
Mākslīgais intelekts
Bīstamība, izmantojot citātus, lai autentificētu NLG saturu

Domas Dabiskās valodas paaudzes modeļi, piemēram, GPT-3, ir tieksme uz "halucinācijām" materiālu, ko viņi sniedz faktiskās informācijas kontekstā. Laikmetā, kas ir ārkārtīgi norūpējies par uz tekstu balstītu viltus ziņu izplatību, šie “vēlas izpatikt” iedomu lidojumi ir eksistenciāls šķērslis automatizētu rakstīšanas un kopsavilkumu sistēmu attīstībai un nākotnei AI virzīta žurnālistika, starp dažādām citām dabiskās valodas apstrādes (NLP) apakšnozarēm.
Galvenā problēma ir tā, ka GPT stila valodu modeļi iegūst galvenās funkcijas un klases ļoti lieli korpusi apmācību tekstus un iemācīties izmantot šīs funkcijas kā valodas pamatelementus veikli un autentiski neatkarīgi no ģenerētā satura precizitātes vai pat tā pieņemamība.
Tādēļ NLG sistēmas pašlaik paļaujas uz faktu pārbaudi, ko veic cilvēks, izmantojot vienu no divām pieejām: ka modeļi tiek izmantoti kā sākuma teksta ģeneratori, kas nekavējoties tiek nodoti lietotājiem vai nu verifikācijai, vai kāda cita veida rediģēšanai vai pielāgošanai; vai cilvēki tiek izmantoti kā dārgi filtri, lai uzlabotu datu kopu kvalitāti, kas paredzētas mazāk abstraktiem un “radošiem” modeļiem (kuriem pašiem par sevi neizbēgami joprojām ir grūti uzticēties faktu precizitātes ziņā un kam būs nepieciešama papildu cilvēku pārraudzība). .
Vecas ziņas un viltus fakti
Dabiskās valodas paaudzes (NLG) modeļi spēj sniegt pārliecinošus un ticamus rezultātus, jo tie ir apguvuši semantisko arhitektūru, nevis abstraktāk asimilējot faktisko vēsturi, zinātni, ekonomiku vai jebkuru citu tēmu, par kuru tiem varētu būt nepieciešams izteikt viedokli. avota datos kā “pasažieri”.
Informācijas faktiskā precizitāte, ko ģenerē NLG modeļi, pieņem, ka ievade, uz kuru tie tiek apmācīti, pati par sevi ir uzticama un atjaunināta, kas rada ārkārtēju slogu attiecībā uz iepriekšēju apstrādi un turpmāku cilvēku veiktu verifikāciju — dārgi. klupšanas akmens, ko NLP pētniecības nozare pašlaik risina daudzās frontēs.
GPT-3 mēroga sistēmu apmācībai ir nepieciešams ārkārtīgi daudz laika un naudas, un, kad tās ir apmācītas, ir grūti atjaunināt, ko varētu uzskatīt par “kodola līmeni”. Lai gan uz sesijām balstītas un uz lietotāju balstītas lokālās modifikācijas var palielināt ieviesto modeļu lietderību un precizitāti, šīs noderīgās priekšrocības ir grūti, dažreiz neiespējamas, lai tās atgrieztos pamata modelī, neprasot pilnīgu vai daļēju pārkvalifikāciju.
Šī iemesla dēļ ir grūti izveidot apmācītus valodu modeļus, kas varētu izmantot jaunāko informāciju.

Teksts-davinci-002, kas tika apmācīts pat pirms COVID parādīšanās, — GPT-3 iterācija, ko tās veidotājs OpenAI uzskatīja par “visspējīgāko”, var apstrādāt 4000 marķieru vienā pieprasījumā, taču neko nezina par COVID-19 vai 2022. gada Ukrainas iebrukumu. (šie norādījumi un atbildes ir no 5. gada 2022. aprīļa). Interesanti, ka “nezināms” faktiski ir pieņemama atbilde abos neveiksmju gadījumos, taču turpmākie norādījumi viegli nosaka, ka GPT-3 nezina par šiem notikumiem. Avots: https://beta.openai.com/playground
Apmācīts modelis var piekļūt tikai “patiesībām”, ko tas internalizēja apmācības laikā, un ir grūti iegūt precīzu un atbilstošs citāts pēc noklusējuma, mēģinot panākt, lai modelis pārbaudītu savus apgalvojumus. Reālie draudi, iegūstot citātus no noklusējuma GPT-3 (piemēram), ir tādi, ka tas dažkārt rada pareizus citātus, radot nepatiesu pārliecību par šo tā iespēju aspektu:

