
Artificial Intelligence
Is DALL-E 2 gewoon 'dingen aan elkaar lijmen' zonder hun relaties te begrijpen?

Een nieuw onderzoeksartikel van de Harvard University suggereert dat OpenAI's spraakmakende tekst-naar-beeld-framework DALL-E 2 opmerkelijke problemen heeft om zelfs op babyniveau relaties te reproduceren tussen de elementen die het samenstelt in gesynthetiseerde foto's, ondanks de oogverblindende verfijning van veel van zijn uitvoer.
De onderzoekers voerden een gebruikersonderzoek uit met 169 gecrowdsourcete deelnemers, die DALL-E 2-afbeeldingen kregen gepresenteerd op basis van de meest basale menselijke principes van relatie-semantiek, samen met de tekst-prompts die ze hadden gemaakt. Op de vraag of de prompts en de afbeeldingen gerelateerd waren, werd minder dan 22% van de afbeeldingen gezien als relevant voor de bijbehorende prompts, in termen van de zeer eenvoudige relaties die DALL-E 2 moest visualiseren.

Een schermafdruk van de proeven die zijn uitgevoerd voor de nieuwe krant. Deelnemers moesten alle afbeeldingen selecteren die overeenkwamen met de prompt. Ondanks de disclaimer onderaan de interface, werden de afbeeldingen in alle gevallen, buiten medeweten van de deelnemers, in feite gegenereerd op basis van de weergegeven bijbehorende prompt. Bron: https://arxiv.org/pdf/2208.00005.pdf
De resultaten suggereren ook dat het schijnbare vermogen van DALL-E om ongelijksoortige elementen samen te voegen, kan afnemen naarmate het minder waarschijnlijk wordt dat die elementen zijn opgetreden in de echte trainingsgegevens die het systeem aandrijven.
Afbeeldingen voor de prompt 'kind raakt een kom aan' kregen bijvoorbeeld een overeenstemmingspercentage van 87% (dwz de deelnemers klikten op de meeste afbeeldingen als zijnde relevant voor de prompt), terwijl vergelijkbare fotorealistische weergaven van 'een aap die een leguaan aanraakt' bereikten slechts 11% overeenstemming:


DALL-E worstelt om de onwaarschijnlijke gebeurtenis van een 'aap die een leguaan aanraakt' weer te geven, waarschijnlijk omdat het ongewoon is, waarschijnlijker niet bestaat, in de trainingsset.
In het tweede voorbeeld heeft DALL-E 2 vaak de schaal en zelfs de soort verkeerd, vermoedelijk vanwege een gebrek aan afbeeldingen uit de echte wereld die deze gebeurtenis weergeven. Daarentegen is het redelijk om te verwachten dat er een groot aantal trainingsfoto's met betrekking tot kinderen en eten is, en dat dit subdomein/de klas goed ontwikkeld is.
De moeilijkheid van DALL-E om wild contrasterende beeldelementen naast elkaar te plaatsen, suggereert dat het publiek momenteel zo verbluft is door de fotorealistische en breed interpreterende mogelijkheden van het systeem dat het geen kritisch oog heeft ontwikkeld voor gevallen waarin het systeem het ene element in feite gewoon op het andere heeft 'gelijmd' , zoals in deze voorbeelden van de officiële DALL-E 2-site:

Knip-en-plaksynthese, van de officiële voorbeelden voor DALL-E 2. Bron: https://openai.com/dall-e-2/
In het nieuwe papier staat*:
'Relationeel begrip is een fundamentele component van menselijke intelligentie, die zich manifesteert vroeg in ontwikkeling, en wordt snel en automatisch berekend in perceptie.
'De moeilijkheid van DALL-E 2 met zelfs elementaire ruimtelijke relaties (zoals in, on, voor) suggereert dat wat het ook heeft geleerd, het nog niet het soort representaties heeft geleerd waarmee mensen de wereld zo flexibel en robuust kunnen structureren.
'Een directe interpretatie van deze moeilijkheid is dat systemen als DALL-E 2 nog geen relationele samenstelling hebben.'
De auteurs suggereren dat tekstgestuurde systemen voor het genereren van afbeeldingen, zoals de DALL-E-serie, baat zouden kunnen hebben bij het gebruik van algoritmen die gebruikelijk zijn in robotica, die identiteiten en relaties tegelijkertijd modelleren, vanwege de noodzaak voor de agent om daadwerkelijk met de omgeving te communiceren in plaats van alleen maar te fabriceren. een mix van verschillende elementen.
Een van die benaderingen, getiteld CLIPort, gebruikt hetzelfde CLIP-mechanisme dat dient als kwaliteitsbeoordelingselement in DALL-E 2:
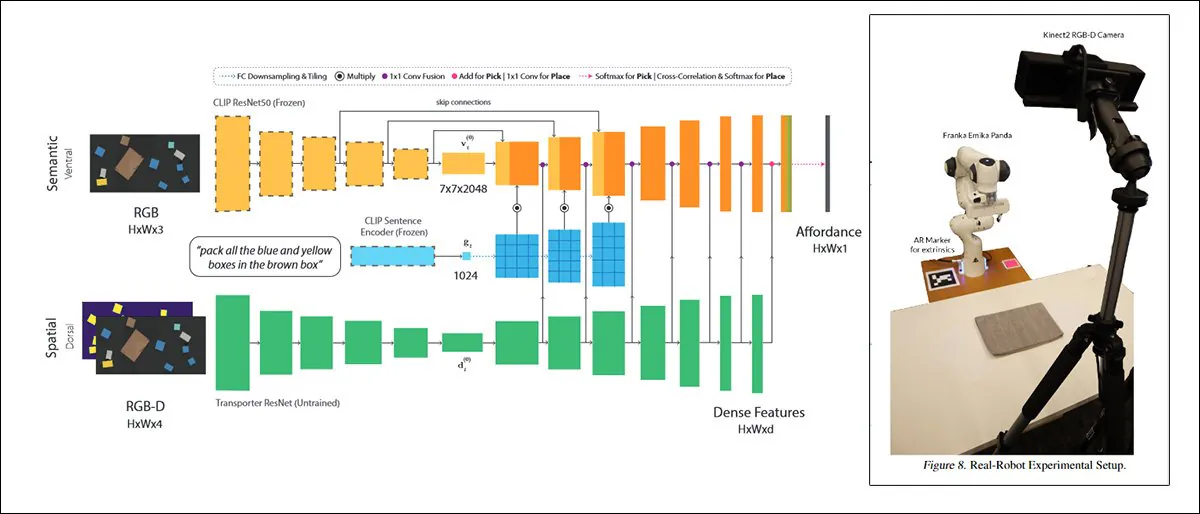
CLIPort, een samenwerking uit 2021 tussen de Universiteit van Washington en NVIDIA, gebruikt CLIP in een context die zo praktisch is dat de systemen die erop zijn getraind noodzakelijkerwijs een begrip van fysieke relaties moeten ontwikkelen, een motivator die afwezig is in DALL-E 2 en soortgelijke 'fantastische' raamwerken voor beeldsynthese. Bron: https://arxiv.org/pdf/2109.12098.pdf
De auteurs suggereren verder dat 'een andere plausibele upgrade' zou kunnen zijn dat de architectuur van beeldsynthesesystemen zoals DALL-E wordt opgenomen multiplicatieve effecten in een enkele rekenlaag, waardoor relaties kunnen worden berekend op een manier die is geïnspireerd op de informatieverwerkingscapaciteiten van biologisch oplossingen.
Ocuco's Medewerkers nieuw papier is getiteld Testen van relationeel begrip bij tekstgestuurde beeldgeneratie, en is afkomstig van Colin Conwell en Tomer D. Ullman van de afdeling Psychologie van Harvard.
Voorbij vroege kritiek
In reactie op de 'goochelarij' achter het realisme en de integriteit van de uitvoer van DALL-E 2, wijzen de auteurs op eerdere werken die tekortkomingen hebben gevonden in generatieve beeldsystemen in DALL-E-stijl.
In juni van dit jaar, UoC Berkeley bekend de moeilijkheid die DALL-E heeft bij het omgaan met reflecties en schaduwen; dezelfde maand onderzocht een studie uit Korea de 'uniciteit' en originaliteit van uitvoer in DALL-E 2-stijl met een kritische blik, Een voorlopige analyse van DALL-E 2-afbeeldingen, kort na de lancering, van NYU en de Universiteit van Texas, verschillende problemen gevonden met compositie en andere essentiële factoren in DALL-E 2-afbeeldingen; en vorige maand een gezamenlijk werk tussen de Universiteit van Illinois en MIT boden suggesties voor architectonische verbeteringen aan dergelijke systemen in termen van samenstelling.
De onderzoekers merken verder op dat DALL-E-armaturen zoals Aditya Ramesh hebben toegegeven de problemen van het raamwerk met binding, relatieve grootte, tekst en andere uitdagingen.
De ontwikkelaars achter Google's rivaliserende beeldsynthesesysteem Imagen hebben ook een voorstel gedaan Tekenbank, een nieuw vergelijkingssysteem dat de beeldnauwkeurigheid meet over kaders met diverse statistieken.
