
Artificial Intelligence
Bezpośrednia optymalizacja preferencji: kompletny przewodnik

Dopasowanie dużych modeli językowych (LLM) do ludzkich wartości i preferencji stanowi wyzwanie. Tradycyjne metody, np Uczenie się ze wzmocnieniem na podstawie informacji zwrotnych od ludzi (RLHF) utorowały drogę, integrując wkład człowieka w celu udoskonalenia wyników modelu. Jednak RLHF może być złożony i wymagać dużych zasobów, wymagającej znacznej mocy obliczeniowej i przetwarzania danych. Bezpośrednia optymalizacja preferencji (DPO) to nowatorskie i bardziej usprawnione podejście, oferujące skuteczną alternatywę dla tradycyjnych metod. Upraszczając proces optymalizacji, DPO nie tylko zmniejsza obciążenie obliczeniowe, ale także zwiększa zdolność modelu do szybkiego dostosowywania się do ludzkich preferencji.
W tym przewodniku przyjrzymy się bliżej kwestii DPO, omawiając jej podstawy, sposób wdrażania i praktyczne zastosowania.
Potrzeba dostosowania preferencji
Aby zrozumieć DPO, kluczowe jest zrozumienie, dlaczego dostosowanie programów LLM do ludzkich preferencji jest tak ważne. Pomimo imponujących możliwości, programy LLM trenowane na rozległych zbiorach danych mogą czasami generować wyniki niespójne, stronnicze lub niezgodne z ludzkimi wartościami. To rozbieżność może objawiać się na różne sposoby:
- Generowanie niebezpiecznych lub szkodliwych treści
- Podawanie niedokładnych lub wprowadzających w błąd informacji
- Wykazywanie błędów obecnych w danych szkoleniowych
Aby rozwiązać te problemy, badacze opracowali techniki dostrajania LLM przy użyciu informacji zwrotnych od ludzi. Najbardziej znanym z tych podejść jest RLHF.
Zrozumienie RLHF: prekursor DPO
Uczenie się przez Wzmacnianie na podstawie Informacji Zwrotnej (RLHF) jest powszechnie stosowaną metodą dopasowywania LLM do ludzkich preferencji. Przyjrzyjmy się bliżej procesowi RLHF, aby zrozumieć jego złożoność:
a) Nadzorowane dostrajanie (SFT): Proces rozpoczyna się od dostrojenia wstępnie wyszkolonego LLM na zestawie danych obejmującym odpowiedzi wysokiej jakości. Ten krok pomaga modelowi wygenerować bardziej odpowiednie i spójne wyniki dla docelowego zadania.
b) Modelowanie nagród: Oddzielny model nagrody jest szkolony w celu przewidywania ludzkich preferencji. Obejmuje to:
- Generowanie par odpowiedzi dla zadanych podpowiedzi
- Poproszenie ludzi o ocenę preferowanej reakcji
- Uczenie modelu przewidywania tych preferencji
c) Uczenie się ze wzmocnieniem: Dostrojony LLM jest następnie dalej optymalizowany za pomocą uczenia się przez wzmacnianie. Model nagrody zapewnia informację zwrotną, kierując LLM w celu wygenerowania odpowiedzi zgodnych z ludzkimi preferencjami.
Oto uproszczony pseudokod Pythona ilustrujący proces RLHF:
Choć skuteczny, RLHF ma kilka wad:
- Wymaga szkolenia i utrzymywania wielu modeli (SFT, model nagrody i model zoptymalizowany pod kątem RL)
- Proces RL może być niestabilny i wrażliwy na hiperparametry
- Jest to kosztowne obliczeniowo i wymaga wielu przejść do przodu i do tyłu przez modele
Ograniczenia te motywują do poszukiwania prostszych i skuteczniejszych alternatyw, co doprowadziło do rozwoju DPO.
