Kunstig intelligens
AI-assistert objekteredigering med Google’s Imagic og Runway’s ‘Erase and Replace’

Denne uken tilbyr to nye, men motsatte, AI-drevne grafiske algoritmer nye måter for sluttbrukere å gjøre svært detaljerte og effektive endringer i objekter i bilder.
Det første er Imagic, fra Google Research, i samarbeid med Israels teknologiinstitutt og Weizmann Institute of Science. Imagic tilbyr tekst-betinget, fin-granulert redigering av objekter via finjustering av diffusjonsmodeller.

Endre hva du liker, og la resten være – Imagic lover granulert redigering av bare de delene du ønsker å endre. Kilde: https://arxiv.org/pdf/2210.09276.pdf
Alle som noensinne har prøvd å endre bare ett element i en Stable Diffusion-omrendring, vil vite altfor godt at for hvert vellykket redigering, vil systemet endre fem ting som du likte akkurat slik de var. Dette er en svakhet som for tiden har mange av de mest talentfulle SD-entusiastene konstant å shuffler mellom Stable Diffusion og Photoshop for å fikse denne type “skade”. Fra dette synspunktet alene, ser Imagics prestasjoner ut til å være bemerkelsesverdige.
På tidspunktet for skrivingen, mangler Imagic ennå en promotingsvideo, og, gitt Google’s forsiktige holdning til å slippe ut ubegrensede bilde-synteseverktøy, er det usikkert i hvilken utstrekning, hvis noen, vi kommer til å få mulighet til å teste systemet.
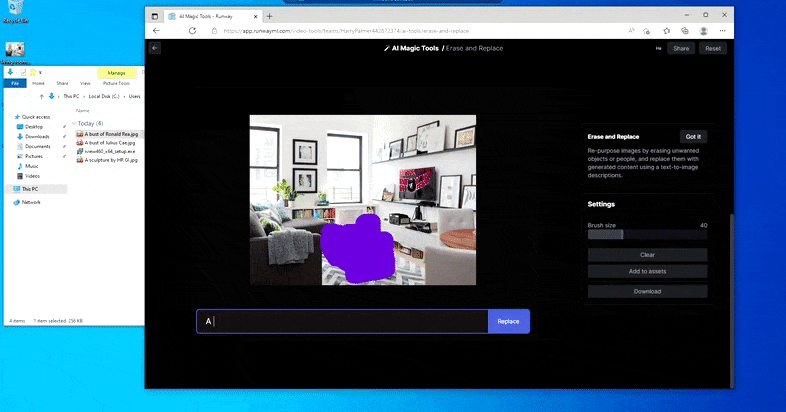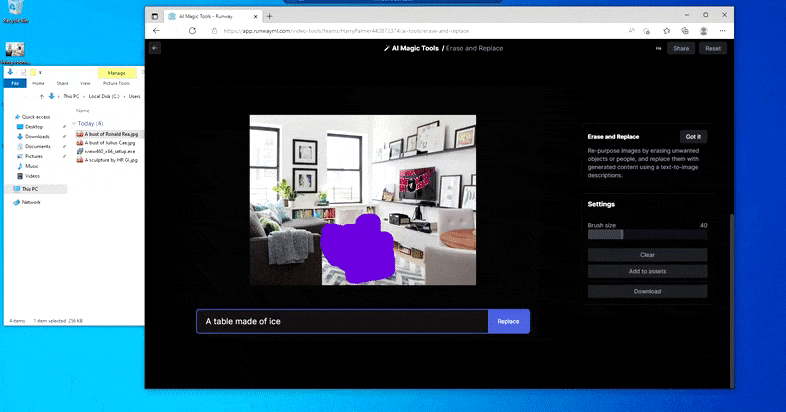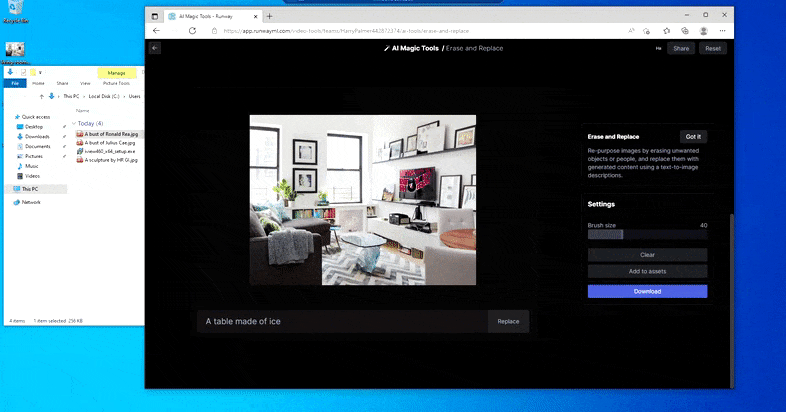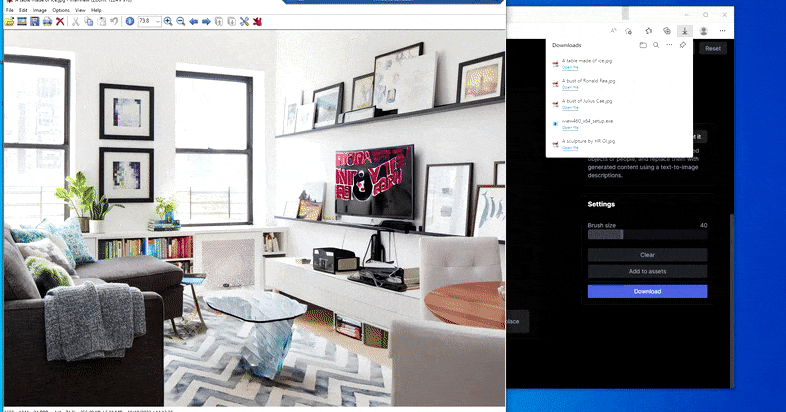
Det andre tilbudet er Runway MLs mer tilgjengelige Erase and Replace-funksjon, en ny funksjon i ‘AI Magic Tools’-delen av deres eksklusive online-samling av maskinlæringsbaserte visuelle effektverktøy.
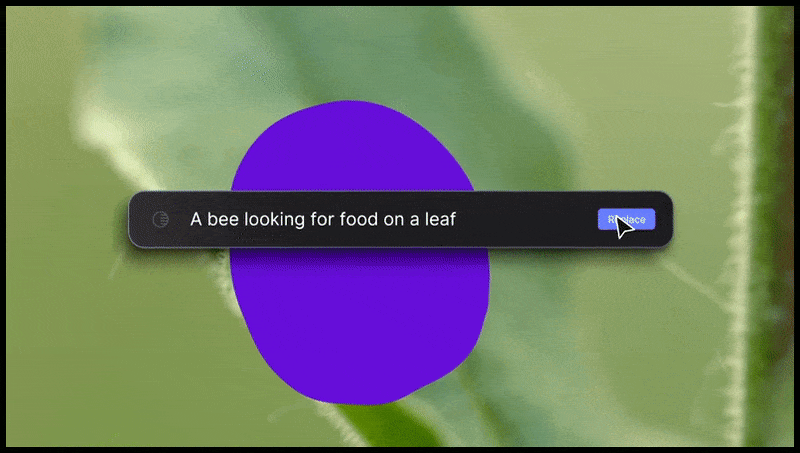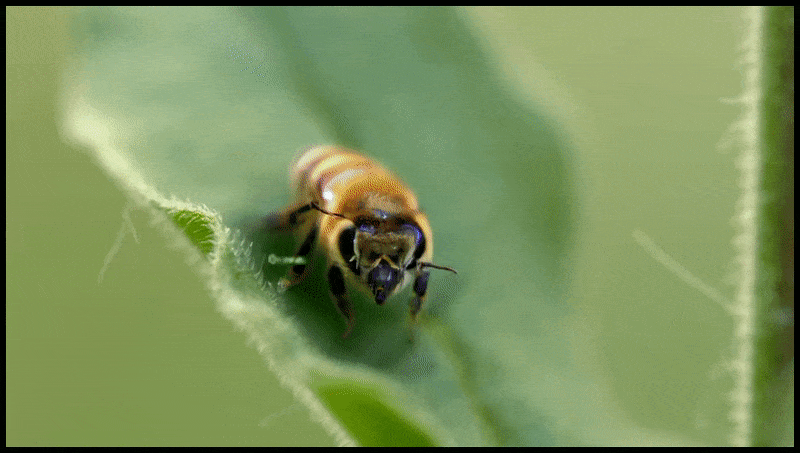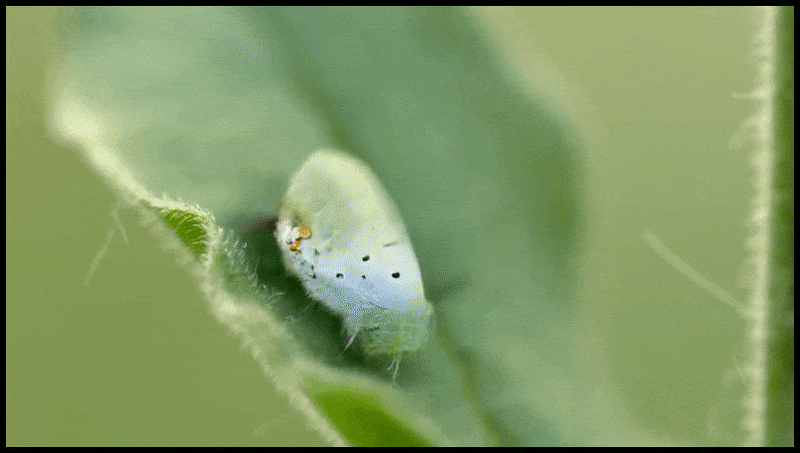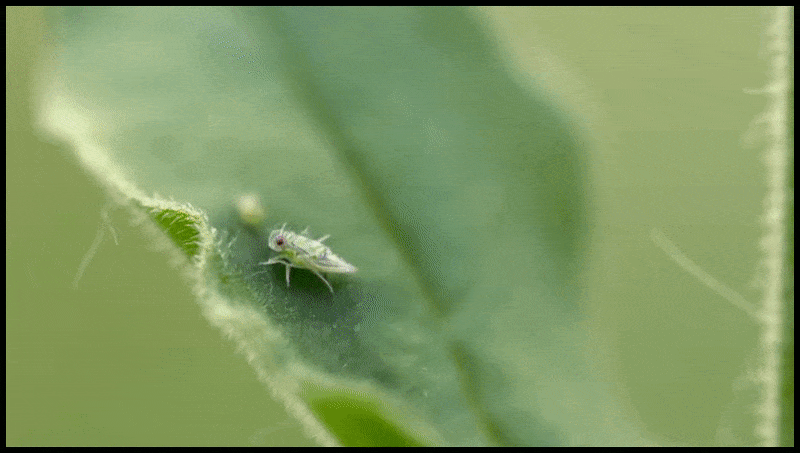
Runway MLs Erase and Replace-funksjon, allerede sett i en forhåndsvisning for en tekst-til-video-redigeringsystem. Kilde: https://www.youtube.com/watch?v=41Qb58ZPO60
La oss se på Runways utgave først.
Erase and Replace
Like Imagic, Erase and Replace omhandler eksklusivt stillbilder, selv om Runway har forhåndsvist samme funksjonalitet i en tekst-til-video-redigeringsløsning som ennå ikke er utgitt:

Selv om hvem som helst kan teste ut den nye Erase and Replace på bilder, er videoversjonen ennå ikke offentlig tilgjengelig. Kilde: https://twitter.com/runwayml/status/1568220303808991232
Runway ML har ennå ikke offentliggjort detaljer om teknologiene bak Erase and Replace, men hastigheten som du kan erstatte en husplante med en overbevisende buste av Ronald Reagan, tyder på at en diffusjonsmodell som Stable Diffusion (eller, langt mindre sannsynlig, en lisensiert DALL-E 2) er motoren som gjenskaper objektet ditt valg i Erase and Replace.