Labākie, trīs precīzi citāti, kas iegūti, izmantojot 2021. gada davinci-instruct-text GPT-3. Centrā, GPT-3 nespēj citēt vienu no slavenākajiem Einšteina citātiem (“Dievs nespēlē kauliņus ar Visumu”), neskatoties uz neslēpto uzvedni. Apakšējā daļa, GPT-3 piešķir skandalozu un fiktīvu citātu Albertam Einšteinam, kas acīmredzami ir pārpildīts no iepriekšējiem jautājumiem par Vinstonu Čērčilu tajā pašā sesijā. Avots: paša autora 2021. gada raksts vietnē https://www.width.ai/post/business-applications-for-gpt-3
GopherCite
Cerot novērst šo vispārējo nepilnību NLG modeļos, Google DeepMind nesen ierosināja GopherCite, 280 miljardu parametru modelis, kas spēj norādīt konkrētus un precīzus pierādījumus, lai atbalstītu ģenerētās atbildes uz uzvednēm.


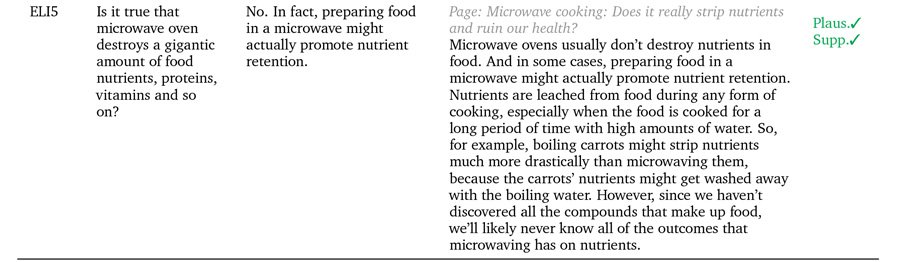
Trīs piemēri, kā GopherCite savus apgalvojumus pamato ar reāliem citātiem. Avots: https://arxiv.org/pdf/2203.11147.pdf
GopherCite izmanto pastiprinošu mācīšanos no cilvēka vēlmēm (RLHP), lai apmācītu vaicājumu modeļus, kas spēj norādīt reālus citātus kā apstiprinošus pierādījumus. Citāti tiek iegūti tiešraidē no vairākiem dokumentu avotiem, kas iegūti no meklētājprogrammām, vai arī no konkrēta lietotāja nodrošināta dokumenta.
GopherCite veiktspēja tika mērīta, cilvēku vērtējot modeļu atbildes, kuras 80% gadījumu Google tīklā tika konstatētas kā “augstas kvalitātes”. Dabiski jautājumi datu kopu, un 67% laika uz EL5 datu kopa.
Citējot viltus
Tomēr, pārbaudot pret Oksfordas universitāti PatiessQA Saskaņā ar etalonu, GopherCite atbildes reti tika novērtētas kā patiesas, salīdzinot ar cilvēku atlasītajām “pareizajām” atbildēm.
Autori norāda, ka tas ir tāpēc, ka jēdziens “atbalstītas atbildes” nekādā objektīvā veidā nepalīdz definēt patiesību pats par sevi, jo avota citātu lietderību var apdraudēt citi faktori, piemēram, iespēja, ka citāta autors. paši ir “halucinācijas” (ti, raksta par izdomātām pasaulēm, veido reklāmas saturu vai citādi fantastiski rada neautentisku materiālu.