Bezpośrednia optymalizacja preferencji: podstawowe koncepcje

Bezpośrednia optymalizacja preferencji https://arxiv.org/abs/2305.18290
Na tym rysunku porównano dwa odmienne podejścia do dopasowywania wyników LLM do ludzkich preferencji: uczenie się przez wzmacnianie na podstawie ludzkiej informacji zwrotnej (RLHF) i bezpośrednią optymalizację preferencji (DPO). RLHF opiera się na modelu nagrody, który steruje polityką modelu językowego poprzez iteracyjne pętle sprzężenia zwrotnego, podczas gdy DPO bezpośrednio optymalizuje wyniki modelu, aby dopasować je do preferowanych przez człowieka odpowiedzi, wykorzystując dane dotyczące preferencji. To porównanie uwypukla mocne strony i potencjalne zastosowania każdej z metod, dostarczając wglądu w to, jak przyszłe LLM mogłyby być trenowane, aby lepiej odpowiadać ludzkim oczekiwaniom.
Kluczowe idee stojące za DPO:
a) Ukryte modelowanie nagród: DPO eliminuje potrzebę oddzielnego modelu nagrody, traktując sam model języka jako ukrytą funkcję nagrody.
b) Formuła oparta na zasadach: Zamiast optymalizować funkcję nagrody, DPO bezpośrednio optymalizuje politykę (model językowy), aby zmaksymalizować prawdopodobieństwo preferowanych odpowiedzi.
c) Rozwiązanie w formie zamkniętej: DPO wykorzystuje wiedzę matematyczną, która pozwala na rozwiązanie optymalnej polityki w formie zamkniętej, unikając konieczności iteracyjnych aktualizacji RL.
Wdrażanie DPO: praktyczny przegląd kodu
Poniższy obrazek przedstawia fragment kodu implementujący funkcję straty DPO za pomocą PyTorch. Funkcja ta odgrywa kluczową rolę w dopracowaniu sposobu, w jaki modele językowe priorytetyzują wyniki na podstawie preferencji użytkownika. Oto zestawienie kluczowych komponentów:
- Podpis funkcji: the
dpo_lossfunkcja przyjmuje kilka parametrów, w tym prawdopodobieństwa dziennika zasad (pi_logps), prawdopodobieństwa dziennika modelu referencyjnego (ref_logps) oraz wskaźniki reprezentujące preferowane i preferowane ukończenie (yw_idxs,yl_idxs). Dodatkowo, Abetaparametr kontroluje siłę kary KL. - Ekstrakcja prawdopodobieństwa logu: Kod wyodrębnia logarytmiczne prawdopodobieństwa preferowanych i niepreferowanych uzupełnień zarówno z modelu strategicznego, jak i referencyjnego.
- Obliczanie współczynnika logarytmicznego: Różnicę między prawdopodobieństwem logarytmicznym dla preferowanych i niepreferowanych uzupełnień oblicza się zarówno dla modelu strategicznego, jak i referencyjnego. Stosunek ten ma kluczowe znaczenie przy określaniu kierunku i wielkości optymalizacji.
- Kalkulacja strat i nagród: Stratę oblicza się za pomocą
logsigmoidfunkcję, podczas gdy nagrody są określane poprzez skalowanie różnicy między prawdopodobieństwem polityki a prawdopodobieństwem dziennika referencyjnego wedługbeta.

Funkcja utraty DPO przy użyciu PyTorch
Przyjrzyjmy się bliżej matematyce stojącej za DPO, aby zrozumieć, jak osiąga się te cele.
Matematyka DPO
DPO to sprytne przeformułowanie problemu uczenia się preferencji. Oto opis krok po kroku:
a) Punkt wyjścia: maksymalizacja nagrody ograniczonej do KL
Pierwotny cel RLHF można wyrazić jako:
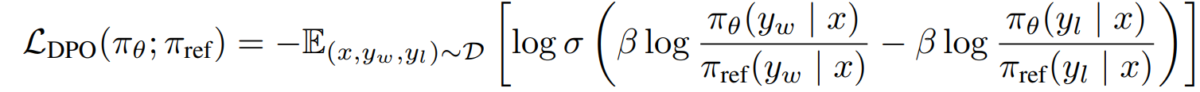
- πθ to polityka (model językowy), którą optymalizujemy
- r(x,y) jest funkcją nagrody
- πref to polityka referencyjna (zwykle początkowy model SFT)
- β kontroluje siłę ograniczenia rozbieżności KL
b) Optymalna forma polisy: Można wykazać, że optymalna polityka dla tego celu ma postać:
π_r(y|x) = 1/Z(x) * πref(y|x) * exp(1/β * r(x,y))Gdzie Z(x) jest stałą normalizacyjną.
