Kunstig intelligens
Komplett guide til Gemma 2: Googles nye åpne store språkmodell

Gemma 2 bygger på sin forgjenger og tilbyr forbedret ytelse og effektivitet, samt en rekke innovative funksjoner som gjør den spesielt attraktiv for både forskning og praktiske anvendelser. Det som skiller Gemma 2 fra andre modeller er dens evne til å levere ytelse som er sammenlignbar med mye større proprietære modeller, men i en pakke som er designet for bredere tilgjengelighet og bruk på mer beskjedne hårdvarusetuper.
Da jeg dykket ned i de tekniske spesifikasjonene og arkitekturen til Gemma 2, ble jeg stadig mer imponert over ingeniøriteten i dens design. Modellen inkorporerer flere avanserte tekniker, inkludert nye oppmerksomhetsmekanismer og innovative tilnærminger til treningstabilitet, som bidrar til dens bemerkelsesverdige evner.

Google Open Source LLM Gemma
I denne omfattende guiden vil vi dykke dypt inn i Gemma 2, og undersøke dens arkitektur, nøkkel funksjoner og praktiske anvendelser. Uansett om du er en erfaren AI-utøver eller en entusiastisk nykommer i feltet, har denne artikkelen som mål å gi verdifulle innsikter i hvordan Gemma 2 fungerer og hvordan du kan utnytte dens kraft i dine egne prosjekter.
Hva er Gemma 2?
Gemma 2 er Googles nyeste åpne språkmodell, designet for å være lettvekts og kraftig. Den er bygget på samme forskning og teknologi som ble brukt til å skape Googles Gemini-modeller, og tilbyr statens beste ytelse i en mer tilgjengelig pakke. Gemma 2 kommer i to størrelser:
Gemma 2 9B: En 9 milliarder parameter modell
Gemma 2 27B: En større 27 milliarder parameter modell
Hver størrelse er tilgjengelig i to varianter:
Base-modeller: Forhåndstrengt på en enorm korpus av tekstdata
Instruction-tuned (IT) modeller: Feinjustert for bedre ytelse på bestemte oppgaver
Tilgang til modellene i Google AI Studio: Google AI Studio – Gemma 2
Les papiret her: Gemma 2 Teknisk Rapport
Nøkkel funksjoner og forbedringer
Gemma 2 introduserer flere betydelige forbedringer over sin forgjenger:
1. Økt treningdata
Modellene er trent på betydelig mer data:
Gemma 2 27B: Trenet på 13 billioner token
Gemma 2 9B: Trenet på 8 billioner token
Denne utvidede datasettet, hovedsakelig bestående av webdata (hovedsakelig engelsk), kode og matematikk, bidrar til modellens forbedrede ytelse og fleksibilitet.
2. Sliding Window Attention
Gemma 2 implementerer en ny tilnærmning til oppmerksomhetsmekanismer:
Hver annen lag bruker en sliding window attention med en lokal kontekst på 4096 token
Alternativt lag anvender full kvadratisk global attention over hele 8192 token konteksten
Denne hybride tilnærmingen søker å balansere effektivitet med evnen til å fange lange avhengigheter i inndata.
3. Soft-Capping
For å forbedre treningstabiliteten og ytelsen, introduserer Gemma 2 en soft-capping-mekanisme:
<p>def soft_cap(x, cap): return cap * torch.tanh(x / cap)</p> <p># Applied to attention logits attention_logits = soft_cap(attention_logits, cap=50.0)</p> # Applied to final layer logits <p>final_logits = soft_cap(final_logits, cap=30.0)
Denne teknikken forhindrer at logits vokser for stor uten hard trunkering, og beholder mer informasjon samtidig som den stabiliserer treningprosessen.
- Gemma 2 9B: En 9 milliarder parameter modell
- Gemma 2 27B: En større 27 milliarder parameter modell
Hver størrelse er tilgjengelig i to varianter:
- Base-modeller: Forhåndstrengt på en enorm korpus av tekstdata
- Instruction-tuned (IT) modeller: Feinjustert for bedre ytelse på bestemte oppgaver
4. Kunnskapsdestillering
For 9B-modellen, anvender Gemma 2 kunnskapsdestilleringsteknikker:
- Forhåndstrening: 9B-modellen lærer fra en større lærermodell under initial trening
- Etter trening: Begge 9B og 27B-modellene anvender on-policy destillering for å forbedre deres ytelse
Denne prosessen hjelper den mindre modellen til å fange evnene til større modeller mer effektivt.
5. Modell-sammenslåing
Gemma 2 anvender en ny modell-sammenslåingsteknikk kalt Warp, som kombinerer flere modeller i tre stadier:
- Exponential Moving Average (EMA) under forsterkning av trening
- Spherical Linear intERPolation (SLERP) etter feinjustering av flere politikker
- Linear Interpolation Towards Initialization (LITI) som en siste steg
Denne tilnærmingen søker å skape en mer robust og kapabel slutmodell.