GopherCite gadījumi, kad ticamība ne vienmēr ir vienāda ar "patiesību".
Šādos gadījumos faktiski kļūst nepieciešams atšķirt “atbalstītu” un “patiesu”. Cilvēka kultūra pašlaik ir tālu priekšā mašīnmācībai tādu metodoloģiju un ietvaru izmantošanā, kas izstrādāti, lai iegūtu objektīvas patiesības definīcijas, un pat tur šķiet, ka “svarīgās” patiesības pamatstāvoklis ir strīds un margināls noliegums.
Problēma ir rekursīva NLG arhitektūrās, kas cenšas izstrādāt galīgus “apstiprinošus” mehānismus: cilvēku vadīta vienprātība tiek izmantota kā patiesības etalons, izmantojot ārpakalpojumus, AMT-stila modeļi, kuros ir cilvēku vērtētāji (un tie citi cilvēki, kas ir starpnieks strīdos starp viņiem). paši par sevi daļēji un neobjektīvi.
Piemēram, sākotnējos GopherCite eksperimentos tiek izmantots “supervērtējuma” modelis, lai izvēlētos labākos cilvēkus, lai novērtētu modeļa rezultātus, atlasot tikai tos vērtētājus, kuri ieguvuši vismaz 85% punktu salīdzinājumā ar kvalitātes nodrošināšanas kopu. Visbeidzot uzdevumam tika atlasīti 113 supervērtētāji.
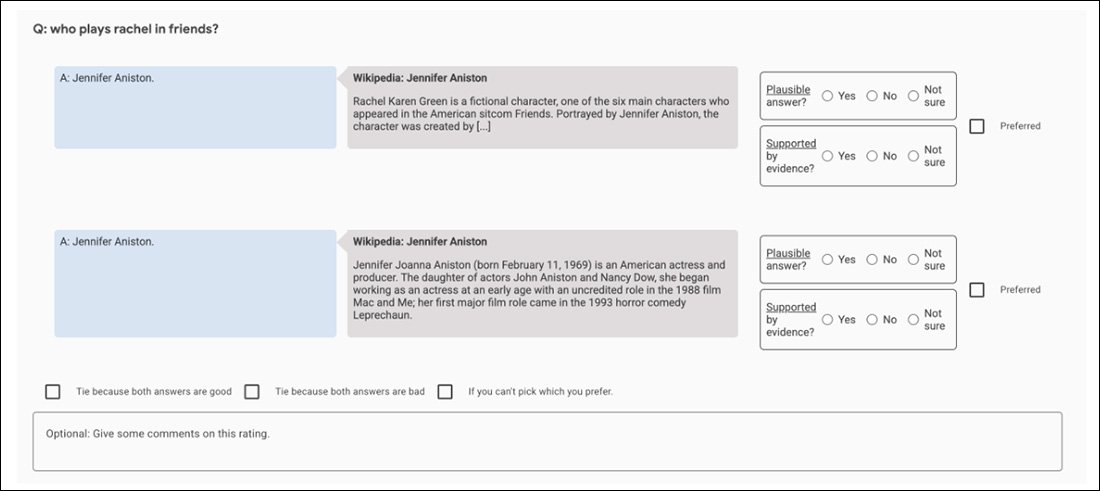
Ekrānuzņēmums ar salīdzināšanas lietotni, ko izmanto, lai palīdzētu novērtēt GopherCite rezultātu.
Iespējams, šis ir ideāls priekšstats par neuzvaramu fraktāļu meklējumu: kvalitātes nodrošināšanas komplekts, ko izmanto, lai novērtētu vērtētājus, pats par sevi ir vēl viens “cilvēka definēts” patiesības rādītājs, tāpat kā Oxford TruthfulQA komplekts, pret kuru GopherCite ir atrasts trūkums.
Runājot par atbalstīto un “autentificētu” saturu, viss, ko NLG sistēmas var cerēt sintezēt no apmācības par cilvēku datiem, ir cilvēku atšķirības un daudzveidība, kas pati par sevi ir nepareizi izvirzīta un neatrisināta problēma. Mums ir iedzimta tieksme citēt avotus, kas atbalsta mūsu uzskatus, un runāt autoritatīvi un ar pārliecību gadījumos, kad mūsu avota informācija var būt novecojusi, pilnīgi neprecīza vai citādi apzināti nepatiesa; un vēlme izplatīt šos viedokļus tieši savvaļā cilvēces vēsturē nepārspējamā mērogā un iedarbībā, tieši uz zināšanu skrāpēšanas ietvariem, kas nodrošina jaunus NLG ietvarus.
Tāpēc ar atsaucēm atbalstītu NLG sistēmu izstrādes radītās briesmas, šķiet, ir saistītas ar avota materiāla neparedzamību. Jebkurš mehānisms (piemēram, tieša atsauce un citāti), kas palielina lietotāju uzticību NLG izvadei, pašreizējā tehnikas līmenī bīstami palielina izvades autentiskumu, bet ne patiesumu.
Šādas metodes, visticamāk, būs pietiekami noderīgas, kad NLP beidzot atjaunos Orvela daiļliteratūras rakstīšanas "kaleidoskopus". Deviņpadsmit astoņdesmit četri; bet tie ir bīstami centieni pēc objektīvas dokumentu analīzes, uz mākslīgo intelektu vērstas žurnālistikas un citiem iespējamiem “ne-fiction” mašīnkopsavilkuma un spontānas vai vadītas teksta ģenerēšanas lietojumiem.
Pirmo reizi publicēts 5. gada 2022. aprīlī. Atjaunināts plkst. 3:29 EET, lai labotu terminu.