Erstatte en husplante med en buste av The Gipper ikke helt så raskt som dette, men det er ganske raskt. Kilde: https://app.runwayml.com/
Systemet har noen DALL-E 2-type begrensninger – bilder eller tekst som flagger Erase and Replace-filtrene, vil utløse en advarsel om mulig konto-suspensjon i tilfelle av ytterligere overtredelser – praktisk talt en kopi av OpenAI’s policier for DALL-E 2.
Mange av resultater mangler de typiske ruccioneggene til Stable Diffusion. Runway ML er investorer og forskningspartnere i SD, og det er mulig at de har trent en proprietær modell som er overlegen den åpne kildekode 1.4 checkpoint-vektene som resten av oss for tiden slåss med (som mange andre utviklingsgrupper, hobbyist og profesjonell alike, for tiden trener eller finjusterer Stable Diffusion-modeller).
Erstatte en hjemmebord med en ‘bord av is’ i Runway MLs Erase and Replace.
Som med Imagic (se under), er Erase and Replace ‘objekt-orientert’ – du kan ikke bare slette en ‘tom’ del av bildet og inpainte det med resultatet av din tekstprompt; i den scenarioen vil systemet bare spore den nærmeste synlige objektet langs maskens linje-for-syn (slik som en vegg eller en TV), og anvende transformasjonen der.
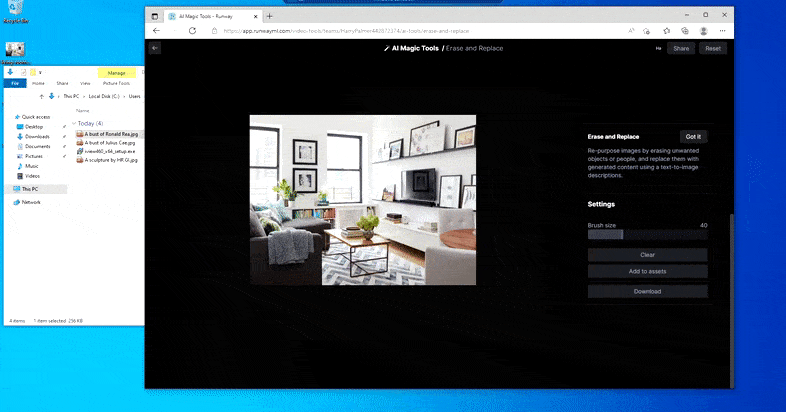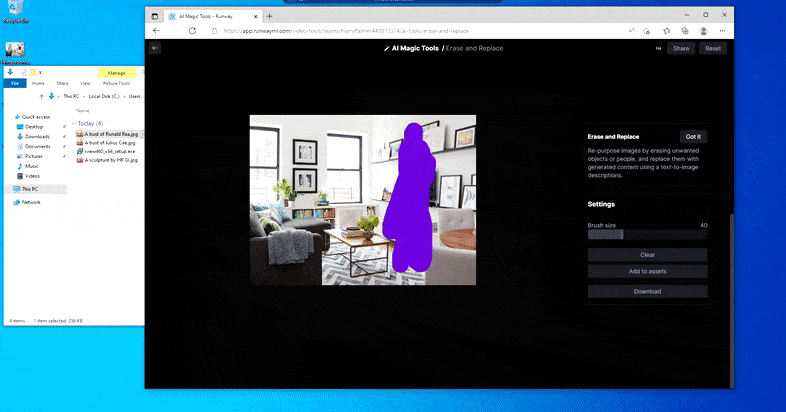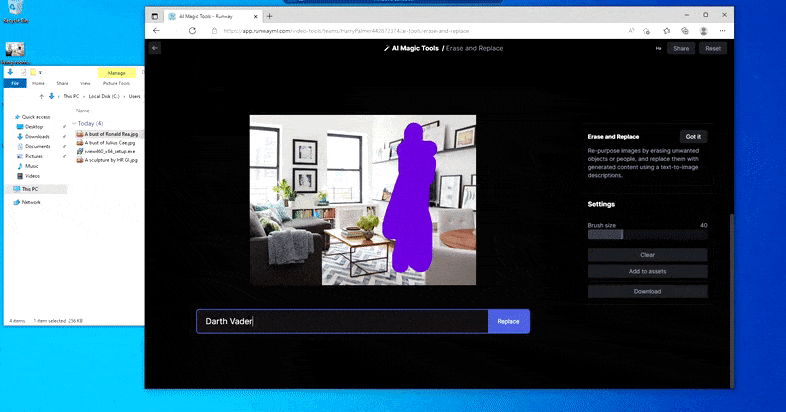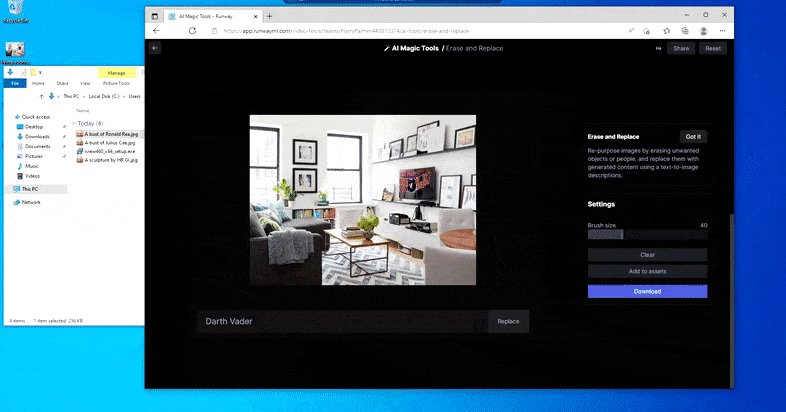
Som navnet indikerer, kan du ikke injisere objekter i tom rom i Erase and Replace. Her, et forsøk på å fremkalle den mest berømte av Sith-herrene, resulterer i en merkelig Vader-relatert mural på TV-en, omtrent der ‘erstatte’-området var tegnet.
Det er vanskelig å si om Erase and Replace er evasiv i forhold til bruk av opphavsrettslige bilder (som fortsatt er i stor grad hindret, om enn med varierende suksess, i DALL-E 2), eller om modellen som brukes i backend-renderingen ikke er optimalisert for den type ting.

