
Mākslīgais intelekts
AI atbalstīta objektu rediģēšana, izmantojot Google Imagic un Runway funkciju "Dzēst un aizstāt"

Šonedēļ divi jauni, bet kontrastējoši AI vadīti grafikas algoritmi piedāvā jaunus veidus, kā galalietotāji var veikt ļoti detalizētas un efektīvas izmaiņas fotogrāfiju objektos.
Pirmais ir Maģisks, no Google Research sadarbībā ar Izraēlas Tehnoloģiju institūtu un Weizmann Zinātnes institūtu. Imagic piedāvā teksta kondicionētu, smalku objektu rediģēšanu, izmantojot difūzijas modeļu precizēšanu.

Mainiet to, kas jums patīk, un atstājiet pārējo — Imagic sola detalizētu rediģēšanu tikai tajās daļās, kuras vēlaties mainīt. Avots: https://arxiv.org/pdf/2210.09276.pdf
Ikviens, kurš kādreiz ir mēģinājis mainīt tikai vienu stabilas difūzijas atkārtotas renderēšanas elementu, ļoti labi zinās, ka katras veiksmīgas rediģēšanas gadījumā sistēma mainīs piecas lietas, kas jums patika tādas, kādas tās bija. Tas ir trūkums, kas pašlaik daudziem talantīgākajiem