Sztuczna inteligencja
Wykrywanie fałszywych połączeń wideo za pomocą oświetlenia monitora
Nowa współpraca między badaczem z amerykańskiej Agencji Bezpieczeństwa Narodowego (NSA) i Uniwersytetu Kalifornijskiego w Berkeley oferuje nową metodę wykrywania treści deepfake w kontekście transmisji wideo na żywo – poprzez obserwację wpływu oświetlenia monitora na wygląd osoby na drugim końcu połączenia wideo.

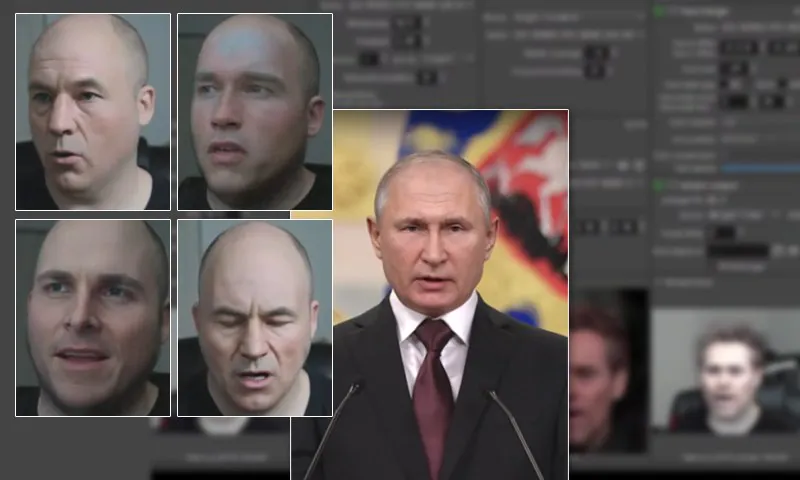
Popularny użytkownik DeepFaceLive Druuzil Tech & Games testuje swój własny model Christiana Bale’a DeepFaceLab podczas sesji na żywo z jego followerami, podczas gdy źródła światła się zmieniają. Źródło: https://www.youtube.com/watch?v=XPQLDnogLKA
System działa poprzez umieszczenie elementu graficznego na ekranie użytkownika, który zmienia wąski zakres koloru szybciej niż typowy system deepfake może zareagować – nawet jeśli, jak w przypadku implementacji deepfake w czasie rzeczywistym DeepFaceLive (pokazany powyżej), ma pewną zdolność do utrzymania transfery koloru na żywo i uwzględniania oświetlenia otoczenia.
Jednolity obraz koloru wyświetlany na monitorze osoby na drugim końcu (tj. potencjalnego oszusta deepfake) przechodzi przez ograniczoną zmianę odcienia, która nie aktywuje automatycznego balansu bieli kamery internetowej i innych systemów ad hoc kompensacji oświetlenia, co mogłoby naruszyć tę metodę.

Z artykułu, ilustracja zmiany warunków oświetleniowych z monitora przed użytkownikiem, która skutecznie działa jako rozproszone ‘światło powierzchni’. Źródło: https://farid.berkeley.edu/downloads/publications/cvpr22a.pdf
Teoria za tym podejściem jest taka, że systemy deepfake na żywo nie mogą zareagować na czas na zmiany przedstawione na grafice na ekranie, zwiększając ‘opóźnienie’ efektu deepfake w pewnych częstotliwościach koloru, ujawniając jego obecność.
Aby możliwe było dokładne pomiarowanie odbitego światła monitora, system musi uwzględnić i wykluczyć wpływ ogólnego oświetlenia środowiskowego, które nie jest związane ze światłem z monitora. Może wtedy odróżnić braki w pomiarze aktywnego oświetlenia i odcienia twarzy użytkownika, reprezentując przesunięcie czasowe 1-4 klatek na sekundę:

