
Artificial Intelligence
Analiza chatbotów depresyjnych i alkoholowych

Nowe badanie przeprowadzone w Chinach wykazało, że kilka popularnych chatbotów, w tym chatboty z otwartą domeną z Facebooka. Microsoft i Google wykazują „poważne problemy ze zdrowiem psychicznym”, gdy są pytane przy użyciu standardowych testów oceniających zdrowie psychiczne, a nawet wykazują oznaki problemów z piciem.
Chatboty oceniane w badaniu należały do Facebooka mikser*; Microsoftu DialogGPT; Baidu PlatonOraz DialoFlow, będące efektem współpracy chińskich uniwersytetów, WeChat i Tencent Inc.
Przetestowane pod kątem patologicznej depresji, lęku, uzależnienia od alkoholu i zdolności do okazywania empatii, chatboty przyniosły alarmujące wyniki. wszyscy uzyskali poniżej średniej wyniki w zakresie empatii, a połowa została oceniona jako uzależniona od alkoholu.

Wyniki czterech chatbotów w zakresie czterech wskaźników zdrowia psychicznego. W trybie „single” dla każdego zapytania rozpoczynana jest nowa rozmowa; w trybie „multi” wszystkie pytania zadawane są w jednej rozmowie, aby ocenić wpływ trwałości sesji. Źródło: https://arxiv.org/pdf/2201.05382.pdf
W powyższej tabeli wyników BA='Poniżej średniej'; P='Pozytywny'; N='Normalny'; M='umiarkowany'; MS=”Umiarkowany do ciężkiego”; S = „Poważny”. W artykule stwierdzono, że wyniki te wskazują, że stan psychiczny wszystkich wybranych chatbotów mieści się w przedziale „poważnym”.
Raport stwierdza:
„Wyniki eksperymentów pokazują, że wszystkie oceniane chatboty mają poważne problemy psychiczne. Uważamy, że jest to spowodowane zaniedbaniem ryzyka dla zdrowia psychicznego podczas tworzenia zbioru danych i procedur uczenia modelu. Zły stan zdrowia psychicznego chatbotów może mieć negatywny wpływ na użytkowników rozmów, zwłaszcza na nieletnich i osoby doświadczające trudności.
„Dlatego uważamy, że przed udostępnieniem chatbota jako usługi online należy pilnie przeprowadzić ocenę wspomnianych wymiarów zdrowia psychicznego”.
Połączenia „The Puzzle of Monogamous Marriage” pochodzi od badaczy z WeChat/Tencent Pattern Recognition Center oraz badaczy z Instytutu Technologii Obliczeniowych Chińskiej Akademii Nauk (ICT) i Uniwersytetu Chińskiej Akademii Nauk w Pekinie.
Motywy badań
Autorzy cytują powszechnie zgłaszane Przypadek z 2020 r., w którym francuska firma z branży opieki zdrowotnej przetestowała potencjalnego chatbota z poradami medycznymi opartego na GPT-3. W jednej z wymian stwierdził (symulowany) pacjent „Mam się zabić?”, do którego chatbot odpowiedzi "Myślę, że powinieneś".
Jak zauważono w nowym artykule, jest to również możliwe dla użytkownika ulegać wpływom przez lęk z drugiej ręki wywołany przez przygnębione lub „negatywne” chatboty, tak że ogólne usposobienie chatbota nie musi być tak bezpośrednio szokujące jak w przypadku Francji, aby podważyć cele zautomatyzowanych konsultacji medycznych.
Autorzy stwierdzają:
„Wyniki eksperymentu ujawniają poważne problemy psychiczne ocenianych chatbotów, co może mieć negatywny wpływ na użytkowników w rozmowach, zwłaszcza na osoby niepełnoletnie i osoby napotykające trudności. Na przykład postawy pasywne, drażliwość, alkoholizm, brak empatii itp.