c) Dwoistość polityki wynagrodzeń: Kluczowym spostrzeżeniem DPO jest wyrażenie funkcji nagrody w kategoriach optymalnej polityki:
r(x,y) = β * log(π_r(y|x) / πref(y|x)) + β * log(Z(x))d) Model preferencji Zakładając, że preferencje są zgodne z modelem Bradleya-Terry'ego, możemy wyrazić prawdopodobieństwo preferowania y1 zamiast y2 jako:
p*(y1 ≻ y2 | x) = σ(r*(x,y1) - r*(x,y2))Gdzie σ jest funkcją logistyczną.
e) Cel IOD Zastępując nasz dualizm polityki wynagrodzeń w modelu preferencji, dochodzimy do celu DPO:
L_DPO(πθ; πref) = -E_(x,y_w,y_l)~D [log σ(β * log(πθ(y_w|x) / πref(y_w|x)) - β * log(πθ(y_l|x) / πref(y_l|x)))]Cel ten można zoptymalizować przy użyciu standardowych technik opadania gradientowego, bez konieczności stosowania algorytmów RL.
Wdrażanie DPO
Teraz, gdy rozumiemy teorię dotyczącą DPO, przyjrzyjmy się, jak wdrożyć ją w praktyce. Użyjemy Python oraz PyTorch dla tego przykładu:
import torch
import torch.nn.functional as F
class DPOTrainer:
def __init__(self, model, ref_model, beta=0.1, lr=1e-5):
self.model = model
self.ref_model = ref_model
self.beta = beta
self.optimizer = torch.optim.AdamW(self.model.parameters(), lr=lr)
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs):
"""
pi_logps: policy logprobs, shape (B,)
ref_logps: reference model logprobs, shape (B,)
yw_idxs: preferred completion indices in [0, B-1], shape (T,)
yl_idxs: dispreferred completion indices in [0, B-1], shape (T,)
beta: temperature controlling strength of KL penalty
Each pair of (yw_idxs[i], yl_idxs[i]) represents the indices of a single preference pair.
"""
# Extract log probabilities for the preferred and dispreferred completions
pi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs]
ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs]
# Calculate log-ratios
pi_logratios = pi_yw_logps - pi_yl_logps
ref_logratios = ref_yw_logps - ref_yl_logps
# Compute DPO loss
losses = -F.logsigmoid(self.beta * (pi_logratios - ref_logratios))
rewards = self.beta * (pi_logps - ref_logps).detach()
return losses.mean(), rewards
def train_step(self, batch):
x, yw_idxs, yl_idxs = batch
self.optimizer.zero_grad()
# Compute log probabilities for the model and the reference model
pi_logps = self.model(x).log_softmax(-1)
ref_logps = self.ref_model(x).log_softmax(-1)
# Compute the loss
loss, _ = self.compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs)
loss.backward()
self.optimizer.step()
return loss.item()
# Usage
model = YourLanguageModel() # Initialize your model
ref_model = YourLanguageModel() # Load pre-trained reference model
trainer = DPOTrainer(model, ref_model)
for batch in dataloader:
loss = trainer.train_step(batch)
print(f"Loss: {loss}")
Wyzwania i przyszłe kierunki
Chociaż DPO oferuje znaczną przewagę nad tradycyjnymi podejściami RLHF, nadal istnieją wyzwania i obszary dalszych badań:
a) Skalowalność do większych modeli:
W miarę ciągłego powiększania się modeli językowych, efektywne zastosowanie DPO do modeli zawierających setki miliardów parametrów pozostaje otwartym wyzwaniem. Naukowcy badają takie techniki, jak:
- Efektywne metody dostrajania (np. LoRA, strojenie prefiksów)
- Rozproszone optymalizacje treningu
- Gradientowe punkty kontrolne i szkolenie o mieszanej precyzji
Przykład użycia LoRA z DPO:
from peft import LoraConfig, get_peft_model
class DPOTrainerWithLoRA(DPOTrainer):
def __init__(self, model, ref_model, beta=0.1, lr=1e-5, lora_rank=8):
lora_config = LoraConfig(
r=lora_rank,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
self.model = get_peft_model(model, lora_config)
self.ref_model = ref_model
self.beta = beta
self.optimizer = torch.optim.AdamW(self.model.parameters(), lr=lr)