Poprzez ograniczenie zmian odcienia w grafice ‘wykrywacza’ na ekranie i zapewnienie, że kamera internetowa użytkownika nie jest pobudzona do automatycznego dostosowania ustawień przechwytywania przez nadmierne zmiany w poziomach oświetlenia monitora, badacze byli w stanie wykryć charakterystyczne opóźnienie w dostosowaniu systemu deepfake do zmian oświetlenia.
Artykuł kończy się:
‘Ponieważ pokładamy uzasadnione zaufanie w połączenia wideo na żywo, oraz ze względu na rosnącą powszechność połączeń wideo w naszym życiu prywatnym i zawodowym, proponujemy, że techniki uwierzytelniania połączeń wideo (i audio) będą tylko zyskiwać na ważności.’
Badanie pt. Wykrywanie filmów deepfake w czasie rzeczywistym za pomocą aktywnego oświetlenia, pochodzi od Candice R. Gerstner, matematyka stosowanego w Departamencie Obrony USA, oraz profesora Hany Farida z Berkeley.
Erozja zaufania
Scena badań nad deepfake znacznie zmieniła się w ciągu ostatnich sześciu miesięcy, od ogólnego wykrywania deepfake (tj. ukierunkowanego na nagrane wcześniej filmy i treści pornograficzne) do wykrywania ‘żywotności’, w odpowiedzi na rosnącą falę incydentów z użyciem deepfake w połączeniach wideo, oraz do niedawnego ostrzeżenia FBI dotyczącego rosnącego użycia takich technologii w aplikacjach do pracy zdalnej.
Nawet w przypadku, gdy połączenie wideo nie okazuje się być deepfake, zwiększające się możliwości dla AI-driven impersonatorów wideo zaczynają generować paranoję.
Nowy artykuł stwierdza:
‘Stworzenie deepfake’ów w czasie rzeczywistym [stanowi] unikalne zagrożenia ze względu na ogólne poczucie zaufania otaczające połączenie wideo lub rozmowę telefoniczną, oraz wyzwania związane z wykrywaniem deepfake’ów w czasie rzeczywistym, podczas trwania połączenia.’
Społeczność badawcza dążyła od dawna do znalezienia niezawodnych oznak treści deepfake, które nie mogą być łatwo skompensowane. Chociaż media często charakteryzują to jako wojnę technologiczną między badaczami bezpieczeństwa a twórcami deepfake’ów, większość negacji wczesnych podejść (takich jak analiza mrugania oczu, rozróżnianie pozy head oraz analiza zachowania) wystąpiła po prostu dlatego, że twórcy i użytkownicy starali się stworzyć bardziej realistyczne deepfake’ów w ogóle, a nie konkretnie w celu rozwiązania najnowszych ‘oznak’ zidentyfikowanych przez społeczność bezpieczeństwa.
Rzucanie światła na żywe deepfake wideo
Wykrywanie deepfake’ów w środowiskach wideo na żywo niesie ze sobą ciężar uwzględnienia słabych połączeń wideo, które są bardzo powszechne w scenariuszach wideokonferencji. Nawet bez interweniującej warstwy deepfake, treści wideo mogą być poddane opóźnieniom w stylu NASA, artefaktom renderowania i innym typom degradacji audio i wideo. Mogą one służyć do ukrycia szorstkich krawędzi w architekturze deepfake na żywo, zarówno w odniesieniu do wideo, jak i audio deepfake.
System autorów poprawia wyniki i metody, które pojawiły się w publikacji z 2020 roku z Centrum Komputingu Sieciowego na Uniwersytecie Temple w Filadelfii.

Z artykułu z 2020 roku, można zaobserwować zmianę w ‘wypełnionym’ oświetleniu twarzy wraz ze zmianą zawartości ekranu użytkownika. Źródło: https://cis.temple.edu/~jiewu/research/publications/Publication_files/FakeFace__ICDCS_2020.pdf
Różnica w nowej pracy polega na tym, że bierze pod uwagę, jak kamery internetowe reagują na zmiany oświetlenia. Autorzy wyjaśniają:
‘Ponieważ wszystkie nowoczesne kamery internetowe wykonują automatyczne nastawienie ekspozycji, rodzaj silnego aktywnego oświetlenia [użytego w poprzedniej pracy] prawdopodobnie spowoduje wyzwolenie automatycznego nastawienia ekspozycji kamery, co z kolei zaburzy zarejestrowany wygląd twarzy. Aby temu zapobiec, zastosowaliśmy aktywne oświetlenie składające się z izoluminantnej zmiany odcienia.
‘Chociaż to uniknie automatycznego nastawienia ekspozycji, może to spowodować wyzwolenie balansu bieli kamery, co ponownie zaburzy zarejestrowany wygląd twarzy. Aby temu zapobiec, działamy w zakresie odcienia, który empirycznie ustaliliśmy, nie wyzwala balansu bieli.’
Dla tej inicjatywy autorzy rozważyli również podobne poprzednie próby, takie jak LiveScreen, które wymuszają niewidoczną wzór oświetlenia na monitorze użytkownika w celu ujawnienia treści deepfake.
Chociaż ten system osiągnął wskaźnik dokładności 94,8%, badacze stwierdzają, że subtelność wzorów świetlnych sprawiłaby, że taki ukryty podejście byłoby trudne do wdrożenia w środowiskach o jasnym oświetleniu, i zamiast tego proponują, że ich własny system, lub taki, który jest wzorowany na podobnych liniach, mógłby być wbudowany publicznie i domyślnie w popularne oprogramowanie do wideokonferencji:
‘Nasza proponowana interwencja mogłaby być zrealizowana przez uczestnika połączenia, który po prostu udostępnia swój ekran i wyświetla zmieniający się wzór, lub, optymalnie, mogłaby być bezpośrednio zintegrowana z klientem wideokonferencji.’
Testy
Autorzy użyli mieszanki syntetycznych i rzeczywistych podmiotów do przetestowania ich wykrywacza deepfake z napędem Dlib. Dla scenariusza syntetycznego użyli Mitsubę, renderera do przodu i do tyłu ze Szwajcarskiego Federalnego Instytutu Technologicznego w Lozannie.

