Sztuczna inteligencja
Auto-GPT & GPT-Engineer: Kompletny przewodnik po wiodących agentach AI dzisiejszych czasów

Porównując ChatGPT z autonomicznymi agentami AI, takimi jak Auto-GPT i GPT-Engineer, pojawia się znacząca różnica w procesie podejmowania decyzji. Podczas gdy ChatGPT wymaga aktywnego zaangażowania człowieka, aby prowadzić rozmowę, dostarczając wskazówki na podstawie sugestii użytkownika, proces planowania jest w dużej mierze zależny od interwencji człowieka.
Generative AI modele, takie jak transformery, są najnowocześniejszą technologią rdzenia, napędzającą te autonomiczne agenty AI. Te transformery są szkolone na dużych zbiorach danych, co pozwala im symulować złożone zdolności rozumowania i podejmowania decyzji.
Źródła Open-Source Autonomicznych Agentów: Auto-GPT i GPT-Engineer
Wiele z tych autonomicznych agentów AI pochodzi z inicjatyw open-source, prowadzonych przez innowacyjne osoby, które transformują konwencjonalne przepływy pracy. Zamiast po prostu oferować sugestie, agenci tacy jak Auto-GPT mogą niezależnie obsługiwać zadania, od zakupów online do tworzenia podstawowych aplikacji. OpenAI’s Code Interpreter ma na celu ulepszenie ChatGPT z prostego sugerowania pomysłów do aktywnego rozwiązywania problemów z tymi pomysłami.
Oba Auto-GPT i GPT-Engineer są wyposażone w moc GPT 3.5 i GPT-4. Chwytają logikę kodu, łączą wiele plików i przyspieszają proces rozwoju.
Jądro funkcjonalności Auto-GPT leży w jego agentach AI. Agenci ci są zaprogramowani do wykonywania konkretnych zadań, od nudnych, takich jak planowanie, do bardziej złożonych zadań, które wymagają strategicznego podejmowania decyzji. Jednak ci agenci AI działają w granicach ustalonych przez użytkowników. Kontrolując ich dostęp za pomocą API, użytkownicy mogą określać głębokość i zakres działań, które AI może wykonać.
Na przykład, jeśli zostanie im powierzone stworzenie aplikacji internetowej zintegrowanej z ChatGPT, Auto-GPT autonomicznie rozkłada cel na działania wykonalne, takie jak tworzenie frontendu HTML lub skryptu backendu Python. Podczas gdy aplikacja autonomicznie wytwarza te sugestie, użytkownicy mogą nadal monitorować i modyfikować je. Jak pokazał twórca AutoGPT @SigGravitas, jest on w stanie zbudować i wykonać program testowy na podstawie Python.
https://twitter.com/SigGravitas/status/1642181498278408193
Chociaż poniższy diagram opisuje bardziej ogólną architekturę autonomicznego agenta AI, zapewnia cenną wiedzę na temat procesów zachodzących za kulisami.

Architektura autonomicznego agenta AI
Proces jest inicjowany przez weryfikację klucza API OpenAI i inicjowanie różnych parametrów, w tym pamięci krótkotrwałej i zawartości bazy danych. Gdy kluczowe dane są przekazane do agenta, model wchodzi w interakcję z GPT3.5/GPT4, aby pobrać odpowiedź. Odpowiedź ta jest następnie przekształcana w format JSON, który agent interpretuje, aby wykonać różne funkcje, takie jak przeprowadzanie wyszukiwań online, odczytywanie lub zapisywanie plików, a nawet uruchamianie kodu. Auto-GPT wykorzystuje pre-trenowany model do przechowywania tych odpowiedzi w bazie danych, a przyszłe interakcje wykorzystują te przechowywane informacje jako odniesienie. Pętla trwa, aż zadanie zostanie uznane za kompletne.
Przewodnik konfiguracyjny dla Auto-GPT i GPT-Engineer
Konfigurowanie narzędzi typu cutting-edge, takich jak GPT-Engineer i Auto-GPT, może usprawnić proces rozwoju. Poniżej znajduje się ustrukturyzowany przewodnik, który pomoże Ci zainstalować i skonfigurować oba narzędzia.