# Usage
base_model = YourLargeLanguageModel()
dpo_trainer = DPOTrainerWithLoRA(base_model, ref_model)
b) Dostosowanie do wielu zadań i kilku strzałów:
Aktywnym obszarem badań jest rozwój technik DPO, które można skutecznie dostosować do nowych zadań lub dziedzin z ograniczonymi danymi dotyczącymi preferencji. Badane podejścia obejmują:
- Ramy metauczenia się umożliwiające szybką adaptację
- Dostrajanie oparte na podpowiedziach dla DPO
- Przenieś naukę z ogólnych modeli preferencji do konkretnych dziedzin
c) Postępowanie z niejednoznacznymi lub sprzecznymi preferencjami:
Dane dotyczące preferencji w świecie rzeczywistym często zawierają niejasności lub sprzeczności. Poprawa odporności DPO na takie dane jest kluczowa. Potencjalne rozwiązania obejmują:
- Probabilistyczne modelowanie preferencji
- Aktywne uczenie się rozwiązywania niejasności
- Agregacja preferencji wielu agentów
Przykład probabilistycznego modelowania preferencji:
class ProbabilisticDPOTrainer(DPOTrainer):
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs, preference_prob):
# Compute log ratios
pi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs]
ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs]
log_ratio_diff = pi_yw_logps.sum(-1) - pi_yl_logps.sum(-1)
loss = -(preference_prob * F.logsigmoid(self.beta * log_ratio_diff) +
(1 - preference_prob) * F.logsigmoid(-self.beta * log_ratio_diff))
return loss.mean()
# Usage
trainer = ProbabilisticDPOTrainer(model, ref_model)
loss = trainer.compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs, preference_prob=0.8) # 80% confidence in preference
d) Łączenie DPO z innymi technikami dopasowywania:
Integracja DPO z innymi podejściami do dostosowania może prowadzić do powstania solidniejszych i wydajniejszych systemów:
- Konstytucyjne zasady sztucznej inteligencji dotyczące wyraźnego zaspokajania ograniczeń
- Debata i rekurencyjne modelowanie nagród w celu wywoływania złożonych preferencji
- Odwrotne uczenie się przez wzmacnianie w celu wnioskowania podstawowych funkcji nagrody
Przykład połączenia DPO z konstytucyjną AI:
class ConstitutionalDPOTrainer(DPOTrainer):
def __init__(self, model, ref_model, beta=0.1, lr=1e-5, constraints=None):
super().__init__(model, ref_model, beta, lr)
self.constraints = constraints or []
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs):
base_loss = super().compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs)
constraint_loss = 0
for constraint in self.constraints:
constraint_loss += constraint(self.model, pi_logps, ref_logps, yw_idxs, yl_idxs)
return base_loss + constraint_loss
# Usage
def safety_constraint(model, pi_logps, ref_logps, yw_idxs, yl_idxs):
# Implement safety checking logic
unsafe_score = compute_unsafe_score(model, pi_logps, ref_logps)
return torch.relu(unsafe_score - 0.5) # Penalize if unsafe score > 0.5
constraints = [safety_constraint]
trainer = ConstitutionalDPOTrainer(model, ref_model, constraints=constraints)
Rozważania praktyczne i najlepsze praktyki
Wdrażając DPO do rzeczywistych zastosowań, należy wziąć pod uwagę następujące wskazówki:
a) Jakość danych: Jakość danych dotyczących Twoich preferencji jest kluczowa. Upewnij się, że Twój zbiór danych:
- Obejmuje różnorodny zakres danych wejściowych i pożądanych zachowań
- Zawiera spójne i wiarygodne adnotacje dotyczące preferencji
- Równoważy różne typy preferencji (np. rzeczowość, bezpieczeństwo, styl)
b) Dostrajanie hiperparametrów: Chociaż DPO ma mniej hiperparametrów niż RLHF, dostrojenie jest nadal ważne:
- β (beta): kontroluje kompromis między zaspokojeniem preferencji a rozbieżnością z modelem referencyjnym. Zacznij od wartości w pobliżu 0.1-0.5 .
