
Artificial Intelligence
Sztuczna inteligencja pomaga zdenerwowanym mówcom „czytać pomieszczenie” podczas wideokonferencji

W 2013 roku badanie dotyczące powszechnych fobii wykazało, że perspektywa wystąpień publicznych jest taka gorsza niż perspektywa śmierci dla większości respondentów. Zespół ten jest tzw glosofobia.
Napędzany przez Covid migracja od spotkań „osobistych” po konferencje online na platformie Zoom i Google Spaces, co zaskakujące, nie poprawiło sytuacji. Tam, gdzie w spotkaniu bierze udział duża liczba uczestników, nasze naturalne zdolności oceny zagrożeń są osłabiane przez rzędy i ikony uczestników o niskiej rozdzielczości oraz trudności w odczytywaniu subtelnych sygnałów wizualnych wyrazu twarzy i mowy ciała. Na przykład Skype okazał się słabą platformą do przekazywania sygnałów niewerbalnych.
Wpływ postrzeganego zainteresowania i szybkości reakcji na wystąpienia publiczne jest następujący: dobrze udokumentowane już teraz i intuicyjnie oczywiste dla większości z nas. Nieprzejrzysta reakcja publiczności może spowodować, że mówcy zawahają się i cofną do celu przemówienie wypełniające, nieświadomi, czy ich argumenty spotykają się ze zgodą, pogardą czy brakiem zainteresowania, co często powoduje niewygodne doświadczenie zarówno dla mówiącego, jak i słuchaczy.
Pod presją nieoczekiwanego przejścia na wideokonferencje online zainspirowanego ograniczeniami i środkami ostrożności związanymi z Covid-19, problem prawdopodobnie się pogłębia, a w wizji komputerowej zaproponowano szereg łagodzących systemów informacji zwrotnej od publiczności, które w ciągu ostatnich kilku lat wpłynęły na społeczności badawcze.
Rozwiązania skoncentrowane na sprzęcie
Większość z nich obejmuje jednak dodatkowy sprzęt lub złożone oprogramowanie, które może powodować problemy związane z prywatnością lub logistyką – co oznacza stosunkowo wysokie koszty lub w inny sposób ograniczone zasoby style podejścia, które istniały jeszcze przed pandemią. W 2001 roku MIT zaproponował Galwanaktywator, noszone na dłoni urządzenie, które wnioskuje o stanie emocjonalnym uczestnika widowni, testowane podczas całodniowego sympozjum.

Od 2001 r. Galvactivator MIT, który mierzy reakcję przewodności skóry, próbując zrozumieć nastroje i zaangażowanie publiczności. Źródło: https://dam-prod.media.mit.edu/x/files/pub/tech-reports/TR-542.pdf
Wiele energii akademickiej poświęcono także temu, co możliwe wdrożenie „klikerów” jako system reakcji publiczności (ARS), środek zwiększający aktywne uczestnictwo publiczności (co automatycznie zwiększa zaangażowanie, ponieważ zmusza widza do pełnienia roli aktywnego węzła informacji zwrotnej), ale który został również pomyślany jako środek zachęcający mówcę .
Uwzględniono inne próby „połączenia” mówcy i publiczności monitorowanie tętna, wykorzystanie złożonego sprzętu noszonego na ciele w celu wykorzystania elektroencefalografii, „mierniki radości”, oparte na wizji komputerowej rozpoznawanie emocji dla pracowników siedzących przy biurku i korzystania z odbiorców wysyłanych emotikony podczas przemówienia prelegenta.