SD entuziastiem ir nepārtraukti mainījies starp Stable Diffusion un Photoshop, lai novērstu šāda veida “nodrošinājuma bojājumus”. No šī viedokļa vien Imagic sasniegumi šķiet ievērojami.
Rakstīšanas laikā Imagic vēl nebija pat reklāmas video un, ņemot vērā Google apdomīga attieksme lai atbrīvotu neierobežotus attēlu sintēzes rīkus, nav skaidrs, cik lielā mērā mēs iegūsim iespēju pārbaudīt sistēmu, ja tāda ir.
Otrais piedāvājums ir Runway ML diezgan pieejamāks Dzēst un aizstāt iekārta, a jauna iezīme sadaļā “AI Magic Tools” tās tikai tiešsaistes mašīnmācības vizuālo efektu utilītprogrammu komplektā.
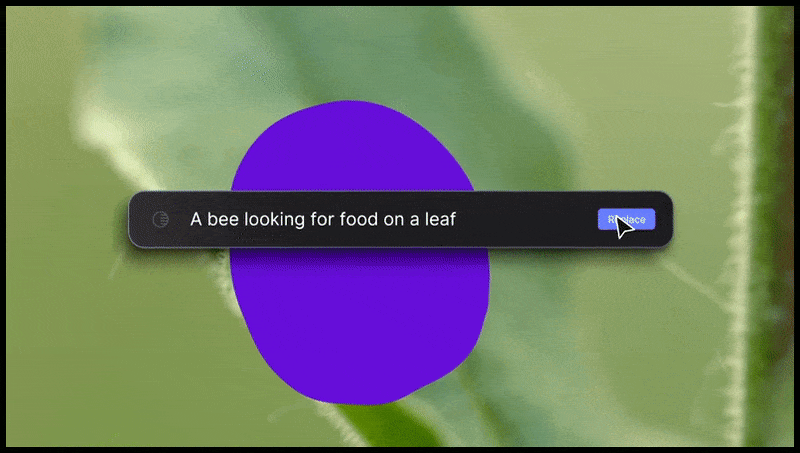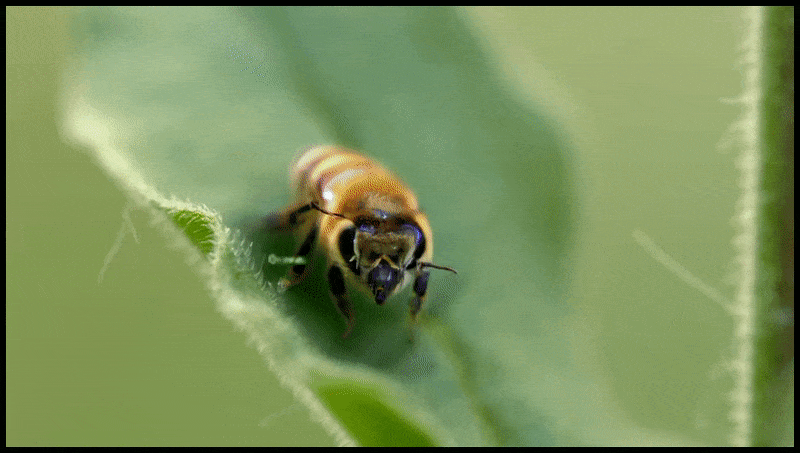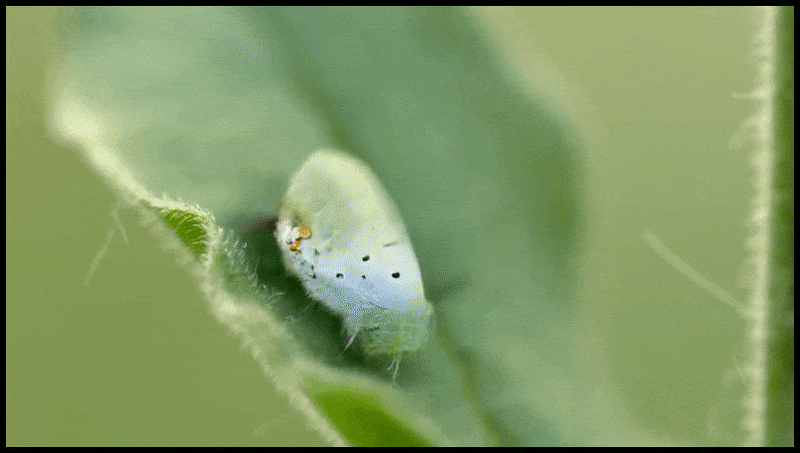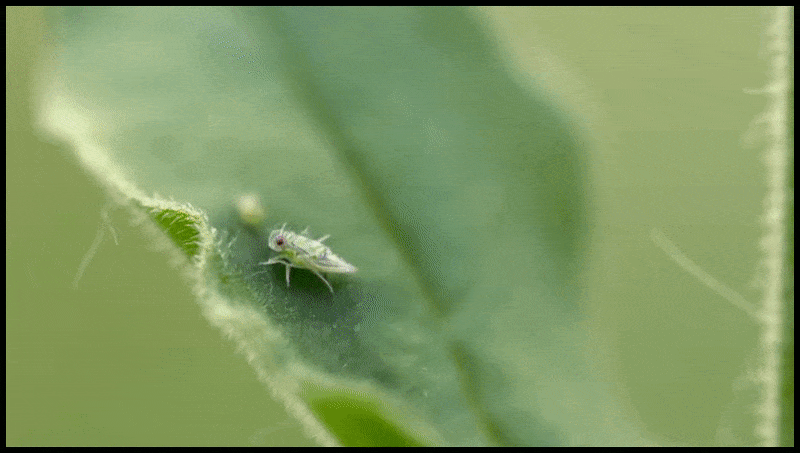
Runway ML funkcija Erase and Replace, kas jau ir redzama teksta pārveides video rediģēšanas sistēmas priekšskatījumā. Avots: https://www.youtube.com/watch?v=41Qb58ZPO60
Vispirms apskatīsim Runway izbraucienu.