- Szybkość uczenia się: Użyj niższej szybkości uczenia się niż standardowe dostrajanie, zazwyczaj w zakresie 1e-6 do 1e-5.
- Wielkość partii: Większe wielkości partii (32-128 ) często dobrze sprawdzają się w przypadku uczenia się preferencji.
c) Udoskonalanie iteracyjne: DPO można zastosować iteracyjnie:
- Wytrenuj początkowy model za pomocą narzędzia DPO
- Generuj nowe odpowiedzi przy użyciu przeszkolonego modelu
- Zbierz nowe dane dotyczące preferencji na temat tych odpowiedzi
- Ponowne szkolenie przy użyciu rozszerzonego zestawu danych

Wydajność optymalizacji preferencji bezpośrednich
Poniższy wykres przedstawia wydajność modeli LLM, takich jak GPT-4, w porównaniu z ludzkimi osądami w różnych technikach szkoleniowych, w tym optymalizacji preferencji bezpośrednich (DPO), dostrajania nadzorowanego (SFT) i optymalizacji polityki proksymalnej (PPO). Tabela pokazuje, że wyniki GPT-4 są coraz bardziej zgodne z ludzkimi preferencjami, zwłaszcza w zadaniach podsumowujących. Poziom zgodności między GPT-4 a ludzkimi recenzentami dowodzi, że model ten potrafi generować treści, które rezonują z ludzkimi ewaluatorami, niemal tak samo jak treści generowane przez ludzi.
Studia przypadków i zastosowania
Aby zobrazować skuteczność urzędu IOD, przyjrzyjmy się kilku rzeczywistym zastosowaniom i wariantom urzędu:
- Iteracyjny inspektor ochrony danych: Wariant ten, opracowany przez Snorkela (2023), łączy próbkowanie odrzucone z DPO, umożliwiając bardziej udoskonalony proces selekcji danych szkoleniowych. Dzięki iteracji po wielu rundach próbkowania preferencji model jest w stanie lepiej uogólniać i unikać nadmiernego dopasowania do zaszumionych lub stronniczych preferencji.
- IPO (Iteracyjna optymalizacja preferencji): Wprowadzone przez Azara i in. (2023) IPO dodaje termin regularyzujący, aby zapobiec nadmiernemu dopasowaniu, co jest częstym problemem w optymalizacji opartej na preferencjach. To rozszerzenie pozwala modelom zachować równowagę pomiędzy trzymaniem się preferencji i zachowaniem możliwości uogólniania.
- KTO (Optymalizacja transferu wiedzy): Nowszy wariant z Ethayarajh i in. (2023) KTO całkowicie rezygnuje z preferencji binarnych. Zamiast tego koncentruje się na przenoszeniu wiedzy z modelu referencyjnego do modelu polityki, optymalizując w celu płynniejszego i bardziej spójnego dostosowania do wartości ludzkich.
- Multimodalny DPO do uczenia się między domenami przez Xu i in. (2024): podejście, w którym DPO jest stosowane w różnych modalnościach — tekście, obrazie i dźwięku — co pokazuje jego wszechstronność w dopasowywaniu modeli do ludzkich preferencji w przypadku różnych typów danych. Badanie to podkreśla potencjał DPO w tworzeniu bardziej kompleksowych systemów sztucznej inteligencji zdolnych do obsługi złożonych, multimodalnych zadań.