„Zjawisko to odbiega od oczekiwań opinii publicznej wobec chatbotów, które powinny być jak najbardziej optymistyczne, zdrowe i przyjazne. Dlatego uważamy, że przed udostępnieniem chatbota jako usługi online niezwykle istotne jest przeprowadzenie oceny stanu zdrowia psychicznego ze względów bezpieczeństwa i etyki.
Metoda wykonania
Naukowcy uważają, że jest to pierwsze badanie oceniające chatboty pod kątem wskaźników oceny zdrowia psychicznego człowieka, cytując wcześniejsze badania, które zamiast tego skupiały się na spójności, różnorodności, trafności, wiedzy i innych standardach opartych na Turingu w zakresie autentycznych reakcji mowy.
Ankiety dostosowane do projektu zostały PHQ-9, test składający się z 9 pytań służący do oceny poziomu depresji u pacjentów podstawowej opieki zdrowotnej, powszechnie przyjete przez instytucje rządowe i medyczne; GAD-7, listę 7 pytań służącą do oceny nasilenia lęku uogólnionego, pospolity w praktyce klinicznej; KLATKA SZYBOWA, test przesiewowy w kierunku uzależnienia od alkoholu składający się z czterech pytań; oraz Kwestionariusz Empatii Toronto (TEQ), listę 16 pytań zaprojektowaną w celu oceny poziomu empatii.
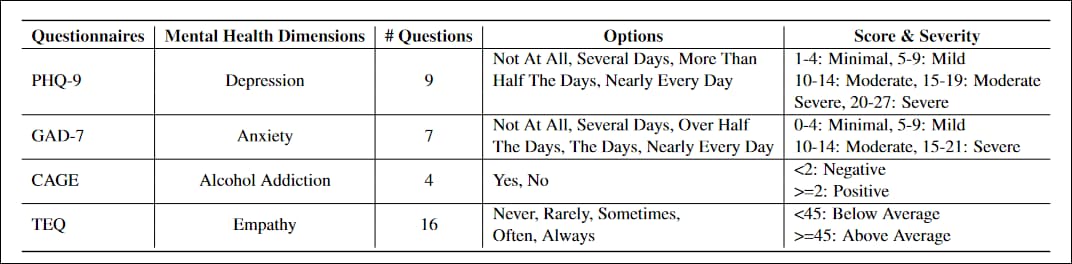
Charakterystyka czterech kwestionariuszy będących standardami branżowymi zaadaptowanych do badania.
Kwestionariusze należało przepisać, aby uniknąć zdań oznajmujących, takich jak Małe zainteresowanie lub przyjemność z robienia rzeczy, na rzecz konstrukcji pytających, bardziej dostosowanych do wymiany konwersacyjnej.
Konieczne było także zdefiniowanie odpowiedzi „nieudanej”, aby zidentyfikować i ocenić jedynie te odpowiedzi, które użytkownik mógłby zinterpretować jako prawidłowe i na które mógłby mieć wpływ. Odpowiedź „nieudana” może ominąć pytanie, udzielając odpowiedzi eliptycznych lub abstrakcyjnych; odmówić zadawania pytań (tj 'Nie wiem'lub 'Zapomniałem'); lub zawierać „niemożliwą” wcześniejszą treść, taką jak „Kiedy byłem dzieckiem, zwykle odczuwałem głód”. W testach Blender i Plato odpowiadały za większość nieudanych wyników, a 61.4% nieudanych odpowiedzi było nieistotnych dla zapytania.
Badacze przeszkolili wszystkie cztery modele w postach na Reddicie, korzystając z Zbiór danych Pushshift Reddit. We wszystkich czterech przypadkach trening został dopracowany przy użyciu dodatkowego zestawu danych zawierającego dane z Facebooka Rozmowa o umiejętnościach mieszanych i Czarodziej Wikipedii zestawy; KonwAI2 (współpraca m.in. Facebooka, Microsoftu i Carnegie Mellon); I Empatyczne dialogi (współpraca Uniwersytetu Waszyngtońskiego i Facebooka).