Dzēst un aizstāt
Tāpat kā Imagic, Erase and Replace attiecas tikai uz nekustīgiem attēliem, lai gan Runway to ir darījis priekšskatīt tā pati funkcionalitāte teksta-video rediģēšanas risinājumā, kas vēl nav izlaists:

Lai gan ikviens var izmēģināt jauno funkciju Dzēst un aizstāt ar attēliem, video versija vēl nav publiski pieejama. Avots: https://twitter.com/runwayml/status/1568220303808991232
Lai gan uzņēmums Runway ML nav izlaidis sīkāku informāciju par tehnoloģijām, kas ir pamatā dzēst un aizstāt, ātrums, ar kādu jūs varat aizstāt telpaugu ar pietiekami pārliecinošu Ronalda Reigana krūšutēlu, liecina, ka difūzijas modelis, piemēram, Stable Diffusion (vai, daudz mazāk ticams, Licencēts DALL-E 2) ir dzinējs, kas no jauna izgudro jūsu izvēlēto objektu sadaļā Dzēst un aizstāt.

Mājas auga aizstāšana ar The Gipper krūšutēlu nav tik ātra kā šī, taču tā ir diezgan ātra. Avots: https://app.runwayml.com/
Sistēmai ir daži DALL-E 2 tipa ierobežojumi — attēli vai teksts, kas apzīmē filtrus Dzēst un Aizstāt, aktivizēs brīdinājumu par iespējamu konta apturēšanu turpmāku pārkāpumu gadījumā — praktiski tas ir OpenAI pastāvīgā klons. Politika priekš DALL-E 2 .
Daudziem rezultātiem trūkst stabilas difūzijas tipiskās neapstrādātās malas. Skrejceļš ML ir investori un pētniecības partneri SD, un iespējams, ka viņi ir apmācījuši patentētu modeli, kas ir pārāks par atvērtā pirmkoda 1.4 kontrolpunktu svariem, ar kuriem mēs, pārējie, pašlaik cīnāmies (tāpat kā daudzas citas attīstības grupas, gan hobiju, gan profesionāļu, pašlaik trenējas vai precizē Stabilas difūzijas modeļi).
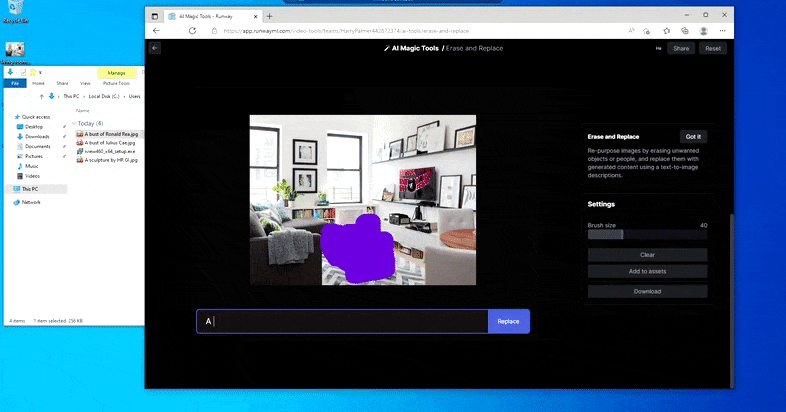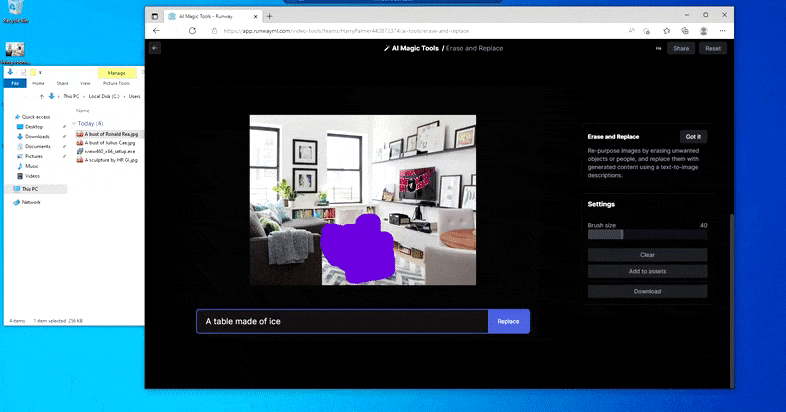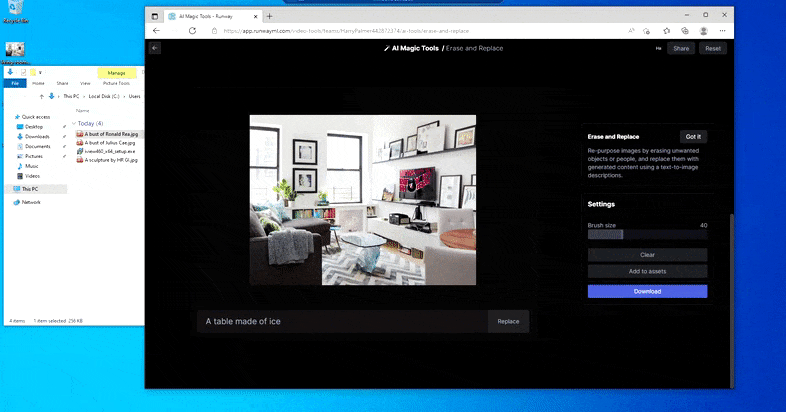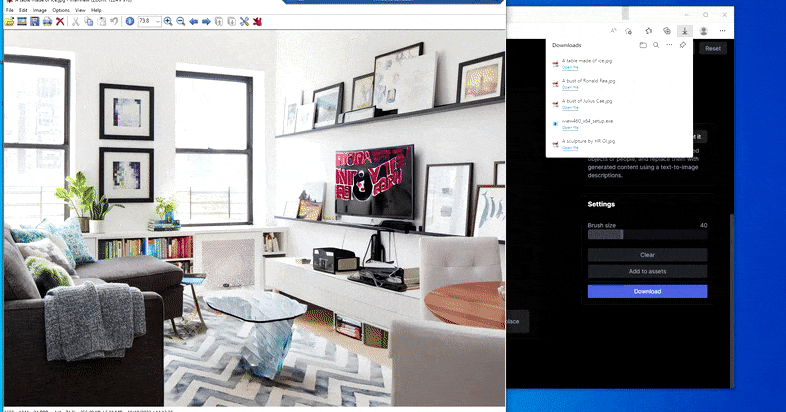
Mājas galda aizstāšana ar “ledus galdu” Runway ML programmā Erase and Replace.