Przykłady z testów symulowanego środowiska, zawierające zmieniający się odcień skóry, rozmiar źródła światła, intensywność światła otoczenia i odległość od kamery.
Scena przedstawiona obejmuje głowę CGI przechwyconą z wirtualnej kamery z polem widzenia 90°. Głowy te mają odblaskowość lambertowską i neutralne odcienie skóry, oraz są umieszczone 2 stopy przed wirtualną kamerą.
Aby przetestować ramę w różnych możliwych skórkach i ustawieniach, badacze przeprowadzili serię testów, zmieniając różne aspekty sekwencyjnie. Zmieniane aspekty obejmowały odcień skóry, odległość i rozmiar źródła światła.
Autorzy komentują:
‘W symulacji, przy założeniu, że nasze różne założenia są spełnione, nasza proponowana technika jest bardzo odporna na szeroki zakres konfiguracji obrazowania.’
Dla scenariusza rzeczywistego badacze użyli 15 wolontariuszy o różnych odcieniach skóry, w różnych środowiskach. Każdy z nich został poddany dwóm cyklom ograniczonej zmiany odcienia, w warunkach, w których częstotliwość odświeżania wyświetlacza 30 Hz była zsynchronizowana z kamerą internetową, co oznacza, że aktywne oświetlenie trwałoby tylko przez jedną sekundę na raz. Wyniki były ogólnie porównywalne z testami syntetycznymi, chociaż korelacje zwiększyły się znacznie z większymi wartościami oświetlenia.
Przyszłe kierunki
System, jak przyznają badacze, nie uwzględnia typowych zakryć twarzy, takich jak grzywka, okulary lub broda. Mogą jednak zauważyć, że maskowanie tego rodzaju może być dodane do późniejszych systemów (poprzez etykietowanie i następującą segmentację semantyczną), które mogłyby być szkolone do przyjmowania wartości wyłącznie z postrzeganych obszarów skóry w celu podmiotu.
Autorzy sugerują również, że podobny paradygmat mógłby być zastosowany do wykrywania fałszywych połączeń audio, oraz że wykrywany dźwięk mógłby być odtwarzany w częstotliwości poza normalnym zakresem słyszenia ludzkiego.
Być może najbardziej interesujące jest to, że badacze sugerują, że rozszerzenie obszaru oceny poza twarzą w bogatszej ramie przechwytywania mogłoby znacznie poprawić możliwość wykrycia deepfake:
‘Bardziej zaawansowane szacowanie oświetlenia 3D prawdopodobnie dostarczyłoby bogatszy model wyglądu, który byłby jeszcze trudniejszy do obejścia przez fałszerza. Chociaż skupiliśmy się tylko na twarzy, wyświetlacz komputera również oświetla szyję, górne ciało i otoczenie, z których można by pobrać podobne pomiary.
‘Te dodatkowe pomiary zmusiłyby fałszerza do rozważenia całej sceny 3D, a nie tylko twarzy.’
* Moja konwersja cytatów wstawianych autorów na linki.
Pierwotnie opublikowane 6 lipca 2022.