Auto-GPT
Konfigurowanie Auto-GPT może wydawać się skomplikowane, ale z odpowiednimi krokami staje się prostsze. Ten przewodnik obejmuje procedurę konfigurowania Auto-GPT i zapewnia wgląd w jego różne scenariusze.
1. Wymagania wstępne:
- Środowisko Python: Upewnij się, że masz zainstalowany Python 3.8 lub nowszy. Możesz pobrać Python ze strony internetowej.
- Jeśli planujesz klonowanie repozytoriów, zainstaluj Git.
- Klucz API OpenAI: Aby wchodzić w interakcję z OpenAI, potrzebny jest klucz API. Pobierz klucz z Twojego konta OpenAI

Generowanie klucza API Open AI
Opcje tyłu pamięci: Tył pamięci służy jako mechanizm przechowywania dla AutoGPT, aby uzyskać dostęp do niezbędnych danych do jego operacji. AutoGPT wykorzystuje zarówno krótkotrwałe, jak i długotrwałe możliwości przechowywania. Pinecone, Milvus, Redis i inne są dostępnymi opcjami.
2. Konfigurowanie przestrzeni roboczej:
- Utwórz środowisko wirtualne:
python3 -m venv myenv - Aktywuj środowisko:
- MacOS lub Linux:
source myenv/bin/activate
- MacOS lub Linux:
3. Instalacja:
- Sklonuj repozytorium Auto-GPT (upewnij się, że masz zainstalowany Git):
git clone https://github.com/Significant-Gravitas/Auto-GPT.git - Aby upewnić się, że pracujesz z wersją 0.2.2 Auto-GPT, wykonaj checkout do tej wersji:
git checkout stable-0.2.2 - Przejdź do pobranego repozytorium:
cd Auto-GPT - Zainstaluj wymagane zależności:
pip install -r requirements.txt
4. Konfiguracja:
- Znajdź
.env.templatew głównym katalogu/Auto-GPT. Skopiuj i zmień nazwę na.env - Otwórz
.envi ustaw swój klucz API OpenAI obokOPENAI_API_KEY= - Podobnie, aby użyć Pinecone lub innych tyłów pamięci, zaktualizuj plik
.envz Twoim kluczem API Pinecone i regionem.
5. Polecenia wiersza poleceń:
Auto-GPT oferuje bogaty zestaw argumentów wiersza poleceń, aby dostosować jego zachowanie:
- Ogólne użycie:
- Wyświetl pomoc:
python -m autogpt --help - Dostosuj ustawienia AI:
python -m autogpt --ai-settings - Określ tył pamięci:
python -m autogpt --use-memory
- Wyświetl pomoc:

AutoGPT w CLI
6. Uruchamianie Auto-GPT:
Po zakończeniu konfiguracji zainicjuj Auto-GPT, używając:
- Linux lub Mac:
./run.sh start - Windows:
.run.bat
Integracja z Docker (Zalecany sposób konfiguracji)
Dla tych, którzy chcą konteneryzować Auto-GPT, Docker zapewnia usprawniony sposób. Należy jednak pamiętać, że początkowa konfiguracja Dockera może być nieco skomplikowana. Odwołaj się do przewodnika instalacji Dockera w celu uzyskania pomocy.
Przejdź do głównego katalogu AutoGPT i wykonaj poniższe kroki w terminalu
- Zbuduj obraz Dockera:
docker build -t autogpt . - Uruchom:
docker run -it --env-file=./.env -v$PWD/auto_gpt_workspace:/app/auto_gpt_workspace autogpt
Z docker-compose:
- Uruchom:
docker-compose run --build --rm auto-gpt - Dla dodatkowej personalizacji możesz zintegrować dodatkowe argumenty. Na przykład, aby uruchomić z –gpt3only i –continuous:
docker-compose run --rm auto-gpt --gpt3only--continuous - Biorąc pod uwagę obszerną autonomię Auto-GPT w generowaniu treści z dużych zbiorów danych, istnieje potencjalne ryzyko, że może on nieumyślnie uzyskać dostęp do niebezpiecznych źródeł internetowych.