Tāpat kā ar Imagic (skatiet tālāk), funkcija Erase and Replace it kā ir "objektorientēta" — jūs nevarat vienkārši izdzēst attēla "tukšo" daļu un iekrāsot to ar teksta uzvednes rezultātu; tādā gadījumā sistēma vienkārši izsekos tuvākajam šķietamajam objektam gar maskas redzamības līniju (piemēram, sienu vai televizoru) un izmantos tur pārveidojumu.
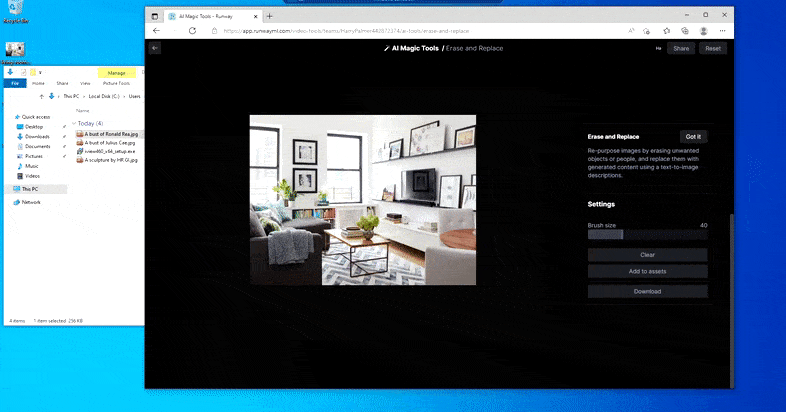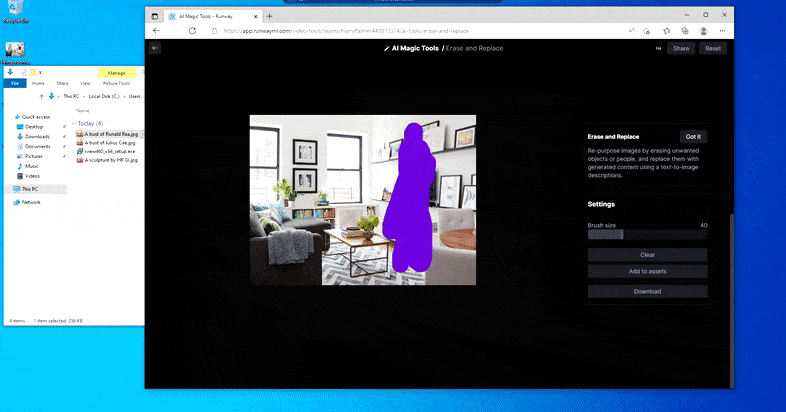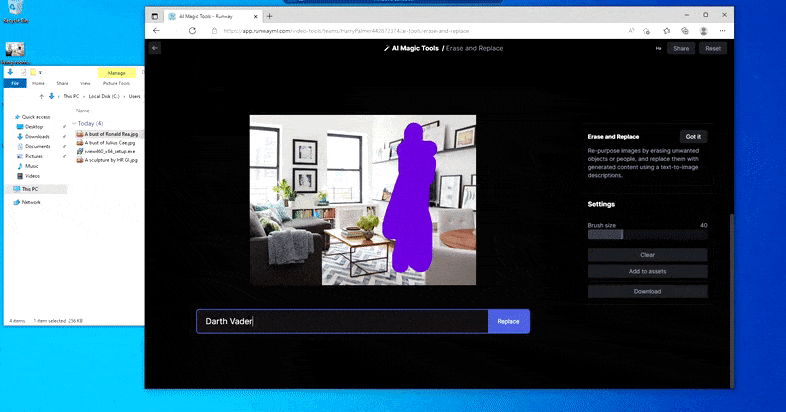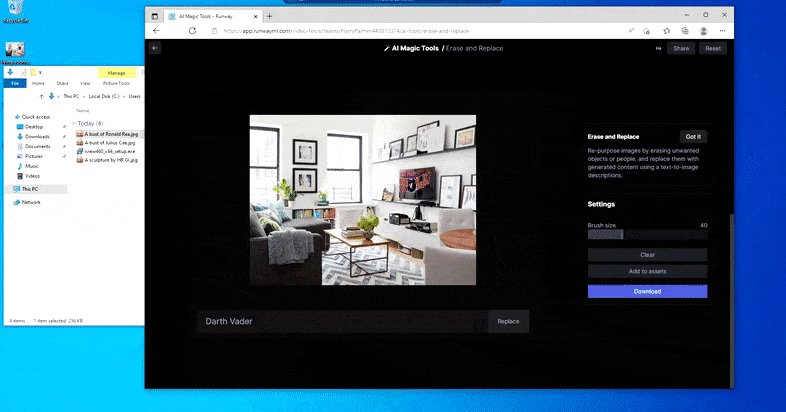
Kā norāda nosaukums, jūs nevarat ievadīt objektus tukšā vietā, izmantojot funkciju Dzēst un aizstāt. Mēģinot izsaukt slavenākos Situ lordus, televizorā tiek parādīts dīvains ar Vaderu saistīts sienas gleznojums, kurā aptuveni tika uzzīmēts “aizstāt” laukums.
Ir grūti noteikt, vai dzēst un aizstāt ir izvairīgi izmantot ar autortiesībām aizsargātus attēlus (kas joprojām lielā mērā ir traucēti, lai gan ar mainīgiem panākumiem DALL-E 2), vai arī modelis tiek izmantots aizmugures renderēšanas programmā. vienkārši nav optimizēts šāda veida lietām.