Od 2017 r. EngageMeter, wspólny projekt badań akademickich LMU Monachium i Uniwersytetu w Stuttgarcie. Źródło: http://www.mariamhassib.net/pubs/hassib2017CHI_3/hassib2017CHI_3.pdf
W ramach dodatkowej działalności w lukratywnej dziedzinie analityki widowni, sektor prywatny szczególnie zainteresował się szacowaniem i śledzeniem spojrzeń – systemami, w których każdy widz (który z kolei może w końcu być zmuszony zabrać głos) podlega śledzenie wzroku jako wyraz zaangażowania i aprobaty.
Wszystkie te metody charakteryzują się dość dużym tarciem. Wiele z nich wymaga dostosowanego do indywidualnych potrzeb sprzętu, środowisk laboratoryjnych, specjalistycznych i niestandardowych platform oprogramowania oraz subskrypcji drogich komercyjnych interfejsów API – lub dowolnej kombinacji tych ograniczających czynników.
Dlatego też w ciągu ostatnich 18 miesięcy w centrum zainteresowania stał się rozwój minimalistycznych systemów opartych na niczym więcej niż powszechnych narzędziach do wideokonferencji.
Dyskretne zgłaszanie aprobaty publiczności
W tym celu w ramach nowej współpracy badawczej pomiędzy Uniwersytetem Tokijskim a Uniwersytetem Carnegie Mellon zaoferowano nowatorski system, który można wykorzystać w standardowych narzędziach do wideokonferencji (takich jak Zoom) przy użyciu wyłącznie witryny internetowej wyposażonej w kamerę internetową, na której można lekko patrzeć i pozować oprogramowanie do estymacji jest uruchomione. W ten sposób unika się nawet konieczności stosowania lokalnych wtyczek do przeglądarek.
Kiwnięcia głową użytkownika i szacunkowa uwaga wzrokowa są przekładane na reprezentatywne dane, które są wizualizowane z powrotem do mówiącego, co pozwala na „na żywo” papierek lakmusowy określający stopień, w jakim treść angażuje odbiorców – a także przynajmniej niejasny wskaźnik okresów dyskursu, w którym mówca może stracić zainteresowanie publiczności.
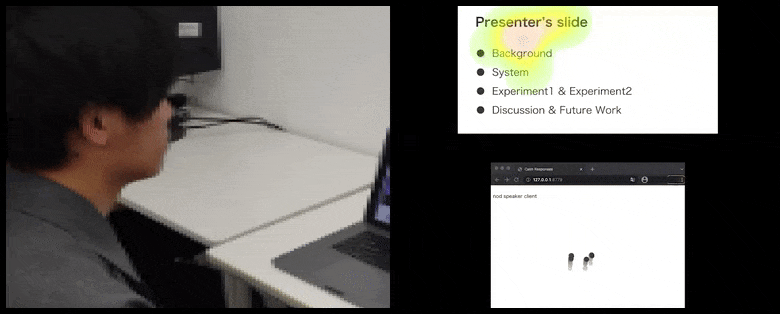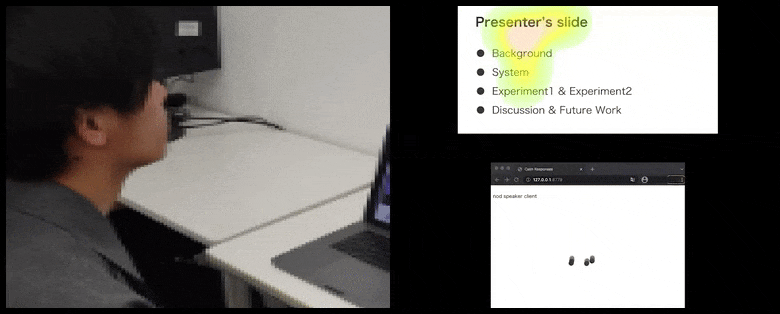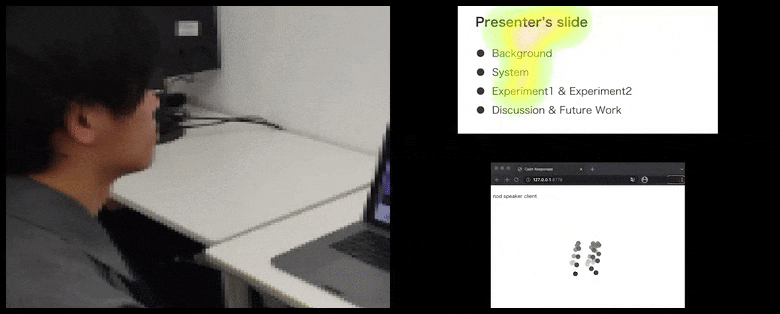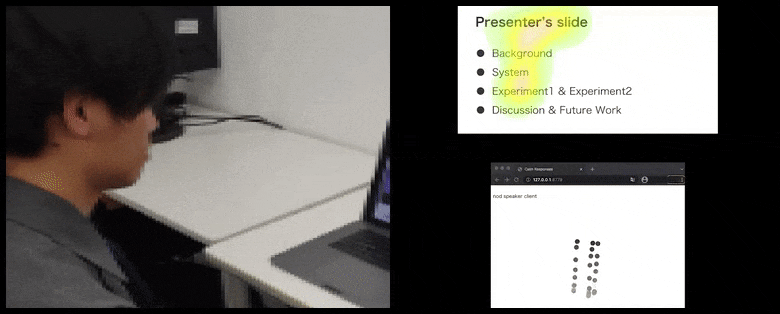
Dzięki CalmResponses uwaga użytkownika i kiwanie głową są dodawane do puli opinii publiczności i przekładane na wizualną reprezentację, która może przynieść korzyści mówcy. Więcej szczegółów i przykładów można znaleźć w osadzonym filmie wideo na końcu artykułu. Źródło: https://www.youtube.com/watch?v=J_PhB4FCzk0
W wielu sytuacjach akademickich, takich jak wykłady online, studenci mogą być całkowicie niewidoczni dla mówcy, ponieważ nie włączyli kamer ze względu na nieświadomość swojego pochodzenia lub obecnego wyglądu. CalmResponses może rozwiązać tę drażliwą przeszkodę w uzyskiwaniu informacji zwrotnych od mówcy, zgłaszając, co wie o tym, jak mówca patrzy na treść i czy kiwa głową, bez konieczności włączania kamery przez widza.
Połączenia papier jest zatytułowany CalmResponses: Wyświetlanie zbiorowych reakcji publiczności w komunikacji zdalneji jest wspólnym dziełem dwóch badaczy z UoT i jednego z Carnegie Mellon.
Autorzy oferują demo na żywo w Internecie i wydali wersję demonstracyjną kod źródłowy w GitHubie.
Struktura CalmResponses
Zainteresowanie firmy CalmResponses kiwaniem głową w przeciwieństwie do innych możliwych pozycji głowy opiera się na badaniach (niektóre z nich chwalą powrót do epoki Darwina), co wskazuje, że ponad 80% ruchów głowy wszystkich słuchaczy polegają na kiwaniu głową (nawet jeśli są wyrażając sprzeciw). Jednocześnie pokazano ruchy oczu koniec liczny badania naukowe być wiarygodnym wskaźnikiem zainteresowania lub zaangażowania.
CalmResponses jest zaimplementowany w HTML, CSS i JavaScript i składa się z trzech podsystemów: klienta odbiorców, klienta mówiącego i serwera. Klienci odbiorców przesyłają dane dotyczące wzroku lub ruchu głowy z kamery internetowej użytkownika za pośrednictwem protokołu WebSockets za pośrednictwem platformy aplikacji w chmurze Heroku.