In plaats daarvan suggereren de auteurs van het nieuwe artikel dat een beter resultaat zou kunnen worden verkregen door menselijke inschatting - in plaats van interne, algoritmische statistieken - af te zetten tegen de resulterende beelden, om vast te stellen waar de zwakke punten liggen en wat er zou kunnen worden gedaan om ze te verminderen.
De Studie
Daartoe baseert het nieuwe project zijn aanpak op psychologische principes en probeert het zich terug te trekken uit de stroom golf van interesse in snelle techniek (wat in feite een concessie is aan de tekortkomingen van DALL-E 2, of een vergelijkbaar systeem), om de beperkingen te onderzoeken en mogelijk aan te pakken die dergelijke 'workarounds' noodzakelijk maken.
In de krant staat:
'Het huidige werk richt zich op een reeks van 15 basisrelaties die eerder zijn beschreven, onderzocht of voorgesteld in de cognitieve, ontwikkelings- of linguïstische literatuur. De set bevat zowel gegronde ruimtelijke relaties (bijv. 'X op Y') als meer abstracte agentische relaties (bijv. 'X helpt Y').
'De prompts zijn opzettelijk eenvoudig, zonder complexiteit of uitwerking. Dat wil zeggen, in plaats van een prompt als 'een ezel en een octopus spelen een spel'. De ezel houdt aan het ene uiteinde een touw vast, de octopus aan het andere uiteinde. De ezel houdt het touw in zijn bek. Een kat springt over het touw', wij gebruiken 'een doos op een mes'.
'De eenvoud omvat nog steeds een breed scala aan relaties uit verschillende subdomeinen van de menselijke psychologie, en maakt potentiële modelfouten opvallender en specifieker.'
Voor hun studie rekruteerden de auteurs 169 deelnemers van Prolific, allemaal gevestigd in de VS, met een gemiddelde leeftijd van 33 en 59% vrouw.
De deelnemers kregen 18 afbeeldingen te zien, georganiseerd in een raster van 3×6 met de prompt bovenaan en een disclaimer onderaan waarin stond dat alle, sommige of geen van de afbeeldingen mogelijk zijn gegenereerd op basis van de weergegeven prompt, en werden vervolgens gevraagd om selecteer de afbeeldingen waarvan ze dachten dat ze op deze manier aan elkaar gerelateerd waren.
De beelden die aan de individuen werden gepresenteerd, waren gebaseerd op taalkundige, ontwikkelings- en cognitieve literatuur, bestaande uit een set van acht fysieke en zeven 'agentische' relaties (dit zal zo duidelijk worden).
Fysieke relaties
in, op, onder, bedekkend, dichtbij, afgesloten door, hangend over, en gelinkt aan.
Agentische relaties
duwen, trekken, aanraken, slaan, schoppen, helpen, en hinderen.
Al deze relaties zijn ontleend aan de eerder genoemde niet-CS-studiegebieden.
Twaalf entiteiten werden dus afgeleid voor gebruik in de prompts, met zes objecten en zes agenten:
Objecten
doos, cilinder, deken, kom, theekopje, en mes.
Agenten
man, vrouw, kind, robot, aap, en leguaan.
(De onderzoekers geven toe dat het opnemen van de leguaan, geen steunpilaar van droog sociologisch of psychologisch onderzoek, 'een traktatie' was)
Voor elke relatie werden vijf verschillende prompts gemaakt door twee entiteiten vijf keer willekeurig te bemonsteren, resulterend in in totaal 75 prompts, die elk werden ingediend bij DALL-E 2, en voor elk waarvan de aanvankelijke 18 geleverde afbeeldingen werden gebruikt, zonder variaties of tweede kans toegestaan.
Resultaten
In de krant staat*:
'Deelnemers meldden gemiddeld een lage mate van overeenstemming tussen de afbeeldingen van DALL-E 2 en de prompts die werden gebruikt om ze te genereren, met een gemiddelde van 22.2% [18.3, 26.6] over de 75 verschillende prompts.
'Agentic prompts, met een gemiddelde van 28.4% [22.8, 34.2] over 35 prompts, genereerden meer overeenstemming dan fysieke prompts, met een gemiddelde van 16.9% [11.9, 23.0] over 40 prompts.'