Nedaudz NSFW “Nikolas Kidmenas sienas gleznojums” norāda, ka (domājams) uz difūziju balstītajam modelim trūkst DALL-E 2 agrākā sistemātiskā atteikuma no reālistisku seju atveidošanas vai satriecoša satura, savukārt rezultāti mēģinājumos parādīt ar autortiesībām aizsargātus darbus atšķiras no neviennozīmīgiem. ("ksenomorfs") līdz absurdam ("dzelzs tronis"). Ievietots apakšā pa labi, avota attēls.
Būtu interesanti uzzināt, kādas metodes Erase and Replace izmanto, lai izolētu objektus, kurus tā spēj aizstāt. Iespējams, attēls tiek palaists caur kādu atvasinājumu CLIP, ar diskrētiem vienumiem, kas ir individualizēti ar objektu atpazīšanu un sekojošu semantisko segmentāciju. Neviena no šīm darbībām nedarbojas tikpat labi, ja tiek uzstādīta Stable Diffusion parastajā vai dārzā.
Bet nekas nav ideāls — dažreiz šķiet, ka sistēma dzēš un neaizstāj, pat ja (kā mēs redzējām attēlā iepriekš), pamatā esošais renderēšanas mehānisms noteikti zina, ko nozīmē teksta uzvedne. Šajā gadījumā kafijas galdiņu pārvērst par ksenomorfu nav iespējams – drīzāk galds vienkārši pazūd.
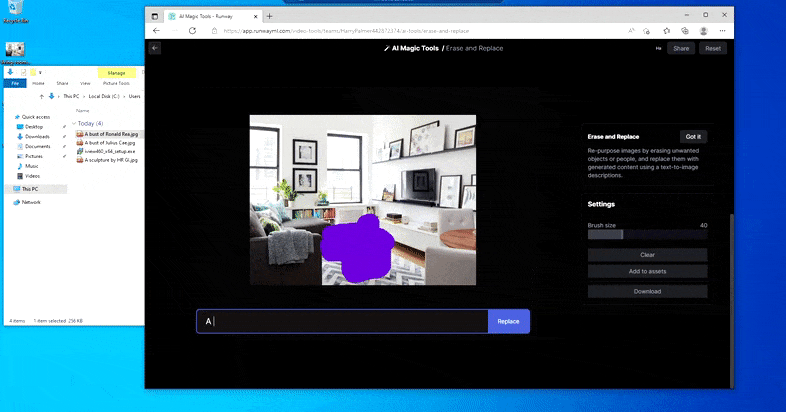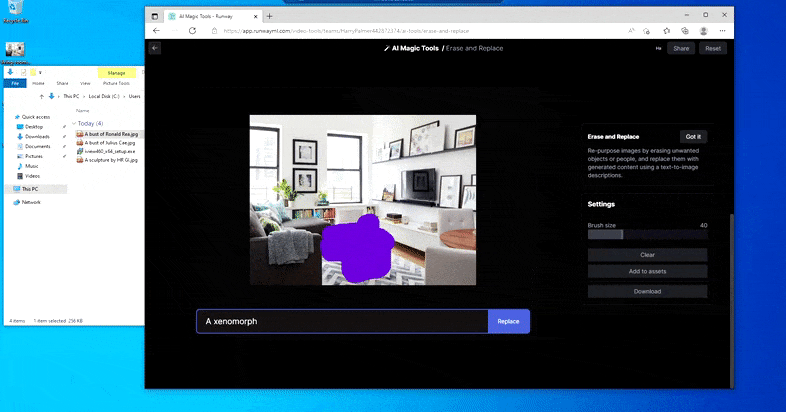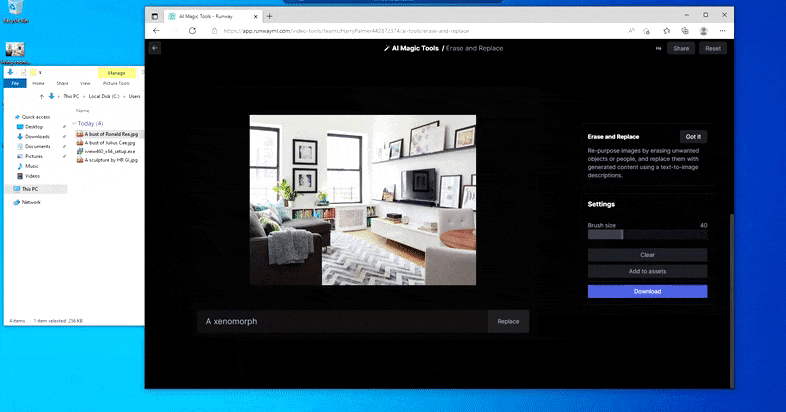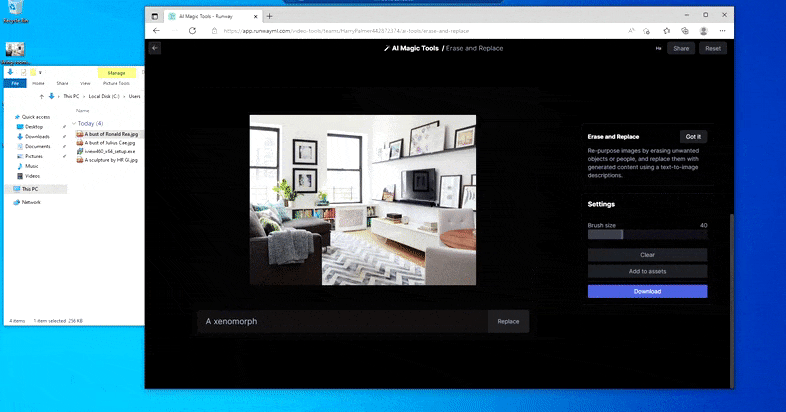
Biedējošāks atkārtojums “Where's Waldo”, jo dzēst un aizstāt neizdodas radīt citplanētieti.