Ytelsesbenchmarks
Gemma 2 demonstrerer imponerende ytelse på ulike benchmarks:
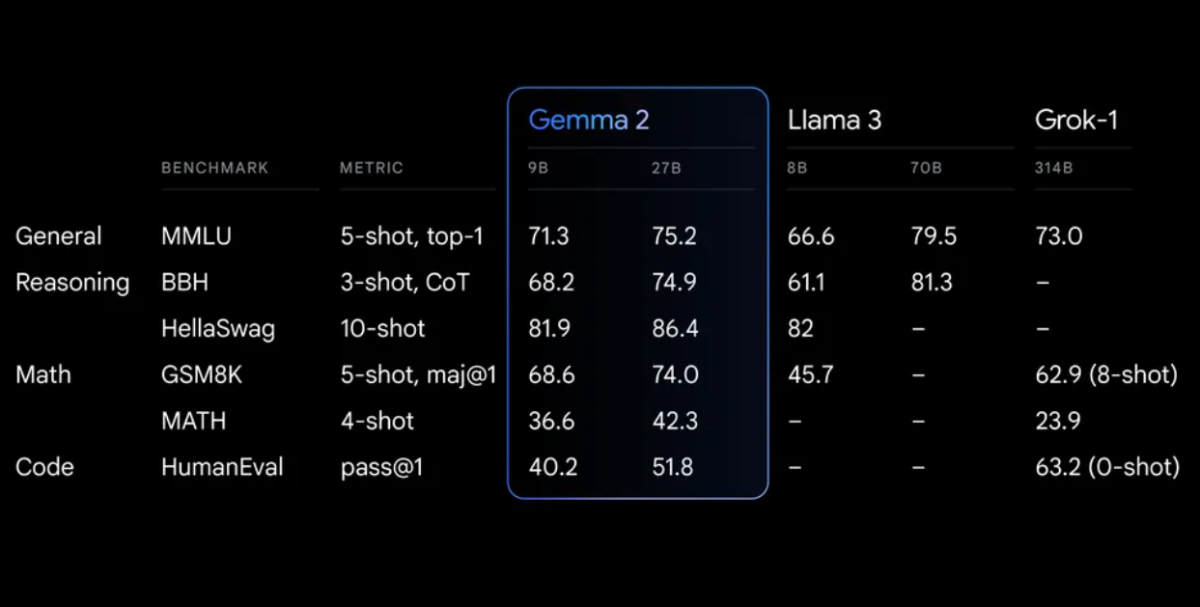
Gemma 2 på en redesignet arkitektur, utviklet for både eksepsjonell ytelse og inferens-effektivitet
Komme i gang med Gemma 2
For å komme i gang med å bruke Gemma 2 i dine prosjekter, har du flere alternativer:
1. Google AI Studio
For rask eksperimentering uten hårdvarukrav, kan du tilgang til Gemma 2 gjennom Google AI Studio.
2. Hugging Face Transformers
Gemma 2 er integrert med den populære Hugging Face Transformers-biblioteket. Her er hvordan du kan bruke det:
<div class="relative flex flex-col rounded-lg"> <div class="text-text-300 absolute pl-3 pt-2.5 text-xs"> <p>from transformers import AutoTokenizer, AutoModelForCausalLM</p> <p># Last inn modell og tokenizer model_name = "google/gemma-2-27b-it" # eller "google/gemma-2-9b-it" for den mindre versjonen tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForCausalLM.from_pretrained(model_name)</p> <p># Forbered inndata prompt = "Forklar konseptet om kvantum-entanglement på enkel måte." inputs = tokenizer(prompt, return_tensors="pt")</p> <p># Generer tekst outputs = model.generate(**inputs, max_length=200) response = tokenizer.decode(outputs[0], skip_special_tokens=True)</p> print(response)
3. TensorFlow/Keras
For TensorFlow-brukere er Gemma 2 tilgjengelig gjennom Keras:
<p>import tensorflow as tf from keras_nlp.models import GemmaCausalLM</p> <p># Last inn modell model = GemmaCausalLM.from_preset("gemma_2b_en")</p> <p># Generer tekst prompt = "Forklar konseptet om kvantum-entanglement på enkel måte." output = model.generate(prompt, max_length=200)</p> print(output)
Avansert bruk: Bygging av en lokal RAG-system med Gemma 2
En av de kraftigste anvendelsene av Gemma 2 er i bygging av et Retrieval Augmented Generation (RAG) system. La oss skape et enkelt, fullstendig lokalt RAG-system med Gemma 2 og Nomic-embeddings.