- Definicja sugestii: Stwórz szczegółowy opis swojego projektu, używając języka naturalnego.
- Generowanie kodu: Na podstawie Twojej sugestii GPT-Engineer generuje fragmenty kodu, funkcje lub nawet całe aplikacje.
- Udoskonalenie i optymalizacja: Po generowaniu kodu istnieje zawsze miejsce na udoskonalenie. Deweloperzy mogą modyfikować wygenerowany kod, aby spełnić określone wymagania, zapewniając najwyższą jakość.
- Utwórz nowy katalog o nazwie ‘website’:
mkdir website - Przejdź do katalogu:
cd website - Dla macOS/Linux:
source venv/bin/activate - Dla Windows, jest to nieco inne z powodu ustawień klucza API:
set OPENAI_API_KEY=[twój klucz api] - Dla macOS/Linux:
export OPENAI_API_KEY=[twój klucz api] - Dla Windows (jak wcześniej):
set OPENAI_API_KEY=[twój klucz api] - Jeśli chcesz zainicjować nowy projekt:
cp -r projects/example/ projects/website - Edytuj plik
main_prompt, używając edytora tekstu, i opisz wymagania Twojego projektu. - Gdy będziesz zadowolony z sugestii, uruchom:
gpt-engineer projects/website - Limit twardy: Ogranicza użycie poza Twoim progiem.
- Limit miękki: Wysyła Ci powiadomienie e-mail, gdy zostanie osiągnięty próg.
- Pozytywne aspekty: AI może zautomatyzować wiele zadań, od obsługi klienta po porady finansowe, dając ulgę małym przedsiębiorstwom, które nie mają środków na dedykowane zespoły.
- Obawy: Korzyść z automatyzacji podnosi brwi w kwestii potencjalnych strat pracy, szczególnie w sektorach, gdzie zaangażowanie ludzkie jest niezbędne, takich jak obsługa klienta. Wraz z tym idzie labirynt etyczny związany z dostępem AI do poufnych danych. To wymaga silnej infrastruktury, zapewniającej przejrzystość, odpowiedzialność i etyczne użytkowanie AI.
</ul)
Aby zminimalizować ryzyko, operuj Auto-GPT w kontenerze wirtualnym, takim jak Docker. Zapewnia to, że wszelkie potencjalnie szkodliwe treści pozostają zawarte w przestrzeni wirtualnej, pozostawiając Twoje zewnętrzne pliki i system nietknięte. Alternatywnie, Windows Sandbox jest opcją, chociaż resetuje się po każdej sesji, nie zachowując swojego stanu.
Dla bezpieczeństwa zawsze uruchamiaj Auto-GPT w środowisku wirtualnym, zapewniając, że Twój system pozostaje izolowany od nieoczekiwanych wyników.
Biorąc pod uwagę wszystko to, nadal istnieje szansa, że nie uzyskasz pożądanych wyników. Użytkownicy Auto-GPT zgłaszali powtarzające się problemy podczas prób zapisu do pliku, często napotykając nieudane próby z powodu problematycznych nazw plików. Oto jeden z takich błędów: Auto-GPT (wydanie 0.2.2) nie dołącza tekstu po błędzie "write_to_file returned: Error: Plik został już zaktualizowany
Różne rozwiązania, aby rozwiązać ten problem, są omawiane na powiązanym wątku GitHub do odniesienia.
GPT-Engineer
Przepływ pracy GPT-Engineer:
Proces konfigurowania GPT-Engineer został skondensowany w łatwy do naśladowania przewodnik. Oto krok po kroku:
1. Przygotowanie środowiska: Przed rozpoczęciem upewnij się, że masz przygotowany katalog projektu. Otwórz terminal i uruchom poniższą komendę
2. Sklonuj repozytorium: git clone https://github.com/AntonOsika/gpt-engineer.git .
3. Przejdź i zainstaluj zależności: Po sklonowaniu przejdź do katalogu cd gpt-engineer i zainstaluj wszystkie niezbędne zależności make install
4. Aktywuj środowisko wirtualne: W zależności od Twojego systemu operacyjnego, aktywuj utworzone środowisko wirtualne.
5. Konfiguracja – Ustawienie klucza API: Aby wchodzić w interakcję z OpenAI, potrzebny jest klucz API. Jeśli jeszcze go nie masz, zarejestruj się na platformie OpenAI, a następnie:
6. Inicjacja projektu i generowanie kodu: Magia GPT-Engineer zaczyna się od pliku main_prompt znalezionego w folderze projects .