Izdzēst un aizstāt, šķiet, ir efektīva objektu aizstāšanas sistēma ar izcilu iekrāsošanu. Tomēr tas nevar rediģēt esošos uztvertos objektus, bet tikai tos aizstāt. Faktiski mainīt esošo attēlu saturu, neapdraudot apkārtējās vides materiālu, neapšaubāmi ir daudz grūtāks uzdevums, kas saistīts ar datorredzes pētniecības sektora ilgo cīņu pret atdalīšana populāro sistēmu dažādās latentās telpās.
Maģisks
Tas ir uzdevums, ko Imagic risina. The jauns papīrs piedāvā daudzus labojumu piemērus, kas veiksmīgi maina atsevišķas fotoattēla šķautnes, atstājot pārējo attēla daļu neskartu.

Programmā Imagic grozītie attēli necieš no raksturīgās stiepšanās, izkropļošanas un “oklūzijas minēšanas”, kas raksturīga dziļi viltotai leļļu teātrim, kas izmanto ierobežotas prioritātes, kas iegūtas no viena attēla.
Sistēmā tiek izmantots trīs posmu process – teksta iegulšanas optimizācija; modeļa precizēšana; un, visbeidzot, grozītā attēla ģenerēšana.

Imagic kodē mērķa teksta uzvedni, lai izgūtu sākotnējo teksta iegulšanu, un pēc tam optimizē rezultātu, lai iegūtu ievades attēlu. Pēc tam ģeneratīvais modelis tiek precīzi pielāgots avota attēlam, pievienojot parametru diapazonu, pirms tam tiek veikta pieprasītā interpolācija.
Nav pārsteidzoši, ka sistēma ir balstīta uz Google Attēls teksta-video arhitektūra, lai gan pētnieki apgalvo, ka sistēmas principi ir plaši piemērojami latentās difūzijas modeļiem.