Steg 1: Innstallasjon av miljøet
Først, sikre at du har de nødvendige bibliotekene installert:
<p>pip install langchain ollama nomic chromadb</p>
Steg 2: Indeksering av dokumenter
Opprett en indekserer for å prosessere dine dokumenter:
<p>import os from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain.document_loaders import DirectoryLoader from langchain.vectorstores import Chroma from langchain.embeddings import HuggingFaceEmbeddings</p> <p>class Indexer: def __init__(self, directory_path): self.directory_path = directory_path self.text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200) self.embeddings = HuggingFaceEmbeddings(model_name="nomic-ai/nomic-embed-text-v1")</p> <p>def load_and_split_documents(self): loader = DirectoryLoader(self.directory_path, glob="**/*.txt") documents = loader.load() return self.text_splitter.split_documents(documents)</p> <p>def create_vector_store(self, documents): return Chroma.from_documents(documents, self.embeddings, persist_directory="./chroma_db")</p> <p>def index(self): documents = self.load_and_split_documents() vector_store = self.create_vector_store(documents) vector_store.persist() return vector_store</p> <p># Bruk indexer = Indexer("path/to/your/documents") vector_store = indexer.index()</p>
Steg 3: Innstallasjon av RAG-systemet
Nå, la oss skape RAG-systemet med Gemma 2:
<p>from langchain.llms import Ollama
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate</p>
<p>class RAGSystem:
def __init__(self, vector_store):
self.vector_store = vector_store
self.llm = Ollama(model="gemma2:9b")
self.retriever = self.vector_store.as_retriever(search_kwargs={"k": 3})</p>
<p>self.template = """Bruk følgende deler av konteksten til å svare på spørsmålet i slutten.
Hvis du ikke vet svaret, bare si at du ikke vet, prøv ikke å finne på et svar.</p>
{context}
<p>Spørsmål: {question}
Svar: """</p>
<p>self.qa_prompt = PromptTemplate(
template=self.template, input_variables=["context", "question"]
)</p>
<p>self.qa_chain = RetrievalQA.from_chain_type(
llm=self.llm,
chain_type="stuff",
retriever=self.retriever,
return_source_documents=True,
chain_type_kwargs={"prompt": self.qa_prompt}
)</p>
<p>def query(self, question):
return self.qa_chain({"query": question})</p>
<p># Bruk
rag_system = RAGSystem(vector_store)
response = rag_system.query("Hva er hovedstaden i Frankrike?")
print(response["result"])</p>
Dette RAG-systemet bruker Gemma 2 gjennom Ollama for språkmodellen, og Nomic-embeddings for dokumenthenting. Det lar deg stille spørsmål basert på indekserte dokumenter, og gir svar med kontekst fra relevante kilder.
Fine-tuning av Gemma 2
For bestemte oppgaver eller domener, kan du kanskje ønske å fine-tune Gemma 2. Her er et grundig eksempel med Hugging Face Transformers-biblioteket:
from transformers import AutoTokenizer, AutoModelForCausalLM, TrainingArguments, Trainer from datasets import load_dataset <p># Last inn modell og tokenizer model_name = "google/gemma-2-9b-it" tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForCausalLM.from_pretrained(model_name)</p> <p># Forbered datasett dataset = load_dataset("your_dataset")</p> <p>def tokenize_function(examples): return tokenizer(examples["text"], padding="max_length", truncation=True)</p> <p>tokenized_datasets = dataset.map(tokenize_function, batched=True)</p> <p># Sett opp treningargumenter training_args = TrainingArguments( output_dir="./results", num_train_epochs=3, per_device_train_batch_size=4, per_device_eval_batch_size=4, warmup_steps=500, weight_decay=0.01, logging_dir="./logs", )</p> <p># Initialiser Trainer trainer = Trainer( model=model, args=training_args, train_dataset=tokenized_datasets["train"], eval_dataset=tokenized_datasets["test"], )</p> # Start fine-tuning trainer.train() <p># Lagre den fine-tunede modellen model.save_pretrained("./fine_tuned_gemma2") tokenizer.save_pretrained("./fine_tuned_gemma2")</p>
Husk å justere treningparameterne basert på dine spesifikke behov og beregningsressurser.
Etiske overveielser og begrensninger
Mens Gemma 2 tilbyr imponerende evner, er det viktig å være klar over dens begrensninger og etiske overveielser:
- Forutinntak: Som alle språkmodeller, kan Gemma 2 reflektere forutinntak som er til stede i dens treningdata. Vurder alltid kritisk dens utdata.
- Fakta-nøyaktighet: Selv om den er svært kapabel, kan Gemma 2 noen ganger generere feil eller inkonsistente opplysninger. Verifiser viktige fakta fra pålitelige kilder.
- Kontekstlengde: Gemma 2 har en kontekstlengde på 8192 token. For lengre dokumenter eller samtaler, kan du kanskje måtte implementere strategier for å håndtere konteksten effektivt.
- Beregningressurser: Spesielt for 27B-modellen, kan betydelige beregningsressurser være nødvendige for effektiv inferens og fine-tuning.
- Ansvarlig bruk: Hold deg til Googles ansvarlige AI-praksis og sikre at din bruk av Gemma 2 er i samsvar med etiske AI-prinsipper.
Konklusjon
Gemma 2s avanserte funksjoner som sliding window attention, soft-capping og nye modell-sammenslåingsteknikker gjør den til et kraftig verktøy for en rekke språkbehandlingsoppgaver.
Ved å utnytte Gemma 2 i dine prosjekter, enten gjennom enkel inferens, komplekse RAG-systemer eller fine-tunede modeller for bestemte domener, kan du tappe inn i kraften til SOTA AI samtidig som du beholder kontroll over dine data og prosesser.












