dekodowania w celu szybszego wnioskowania jest znaczącą zaletą praktyczną.
Choć nadal istnieją otwarte pytania i obszary wymagające dalszych badań, badanie to stanowi ekscytujący krok naprzód w dziedzinie dużych modeli językowych. Ponieważ zapotrzebowanie na wydajniejsze i wydajniejsze modele językowe stale rośnie, przewidywanie oparte na wielu tokenach może stać się kluczowym elementem nowej generacji tych potężnych systemów sztucznej inteligencji.
Ostatnie pięć lat spędziłem zanurzając się w fascynującym świecie uczenia maszynowego i głębokiego uczenia się. Moja pasja i wiedza sprawiły, że uczestniczyłem w ponad 50 różnorodnych projektach z zakresu inżynierii oprogramowania, ze szczególnym uwzględnieniem AI/ML. Moja ciągła ciekawość przyciągnęła mnie również w stronę przetwarzania języka naturalnego – dziedziny, którą chcę dalej zgłębiać.

Możesz polubić
-


Agenci AI kontra duże modele: dlaczego podejście zespołowe działa lepiej niż większe systemy
-


DeepCoder-14B: Model AI Open Source zwiększający produktywność i innowacyjność programistów
-


Przyszłość reklamy po zamachu stanu w ruchu drogowym spowodowanym przez sztuczną inteligencję
-


W jaki sposób protokół Model Context Protocol (MCP) standaryzuje łączność AI z narzędziami i danymi
-


Stan sztucznej inteligencji w 2025 r.: najważniejsze wnioski z najnowszego raportu Stanford AI Index
-


Rozwój małych modeli rozumowania: czy kompaktowa sztuczna inteligencja może dorównać rozumowaniu na poziomie GPT?