Tu zastąp ‘website’ swoją wybraną nazwą projektu.

Twój wygenerowany kod będzie rezydował w katalogu workspace wnętrz folderu projektu.
7. Po generowaniu: Chociaż GPT-Engineer jest potężny, może nie zawsze być idealny. Zbadaj wygenerowany kod, wprowadź ręczne zmiany, jeśli są potrzebne, i upewnij się, że wszystko działa gładko.
Przykładowy przebieg
Sugestia:
“Chcę opracować podstawową aplikację Streamlit w Pythonie, która wizualizuje dane użytkownika za pomocą interaktywnych wykresów. Aplikacja powinna umożliwiać użytkownikom przesyłanie pliku CSV, wybór typu wykresu (np. słupkowego, kołowego, liniowego) i dynamiczną wizualizację danych. Może wykorzystywać biblioteki takie jak Pandas do manipulacji danymi i Plotly do wizualizacji.”
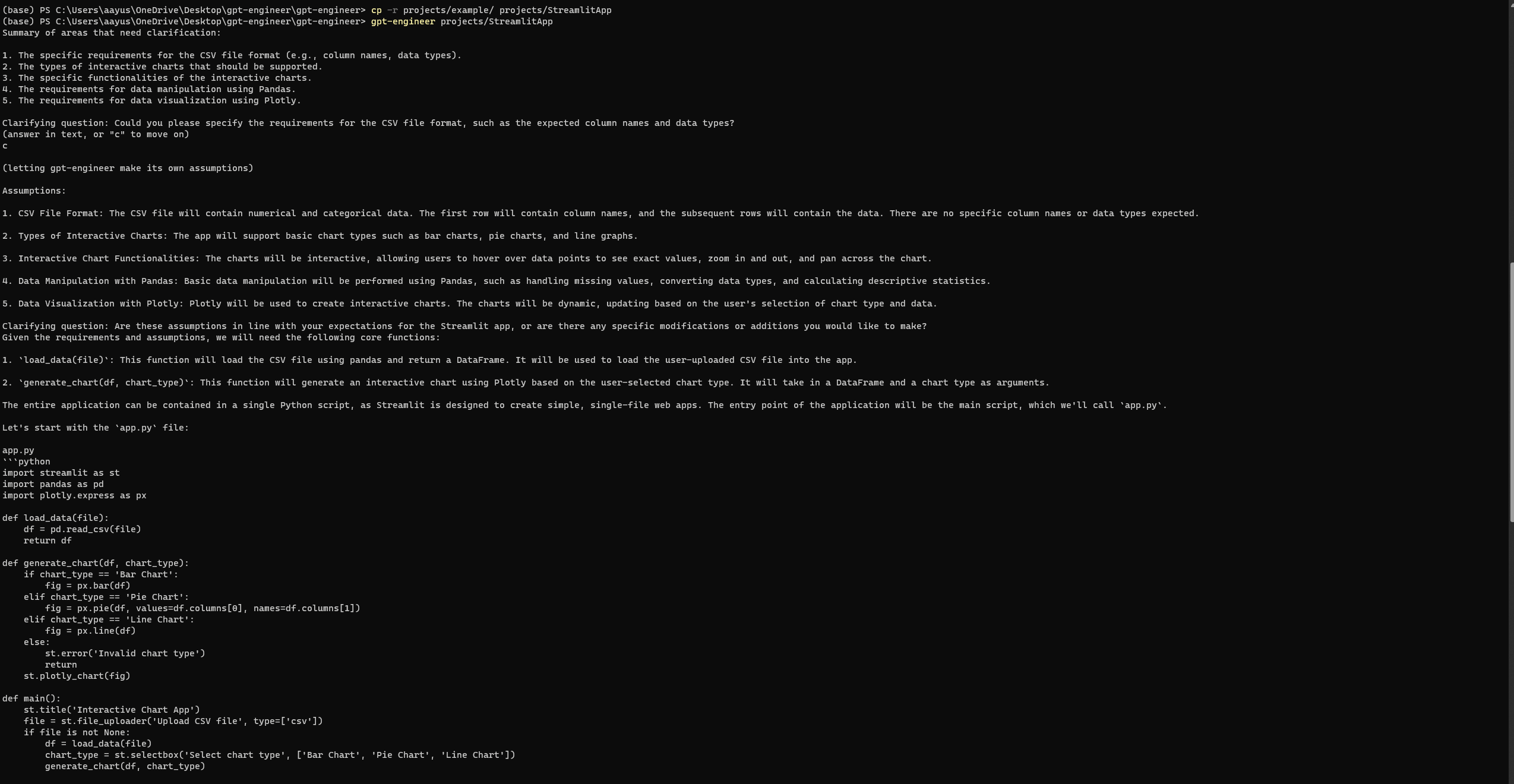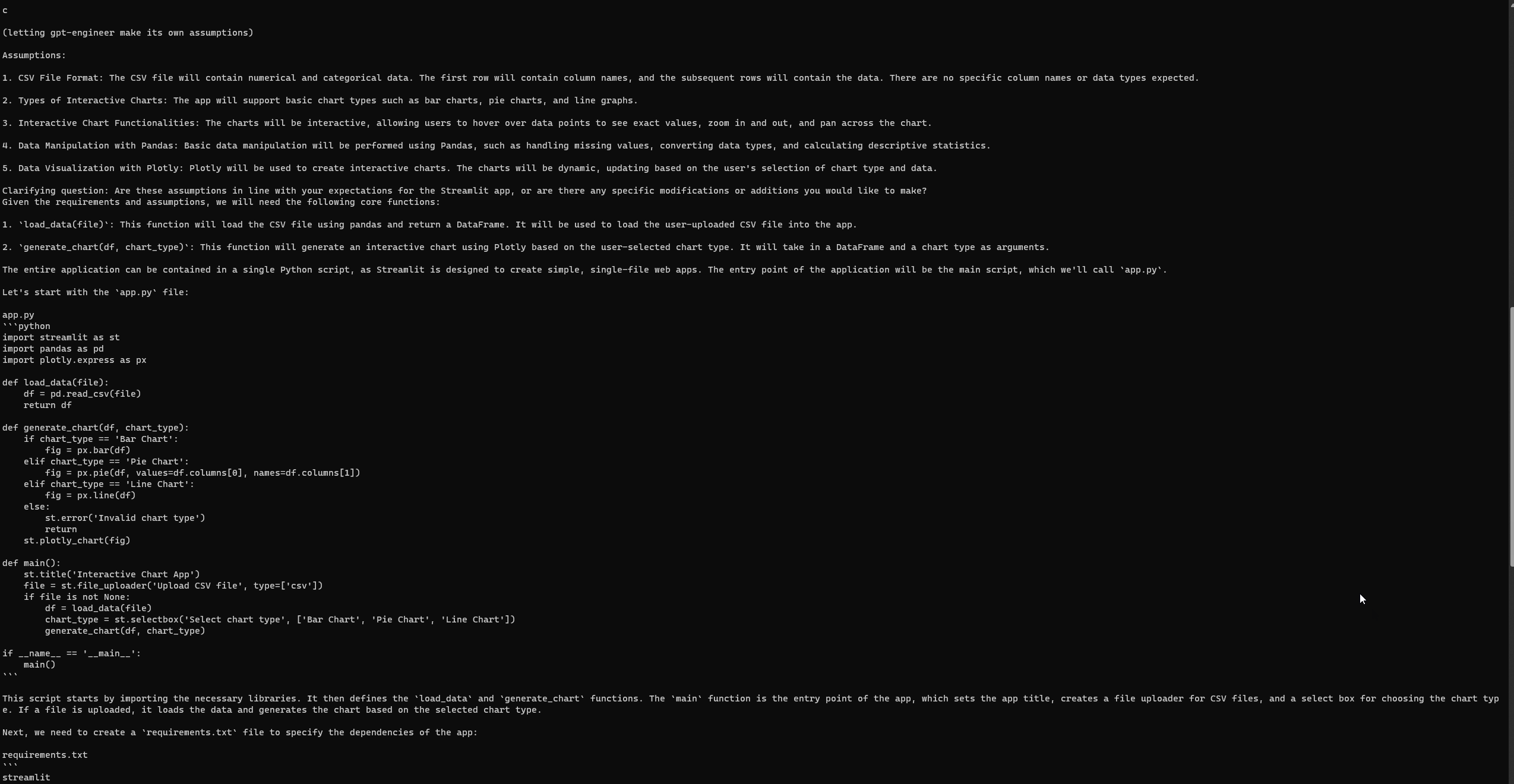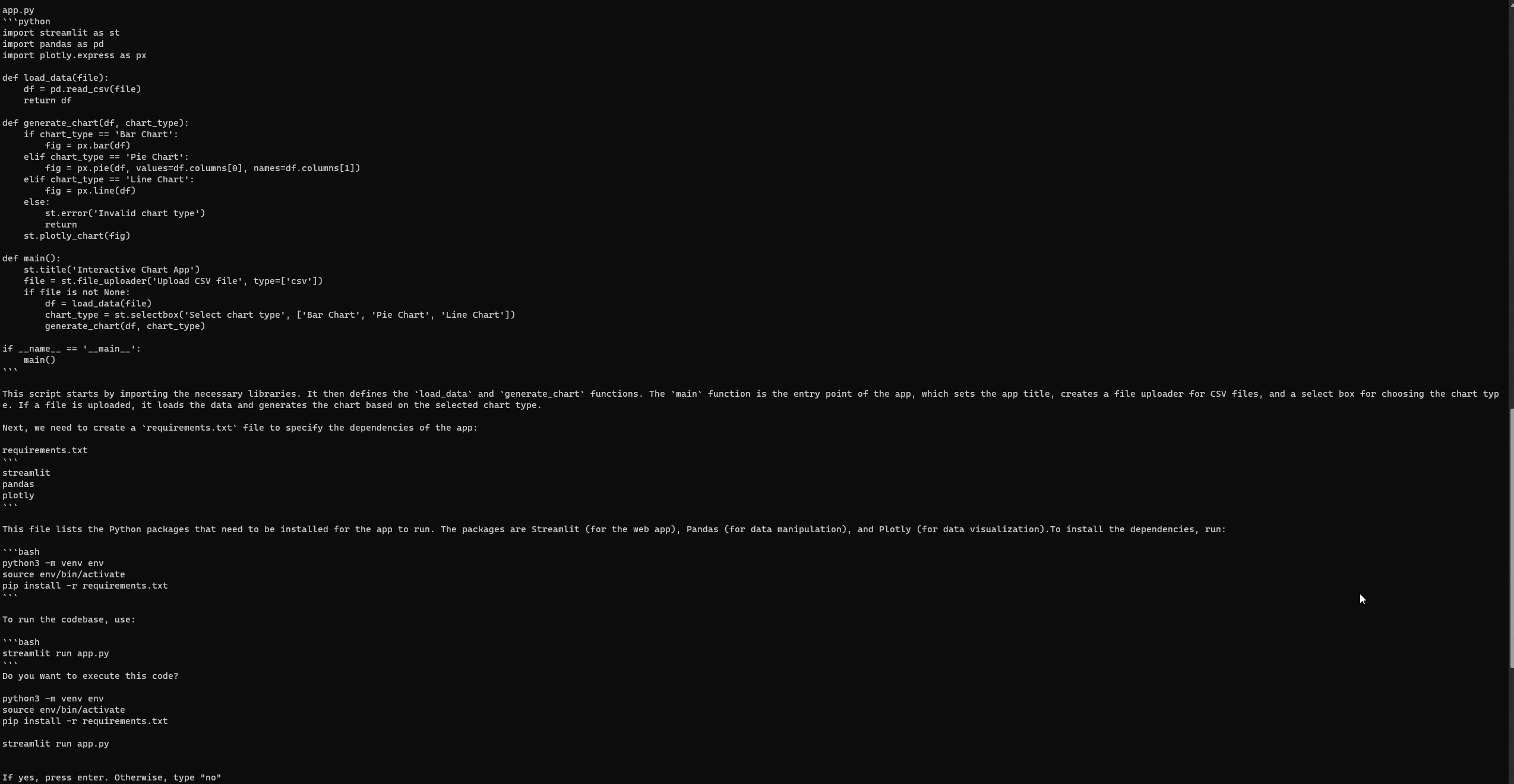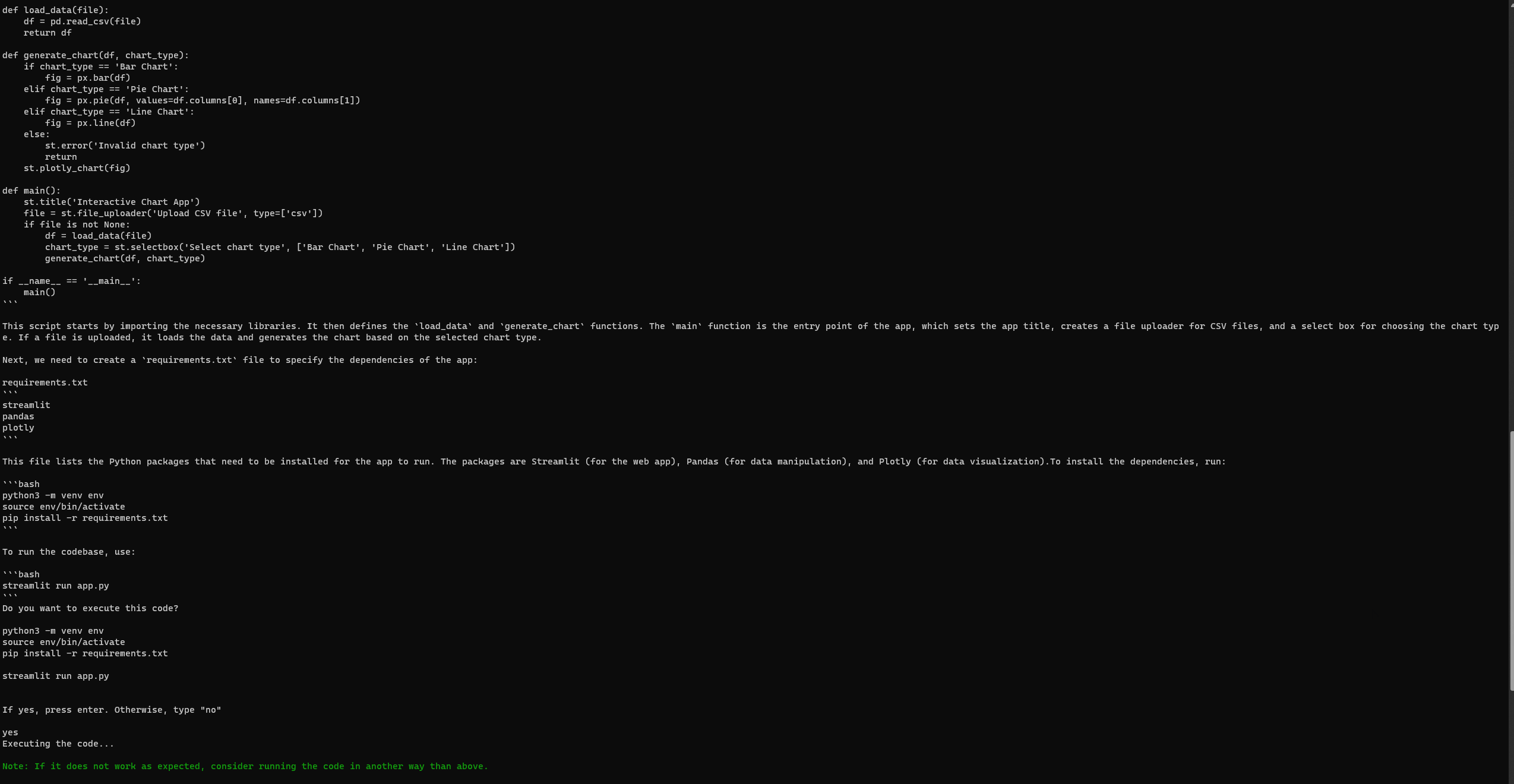
Konfigurowanie i uruchamianie GPT-Engineer
Podobnie jak Auto-GPT, GPT-Engineer może czasami napotkać błędy, nawet po pełnej konfiguracji. Jednak przy moim trzecim podejściu pomyślnie uzyskałem dostęp do następnej strony internetowej Streamlit. Upewnij się, że przeglądasz wszelkie błędy na oficjalnej stronie problemów GPT-Engineer.