Kiwająca głową publiczność wizualizowana po prawej stronie w animowanym ruchu w sekcji CalmResponses. W tym przypadku wizualizacja ruchu jest dostępna nie tylko dla mówiącego, ale dla całej publiczności. Źródło: https://arxiv.org/pdf/2204.02308.pdf
W części projektu dotyczącej śledzenia wzroku naukowcy wykorzystali WebGazer, lekka, oparta na JavaScript, oparta na przeglądarce platforma do śledzenia wzroku, która może działać z niskim opóźnieniem bezpośrednio ze strony internetowej (patrz link powyżej do własnej implementacji internetowej badaczy).
Ponieważ potrzeba prostej implementacji i przybliżonego, zbiorczego rozpoznawania odpowiedzi przewyższa potrzebę dużej dokładności szacowania spojrzeń i pozycji, dane wejściowe dotyczące pozycji są wygładzane zgodnie ze średnimi wartościami, zanim zostaną uwzględnione w ogólnym oszacowaniu odpowiedzi.
Akcja kiwania głową jest oceniana za pośrednictwem biblioteki JavaScript clmtrackr, który dopasowuje modele twarzy do twarzy wykrytych na zdjęciach lub filmach uregulowane przesunięcie średnie punktu orientacyjnego. Ze względu na oszczędność i małe opóźnienia w implementacji autorów aktywnie monitoruje się tylko wykryty punkt orientacyjny dla nosa, ponieważ wystarczy to do śledzenia działań związanych z kiwaniem głową.
Ruch pozycji czubka nosa użytkownika tworzy ślad, który wpływa na pulę reakcji publiczności związanych z kiwaniem głową, wizualizowaną w sposób zbiorczy wszystkim uczestnikom.
Mapa ciepła
Podczas gdy czynność kiwania głową jest reprezentowana przez dynamiczne poruszające się kropki (patrz ilustracje powyżej i wideo na końcu), uwaga wizualna jest raportowana w formie mapy ciepła, która pokazuje mówcę i publiczność, gdzie ogólne miejsce uwagi skupia się na ekranie udostępnianej prezentacji lub środowisko wideokonferencji.