Den litt NSFW ‘Mural av Nicole Kidman’ indikerer at den (antagelig) diffusjonsbaserte modellen i hånden mangler DALL-E 2s tidligere systematiske avvisning av å rendre realistiske ansikter eller racy innhold, mens resultater for forsøk på å fremkalle opphavsrettslige verk varierer fra det tvetydige (‘xenomorph’) til det absurd (‘the iron throne’). Innsatt nederst til høyre, kildebildet.
Det ville være interessant å vite hva metoder Erase and Replace bruker for å isolere objektene som det er i stand til å erstatte. Antageligvis kjøres bildet gjennom noen avledning av CLIP, med de diskrete elementene individuert av objektgjenkjenning og påfølgende semantisk segmentering. Ingen av disse operasjonene fungerer noen gang like bra i en vanlig installasjon av Stable Diffusion.
Men ingenting er perfekt – noen ganger ser systemet ut til å slette og ikke erstatte, selv når (som vi har sett i bildet ovenfor), den underliggende renderingsmekanismen definitivt vet hva en tekstprompt betyr. I dette tilfelle, viser det seg å være umulig å forvandle en kaffebord til en xenomorph – i stedet forsvinner bare bordet.
En skremmende iterasjon av ‘Where’s Waldo’, mens Erase and Replace feiler i å produsere en alien.
Erase and Replace ser ut til å være et effektivt objekt-erstatningssystem, med utmerket inpainting. Men det kan ikke redigere eksisterende oppfattede objekter, bare erstatte dem. Å faktisk endre eksisterende bildeinnhold uten å kompromittere omgivelsesmateriale, er antageligvis en langt harder oppgave, bundet opp med datavisjonsforskningssektorens lange kamp mot disentanglement i de forskjellige latente rommene til de populære rammeverkene.
Imagic
Det er en oppgave som Imagic håndterer. Den nye artikkelen tilbyr tallrike eksempler på redigeringer som vellykket endrer enkelte aspekter av et bilde mens resten av bildet forblir urørt.

I Imagic, lider de endrede bildene ikke under den karakteristiske strekkingen, forvrengingen og ‘okklusjons-gjettningen’ karakteristisk for deepfake-puppetry, som utnytter begrensede priorer derivert fra ett enkelt bilde.
