인공지능
Gemma 2 완벽 가이드: Google의 새로운 오픈 대형 언어 모델

Gemma 2는其 전신보다 향상된 성능과 효율성을 제공하며, 연구 및 실제 적용 모두에 적합한 다양한 혁신적인 기능을 제공합니다. Gemma 2를 отлич하는 것은 대형 사유 모델과 비교할 수 있는 성능을 제공하지만, 더广泛한 접근성과 더 MODEST한 하드웨어 설정에서 사용할 수 있도록 설계된 패키지입니다.
Gemma 2의 기술 사양과 아키텍처를 자세히 살펴보면, 설계의 지능에越来越 감명을 받습니다. 모델은 여러 가지 고급 기술을 통합하여, 새로운 주의 메커니즘과 훈련 안정성에 대한 혁신적인 접근 방식을 포함하여, 其의卓越한 능력을 발휘합니다.

Google Open Source LLM Gemma
이 всесторон적인 가이드에서, 우리는 Gemma 2를 깊이 있게 살펴보며, 其의 아키텍처, 주요 기능 및 실제 적용을 살펴보겠습니다. 경험豊富한 AI 전문가이거나, 분야의 열정적인 신규 입사자이든, 본 문서는 Gemma 2의 작동 방식과 귀하의 프로젝트에서 其의 힘을 어떻게 활용할 수 있는지에 대한 유용한 통찰력을 제공합니다.
Gemma 2란 무엇인가?
Gemma 2는 Google의最新 오픈 소스 대형 언어 모델로, 가볍지만 강력한 설계입니다. Gemini 모델을 생성하기 위해 사용된 동일한 연구와 기술을 기반으로 하며, 더 접근하기 쉬운 패키지에서 최첨단 성능을 제공합니다. Gemma 2는 두 가지 크기로 제공됩니다.
Gemma 2 9B: 9 억 매개 변수 모델
Gemma 2 27B: 27 억 매개 변수 모델
각 크기는 두 가지 변형으로 제공됩니다.
기본 모델:大量의 텍스트 데이터에 사전 훈련됨
지시 튜닝 (IT) 모델: 특정 작업에 대한 성능을 개선하기 위해 미세 조정됨
Google AI Studio에서 모델에 액세스: Google AI Studio – Gemma 2
기술 보고서를 읽으십시오: Gemma 2 기술 보고서
주요 기능 및 개선 사항
Gemma 2는 전신보다 몇 가지 중요한 발전을 도입합니다:
1. 훈련 데이터 증가
모델은 훨씬 더 많은 데이터로 훈련되었습니다.
Gemma 2 27B: 13 trillion 토큰으로 훈련됨
Gemma 2 9B: 8 trillion 토큰으로 훈련됨
이 확장된 데이터 세트는 주로 웹 데이터(대부분 영어), 코드 및 수학으로 구성되어 있으며, 모델의 성능과 다용도성을 향상시킵니다.
2. 슬라이딩 윈도우 주의
Gemma 2는 주의 메커니즘에 대한 새로운 접근 방식을 구현합니다.
매번 다른 레이어는 4096 토큰의 로컬 컨텍스트를 사용하는 슬라이딩 윈도우 주의를 사용합니다.
교대로 레이어는 전체 8192 토큰 컨텍스트에서 완전한 사각형 글로벌 주의를 사용합니다.
이 하이브리드 접근 방식은 효율성과 입력의 长距離 의존성을 캡처하는 능력을 균형 있게 합니다.
3. 소프트 캡핑
훈련 안정성과 성능을 개선하기 위해 Gemma 2는 소프트 캡핑 메커니즘을 도입합니다.
def soft_cap(x, cap): return cap * torch.tanh(x / cap) # 주의 로짓에 적용 attention_logits = soft_cap(attention_logits, cap=50.0) # 최종 레이어 로짓에 적용 final_logits = soft_cap(final_logits, cap=30.0)
이 기술은 로짓이 지나치게 커지지 않도록 방지하면서, 하드 트렁케이션 없이 더 많은 정보를 유지하고 훈련 과정을 안정화합니다.
- Gemma 2 9B: 9 억 매개 변수 모델
- Gemma 2 27B: 27 억 매개 변수 모델
각 크기는 두 가지 변형으로 제공됩니다.
- 기본 모델:大量의 텍스트 데이터에 사전 훈련됨
- 지시 튜닝 (IT) 모델: 특정 작업에 대한 성능을 개선하기 위해 미세 조정됨
4. 지식 증류
9B 모델의 경우, Gemma 2는 지식 증류 기술을 사용합니다.
- 사전 훈련: 9B 모델은 초기 훈련 중에 더 큰 교사 모델에서 학습합니다.
- 사후 훈련: 9B 및 27B 모델은 모두 정책 증류를 사용하여 성능을 정제합니다.
이 과정은 더 작은 모델이 더 큰 모델의 능력을 더 효과적으로 캡처하도록 도와줍니다.