Wszyscy uczestnicy mogą zobaczyć, na czym skupia się ogólna uwaga użytkownika. W artykule nie wspomniano, czy ta funkcja jest dostępna, gdy użytkownik może zobaczyć „galerię” innych uczestników, co może z różnych powodów wskazywać na skupienie się na jednym konkretnym uczestniku.
Testy
Dla CalmResponses stworzono dwa środowiska testowe w formie cichego badania ablacji, wykorzystując trzy różne zestawy okoliczności: w „Warunku B” (wartość bazowa) autorzy odtworzyli typowy wykład studencki online, podczas którego większość studentów miała włączone kamery internetowe wyłączony, a mówca nie widzi twarzy publiczności; w „Stan CR-E” osoba mówiąca mogła zobaczyć sprzężenie zwrotne wzroku (mapy cieplne); w „Stan CR-N” mówca widział zarówno kiwanie głową, jak i aktywność wzroku publiczności.
Pierwszy scenariusz eksperymentalny obejmował warunek B i warunek CR-E; drugi obejmował warunek B i warunek CR-N. Informacje zwrotne uzyskano zarówno od prelegentów, jak i publiczności.
W każdym eksperymencie oceniano trzy czynniki: obiektywną i subiektywną ocenę prezentacji (w tym kwestionariusz samodzielnie przygotowany przez mówcę na temat jego odczuć na temat przebiegu prezentacji); liczba wystąpień „wypełniających” przemówień, wskazujących na chwilową niepewność i krętactwo; i uwagi jakościowe. Te kryteria są pospolity estymatory jakości mowy i niepokoju mówiącego.
Grupa testowa składała się z 38 osób w wieku 19–44 lat, w tym 29 mężczyzn i 24.7 kobiet, średni wiek 6 lat, wszyscy byli Japończykami lub Chińczykami i wszyscy biegle władali językiem japońskim. Zostali oni losowo podzieleni na pięć grup liczących 7–XNUMX uczestników i żadna z osób nie znała się osobiście.
Testy przeprowadzono na platformie Zoom, gdzie w pierwszym eksperymencie prezentacje wygłaszało pięciu prelegentów, a w drugim sześciu.

Warunki wypełniacza oznaczone pomarańczowymi polami. Ogólnie rzecz biorąc, zawartość wypełniaczy spadła w rozsądnej proporcji do zwiększonej liczby opinii widzów na temat systemu.
Naukowcy zauważają, że w przypadku jednego z mówców liczba wypełniaczy uległa znacznej redukcji, a w „Warunku CR-N” osoba mówiąca rzadko wypowiadała frazy wypełniające. Zobacz artykuł, aby zapoznać się z bardzo szczegółowymi i szczegółowymi wynikami; jednak najbardziej widoczne wyniki dotyczyły subiektywnej oceny prelegentów i uczestników publiczności.
W komentarzach publiczności znalazły się:
„Czułem, że brałem udział w prezentacjach” [AN2], „Nie byłem pewien, czy przemówienia mówców uległy poprawie, ale poczułem poczucie jedności dzięki wizualizacji ruchów głów innych osób”. [AN6]
„Nie byłem pewien, czy przemówienia mówców uległy poprawie, ale dzięki wizualizacji ruchów głów innych osób poczułem poczucie jedności”.
Naukowcy zauważają, że system wprowadza nowy rodzaj sztucznej pauzy w prezentacji mówcy, ponieważ mówca jest skłonny odwoływać się do systemu wizualnego, aby ocenić opinie publiczności, zanim przejdzie dalej.
Zauważają także rodzaj „efektu białego fartucha”, trudnego do uniknięcia w warunkach eksperymentalnych, w przypadku którego niektórzy uczestnicy czuli się ograniczeni możliwymi konsekwencjami dla bezpieczeństwa wynikającymi z monitorowania danych biometrycznych.
Wnioski
Godną uwagi zaletą takiego systemu jest to, że wszystkie niestandardowe technologie dodatkowe potrzebne do takiego podejścia całkowicie znikają po zakończeniu ich użytkowania. Nie ma żadnych pozostałości wtyczek do przeglądarek, które należy odinstalować lub które budzą wątpliwości w umysłach uczestników co do tego, czy powinny pozostać w swoich systemach; i nie ma potrzeby przeprowadzania użytkowników przez proces instalacji (chociaż środowisko internetowe wymaga minuty lub dwóch na wstępną kalibrację przez użytkownika) ani uwzględniania możliwości, że użytkownicy nie mają odpowiednich uprawnień do instalowania oprogramowania lokalnego, w tym dodatki i rozszerzenia oparte na przeglądarce.
Chociaż oceniane ruchy twarzy i oczu nie są tak precyzyjne, jak mogłyby być w okolicznościach, w których można zastosować dedykowane lokalne platformy uczenia maszynowego (takie jak seria YOLO), to niemal bezproblemowe podejście do oceny publiczności zapewnia odpowiednią dokładność do szerokiej analizy nastrojów i postaw w typowych scenariuszach wideokonferencji. Przede wszystkim jest bardzo tani.
Więcej szczegółów i przykładów można znaleźć w powiązanym z projektem filmie wideo poniżej.

Opublikowano po raz pierwszy 11 kwietnia 2022 r.