Systemet bruker en tre-stegs prosess – tekst-embedding-optimisering; modell-finjustering; og, til slutt, generering av det endrede bildet.

Imagic koder tekstprompten for å hente den initielle tekst-embeddingen, og deretter optimaliserer resultatet for å få inn bildet. Deretter finjusteres den generative modellen til kildebildet, med en rekke parametre, før den underwerpes den ønskede interpolasjonen.
Rammeverket er basert på Google’s Imagen-tekst-til-video-arkitektur, selv om forskerne påstår at systemets prinsipper er bredt anvendelige på latente diffusjonsmodeller.
Imagen bruker en tre-nivås arkitektur, i stedet for den syv-nivås arrayen brukt for selskapets tekst-til-video-iterasjon av programvaren. De tre distinkte modulene består av en generativ diffusjonsmodell som opererer ved 64x64px-oppløsning; en super-oppløsningsmodell som oppskalerer denne utdata til 256x256px; og en ytterligere super-oppløsningsmodell som tar utdata helt opp til 1024×1024-oppløsning.
Imagic griper inn i den tidligste fasen av denne prosessen, optimaliserer den ønskede tekst-embeddingen på 64px-stadiet på en Adam-optimizer med en statisk læringshastighet på 0,0001.

En mesterklasse i disentanglement: de som har forsøkt å endre noe så enkelt som fargen på et renderet objekt i en diffusjon, GAN eller NeRF-modell, vil vite hvor betydelig det er at Imagic kan utføre slike transformasjoner uten å ‘rive fra hverandre’ konsistensen av resten av bildet.
Finjustering skjer deretter på Imagens basismodell, for 1500 steg per innputt-bilde, betinget av den reviderte embeddingen. Samtidig optimaliseres den sekundære 64px>256px-laget i parallell på det betingede bildet. Forskerne påpeker at en lignende optimalisering for den endelige 256px>1024px-laget har ‘lite eller ingen’ effekt på de endelige resultater, og har derfor ikke implementert dette.
Artikkelen påstår at optimaliseringsprosessen tar omtrent åtte minutter for hvert bilde på doble TPUV4-chips. Den endelige renderingen skjer i core Imagen under DDIM-sampling-scheme.
I likhet med lignende finjusteringsprosesser for Google’s DreamBooth, kan de resulterende embeddingene også brukes til å aktivere stilisering, samt fotorealistiske redigeringer som inneholder informasjon hentet fra den underliggende database som driver Imagen (siden, som den første kolonnen nedenfor viser, har kildebildene ingen av den nødvendige innholdet for å effektuere disse transformasjonene).

Fleksible fotorealistiske bevegelser og redigeringer kan fremkalles via Imagic, mens de avledede og disentangled-kodene som er hentet i prosessen, kan like lett brukes til stilisert utgang.
Forskerne sammenlignet Imagic med tidligere arbeid SDEdit, en GAN-basert tilnærming fra 2021, et samarbeid mellom Stanford University og Carnegie Mellon University; og Text2Live, et samarbeid, fra april 2022, mellom Weizmann Institute of Science og NVIDIA.

En visuell sammenligning mellom Imagic, SDEdit og Text2Live.
Det er tydelig at de tidligere tilnærmingene sliter, men i den nederste raden, som innebærer å injisere en massiv endring av pose, feiler de eksisterende tilnærmingene fullstendig til å omforme kildematerialet, sammenlignet med en merkbart suksess fra Imagic.
Imagics ressurskrav og treningstid per bilde, mens kort i forhold til slike forfølgelser, gjør det til en usannsynlig inklusjon i en lokal bilde-redigeringsapplikasjon på personlige datamaskiner – og det er ikke klart i hvilken utstrekning prosessen med finjustering kan skaleres ned til forbruker-nivå.
Som det står, er Imagic et imponerende tilbud som er mer egnet til API-er – en miljø Google Research, sky og kritikk i forhold til å fasilitere deepfaking, kanskje i alle fall er mest komfortable med.
Først publisert 18. oktober 2022.