Imagen izmanto trīs līmeņu arhitektūru, nevis septiņu līmeņu masīvu, ko izmanto uzņēmuma jaunākajai versijai. teksta-video iterācija no programmatūras. Trīs atšķirīgie moduļi ietver ģeneratīvu difūzijas modeli, kas darbojas ar 64x64 pikseļu izšķirtspēju; superizšķirtspējas modelis, kas palielina šo izvadi līdz 256x256 pikseļiem; un papildu superizšķirtspējas modelis, kas nodrošina izvadi līdz pat 1024 × 1024 izšķirtspējai.
Imagic iejaucas šī procesa agrākajā posmā, optimizējot pieprasīto teksta iegulšanu 64 pikseļu stadijā Adam optimizētājā ar statisko mācīšanās ātrumu 0.0001.

Atdalīšanas meistarklase: tie galalietotāji, kuri ir mēģinājuši mainīt kaut ko tik vienkāršu kā atveidota objekta krāsu difūzijas, GAN vai NeRF modelī, zinās, cik svarīgi ir tas, ka Imagic var veikt šādas transformācijas, nesadaloties. ' pārējā attēla konsekvenci.
Pēc tam tiek veikta precīza regulēšana Imagen bāzes modelī, veicot 1500 soļus katram ievades attēlam, kas ir saistīts ar pārskatīto iegulšanu. Tajā pašā laikā kondicionētajā attēlā paralēli tiek optimizēts sekundārais 64 pikseļu > 256 pikseļu slānis. Pētnieki atzīmē, ka līdzīga optimizācija galīgajam 256 pikseļu > 1024 pikseļu slānim “maz vai nemaz neietekmē” gala rezultātus, un tāpēc viņi to nav ieviesuši.
Rakstā teikts, ka optimizācijas process aizņem apmēram astoņas minūtes katram attēlam dvīņos TPUV4 čipsi. Galīgā renderēšana notiek galvenajā Imagen zem DDIM izlases shēma.
Tāpat kā līdzīgiem Google precizēšanas procesiem sapņu kabīne, iegūtos iegulumus var papildus izmantot, lai aktivizētu stilizāciju, kā arī fotoreālistiskus labojumus, kas satur informāciju, kas iegūta no plašākas pamatā esošās datu bāzes, kas darbina Imagen (jo, kā parādīts pirmajā kolonnā, avota attēliem nav nekāda nepieciešamā satura, lai ietekmē šīs pārvērtības).

Elastīgu fotoreālu kustību un rediģēšanu var panākt, izmantojot Imagic, savukārt procesā iegūtos atvasinātos un atdalītos kodus var tikpat viegli izmantot stilizētai izvadei.
Pētnieki salīdzināja Imagic ar iepriekšējiem darbiem SDEdit, uz GAN balstīta pieeja no 2021. gada, sadarbība starp Stenfordas Universitāti un Kārnegija Melona universitāti; un Text2Live2022. gada aprīļa sadarbība starp Veizmaņa Zinātņu institūtu un NVIDIA.

Imagic, SDEdit un Text2Live vizuāls salīdzinājums.
Ir skaidrs, ka iepriekšējām pieejām ir grūtības, taču apakšējā rindā, kas ietver masveida pozas maiņu, vēsturiskie operatori nespēj pilnībā pārveidot izejmateriālu, salīdzinot ar ievērojamiem Imagic panākumiem.
Imagic resursu prasības un apmācības laiks vienam attēlam, lai gan tas ir īss saskaņā ar šādu darbību standartiem, padara to maz ticamu iekļaušanu vietējā attēlu rediģēšanas lietojumprogrammā personālajos datoros, un nav skaidrs, cik lielā mērā precizēšanas process varētu būt. samazināts līdz patērētāju līmenim.
Pašreizējā redakcijā Imagic ir iespaidīgs piedāvājums, kas ir vairāk piemērots API — Google Research vide, kas ir ļoti kritizēta par dziļās viltošanas atvieglošanu, jebkurā gadījumā var būt visērtākā.
Pirmo reizi publicēts 18. gada 2022. oktobrī.