Resultaten van de studie. Punten in het zwart geven alle prompts aan, waarbij elk punt een individuele prompt is, en de kleur wordt onderverdeeld naargelang het onderwerp van de prompt agentisch of fysiek (dwz een object) was.
Om het verschil tussen menselijke en algoritmische perceptie van de afbeeldingen te vergelijken, hebben de onderzoekers hun renders door OpenAI's open source gehaald ViT-L/14 CLIP-gebaseerd raamwerk. Door de scores te middelen, vonden ze een 'matige relatie' tussen de twee reeksen resultaten, wat misschien verrassend is, gezien de mate waarin CLIP zelf helpt bij het genereren van de afbeeldingen.

Resultaten van de CLIP (ViT-L/14) vergelijking met menselijke reacties.
De onderzoekers suggereren dat andere mechanismen binnen de architectuur, misschien gecombineerd met een toevallig overwicht (of gebrek aan gegevens) in de trainingsset, de manier kunnen verklaren waarop CLIP de beperkingen van DALL-E kan herkennen zonder in alle gevallen iets te kunnen doen. veel over het probleem.
De auteurs concluderen dat DALL-E 2 alleen een denkbeeldige mogelijkheid heeft om beelden te reproduceren die relationeel begrip bevatten, een fundamenteel facet van menselijke intelligentie dat zich al heel vroeg in ons ontwikkelt.
'Het idee dat systemen zoals DALL-E 2 geen compositie hebben, kan als een verrassing komen voor iedereen die de opvallend redelijke reacties van DALL-E 2 heeft gezien op aanwijzingen als 'een cartoon van een baby daikon-radijs in een tutu die een poedel uitloopt'. Prompts zoals deze genereren vaak een verstandige benadering van een compositieconcept, waarbij alle delen van de prompts aanwezig zijn en op de juiste plaatsen aanwezig zijn.
'Compositionaliteit is echter niet alleen het vermogen om dingen aan elkaar te lijmen - zelfs dingen die je misschien nog nooit eerder aan elkaar hebt waargenomen. Samenstelling vereist een goed begrip van de reglement die dingen met elkaar verbinden. Relaties zijn zulke regels.'
Man bijt T-Rex
Advies Aangezien OpenAI een groter aantal gebruikers na de recente bètaversie van DALL-E 2, en aangezien men nu voor de meeste generaties moet betalen, kunnen de tekortkomingen in het relationele begrip van DALL-E 2 duidelijker worden, aangezien elke 'mislukte' poging een financieel gewicht heeft, en terugbetalingen zijn niet beschikbaar.
Degenen onder ons die iets eerder een uitnodiging hebben ontvangen, hebben tijd gehad (en tot voor kort meer vrije tijd om met het systeem te spelen) om enkele van de 'relatiestoringen' waar te nemen die DALL-E 2 kan uitzenden.
Bijvoorbeeld voor een Jurassic Park fan, het is erg moeilijk om een dinosaurus een persoon te laten achtervolgen in DALL-E 2, ook al lijkt het concept van 'achtervolging' niet in de DALL-E 2 te zitten censuur systeem, en hoewel de lange geschiedenis van dinosaurusfilms zou overvloedige trainingsvoorbeelden moeten bieden (tenminste in de vorm van trailers en publiciteitsopnamen) voor deze anders onmogelijke ontmoeting van soorten.

Een typische DALL-E 2-reactie op de prompt 'Een kleurenfoto van een T-Rex die een man op een weg achtervolgt'. Bron: DALL-E 2
Ik heb ontdekt dat de bovenstaande afbeeldingen typerend zijn voor variaties op de '[dinosaurus] jaagt op [een persoon]' prompt ontwerp, en dat geen enkele mate van uitwerking in de prompt de T-Rex ertoe kan brengen om daadwerkelijk te voldoen. Op de eerste en tweede foto zit de man (min of meer) achter de T-Rex aan; in de derde, het benaderen met een terloopse minachting voor veiligheid; en in het uiteindelijke beeld, schijnbaar parallel aan het grote beest joggend. Bij ongeveer 10-15 pogingen met dit thema heb ik ontdekt dat de dinosaurus op dezelfde manier 'afgeleid' is.
Het kan zijn dat de enige trainingsgegevens waartoe DALL-E 2 toegang had, in de rij stonden 'man vecht dinosaurus', van publiciteitsopnamen voor oudere films zoals Een miljoen jaar voor Christus (1966), en die van Jeff Goldblum beroemde vlucht van de koning der roofdieren is gewoon een uitbijter in die kleine hoeveelheid gegevens.
* Mijn conversie van de inline citaten van de auteurs naar hyperlinks.
Voor het eerst gepubliceerd op 4 augustus 2022.