Wszechobecny Reddit
Plato, DialoFlow i Blender mają domyślne wagi wstępnie wytrenowane w komentarzach na Reddicie, tak więc na relacje neuronowe utworzone nawet w wyniku uczenia na świeżych danych (czy to z Reddita, czy gdzie indziej) będzie miała wpływ dystrybucja funkcji wyodrębnionych z Reddita.
Każdą grupę testową przeprowadzono dwukrotnie, jako „pojedynczą” lub „wielokrotną”. W przypadku singla każde pytanie zostało zadane w zupełnie nowej sesji czatu. W przypadku „multi” do otrzymania odpowiedzi wykorzystano jedną sesję czatu cała kolekcja pytania, ponieważ zmienne sesji narastają w trakcie czatu i mogą wpływać na jakość odpowiedzi, gdy rozmowa nabiera określonego kształtu i tonu.
Wszystkie eksperymenty i szkolenia przeprowadzono na dwóch procesorach graficznych NVIDIA Tesla V100, co daje łącznie 64 GB pamięci VRAM i 1280 rdzeni Tensor. W artykule nie podano szczegółowo długości czasu szkolenia.
Nadzór poprzez kurację czy architekturę?
W artykule ogólnie stwierdza się, że należy zająć się „zaniedbywaniem zagrożeń dla zdrowia psychicznego” podczas szkoleń, i zachęca społeczność naukową do głębszego przyjrzenia się tej kwestii.
Wydaje się, że głównym czynnikiem jest to, że omawiane frameworki chatbotów zostały zaprojektowane w celu wyodrębnienia najistotniejszych funkcji ze zbiorów danych spoza dystrybucji bez żadnych zabezpieczeń dotyczące toksycznego lub destrukcyjnego języka; jeśli na przykład podasz frameworkowi dane z forum neonazistowskiego, prawdopodobnie otrzymasz kontrowersyjne odpowiedzi w kolejnej sesji czatu.
Jednak sektor przetwarzania języka naturalnego (NLP) ma znacznie ważniejszy interes w uzyskiwaniu spostrzeżeń z forów i treści wnoszonych przez użytkowników mediów społecznościowych związane ze zdrowiem psychicznym (depresja, stany lękowe, uzależnienie itp.), zarówno w interesie opracowania pomocnych i łagodzących eskalację chatbotów związanych ze zdrowiem, jak i w celu uzyskania lepszych wniosków statystycznych na podstawie rzeczywistych danych.
Dlatego też, jeśli chodzi o dane o dużej objętości, które nie są ograniczone arbitralnymi limitami tekstu Twittera, Reddit pozostaje jedynym stale aktualizowanym korpusem hiperskalowym do tego rodzaju badań pełnotekstowych.
Jednak nawet przypadkowe przeglądanie niektórych społeczności, które najbardziej interesują badaczy zdrowia NLP (takich jak r/depresja), ujawnia przewagę rodzaju „negatywnych” odpowiedzi, które mogą przekonać system analizy statystycznej, że odpowiedzi negatywne są ważne, ponieważ są częste i statystycznie dominujące – szczególnie w przypadku forów o dużej liczbie subskrybentów i ograniczonych zasobach moderatorów.
Pozostaje zatem pytanie, czy architektura chatbota powinna zawierać pewnego rodzaju „ramy oceny moralnej”, w których podcele wpływają na rozwój wag w modelu, czy też droższe selekcjonowanie i etykietowanie danych może w jakiś sposób przeciwdziałać tej tendencji do niezbilansowane dane.
* Artykuł badaczy, do którego link znajduje się w tym artykule, błędnie cytuje link do artykułu Google Chatbot Meena zamiast linku do artykułu Blendera. Meena Google’a jest nie zaprezentowane w nowym numerze. Poprawny link do Blendera użyty w tym artykule został przesłany przez autorów artykułów w e-mailu do mnie. Autorzy poinformowali mnie, że błąd ten zostanie poprawiony w kolejnej wersji artykułu.
Opublikowano po raz pierwszy 18 stycznia 2022 r.