Aplikacja Streamlit wygenerowana przy użyciu GPT-Engineer
Bieżące wąskie gardła agentów AI
Koszty operacyjne
Jedno zadanie wykonywane przez Auto-GPT może składać się z wielu kroków. Co więcej, każdy z tych kroków może być fakturyzowany indywidualnie, zwiększając koszty. Auto-GPT może utknąć w pętlach powtarzalnych, nie dostarczając obiecanych wyników. Tego rodzaju zdarzenia podważają jego niezawodność i podkopują inwestycję.
Wyobraź sobie, że chcesz stworzyć krótki esej z Auto-GPT. Idealna długość eseju to 8K tokenów, ale podczas tworzenia model wchodzi w interakcję z wieloma pośrednimi krokami, aby sfinalizować treść. Jeśli używasz GPT-4 z długością kontekstu 8k, to za dane wejściowe zostaniesz obciążony 0,03$. A za dane wyjściowe koszt wyniesie 0,06$. Teraz, powiedzmy, że model wpada w nieprzewidzianą pętlę, powtarzając pewne części wiele razy. Nie tylko proces staje się dłuższy, ale każde powtórzenie również dodaje do kosztu.
Aby zabezpieczyć się przed tym:
Ustaw limity użycia w OpenAI Billing & Limits:
Ograniczenia funkcjonalne
Możliwości Auto-GPT, jak przedstawiono w jego kodzie źródłowym, mają pewne granice. Jego strategie rozwiązywania problemów są rządzone przez jego wewnętrzne funkcje i dostępność zapewnianą przez API GPT-4. Dla głębszych dyskusji i możliwych rozwiązań rozważ odwiedzenie: Dyskusja Auto-GPT.
Wpływ AI na rynek pracy
Dynamiczna relacja między AI a rynkiem pracy jest nieustannie ewoluująca i jest obszernie udokumentowana w tym artykule badawczym. Kluczowym wnioskiem jest to, że podczas gdy postęp technologiczny często korzysta pracownikom wykwalifikowanym, niesie ze sobą ryzyko dla tych zaangażowanych w zadania rutynowe. W rzeczywistości postęp technologiczny może zastąpić pewne zadania, ale jednocześnie toruje drogę do zróżnicowanych, pracochłonnych zadań.

Szacuje się, że około 80% amerykańskich pracowników może stwierdzić, że LLM (modele językowe) wpływają na około 10% ich codziennych zadań. Ta statystyka podkreśla łączenie się AI i ról ludzkich.
Podwójna rola AI w siłach roboczych:
Podsumowanie
Jasne, że narzędzia takie jak ChatGPT, Auto-GPT i GPT-Engineer stoją na czele przebudowywania interakcji między technologią a jej użytkownikami. Z korzeniami w ruchach open-source, ci agenci AI ujawniają możliwości autonomii maszyn, usprawniając zadania od planowania do rozwoju oprogramowania.
Gdy wkraczamy w przyszłość, w której AI integruje się głębiej w nasze codzienne rutyny, równowaga między przyjęciem możliwości AI a ochroną ról ludzkich staje się kluczowa. Na szerszym spektrum dynamiczna relacja między AI a rynkiem pracy maluje podwójne obrazy szans rozwojowych i wyzwań, wymagając świadomej integracji etyki technologicznej i przejrzystości.