5. 모델 병합
Gemma 2는 세 단계에서 여러 모델을 결합하는 새로운 모델 병합 기술인 Warp를 사용합니다.
- 강화 학습 미세 조정 중에 지수 이동 평균 (EMA)
- 여러 정책을 미세 조정한 후 구형 선형 보간 (SLERP)
- 초기화로의 선형 보간 (LITI)作为 최종 단계
이 접근 방식은 더 강력하고 능숙한 최종 모델을 생성하도록 설계되었습니다.
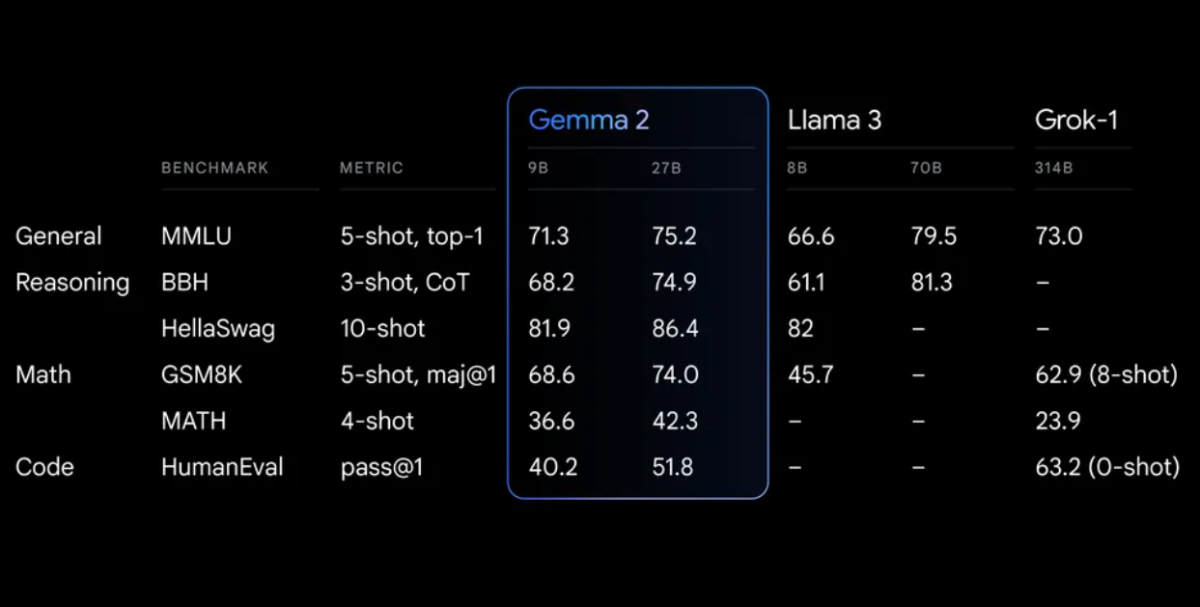
성능 벤치마크
Gemma 2는 다양한 벤치마크에서 인상적인 성능을 보여줍니다.
Gemma 2 on a redesigned architecture, engineered for both exceptional performance and inference efficiency
Gemma 2 시작하기
프로젝트에서 Gemma 2를 사용하기 시작하려면 몇 가지 옵션이 있습니다.
1. Google AI Studio
하드웨어 요구 사항 없이 빠른 실험을 위해 Gemma 2에 액세스할 수 있습니다. Google AI Studio를 사용하십시오.
2. Hugging Face Transformers
Gemma 2는 인기 있는 Hugging Face Transformers 라이브러리에 통합되어 있습니다. 다음은 사용 방법입니다.
<div class="relative flex flex-col rounded-lg"> <div class="text-text-300 absolute pl-3 pt-2.5 text-xs"> from transformers import AutoTokenizer, AutoModelForCausalLM # 모델과 토크나이저 로드 model_name = "google/gemma-2-27b-it" # 또는 "google/gemma-2-9b-it"을(를) 사용하여 더 작은 버전 tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForCausalLM.from_pretrained(model_name) # 입력 준비 prompt = "양자 얽힘의 개념을 간단한 용어로 설명하십시오." inputs = tokenizer(prompt, return_tensors="pt") # 텍스트 생성 outputs = model.generate(**inputs, max_length=200) response = tokenizer.decode(outputs[0], skip_special_tokens=True) print(response)
3. TensorFlow/Keras
TensorFlow 사용자의 경우 Gemma 2는 Keras를 통해 사용할 수 있습니다.
import tensorflow as tf from keras_nlp.models import GemmaCausalLM # 모델 로드 model = GemmaCausalLM.from_preset("gemma_2b_en") # 텍스트 생성 prompt = "양자 얽힘의 개념을 간단한 용어로 설명하십시오." output = model.generate(prompt, max_length=200) print(output)
고급 사용: Gemma 2와 함께 로컬 RAG 시스템 구축
Gemma 2의 강력한 응용 프로그램 중 하나는 Retrieval Augmented Generation (RAG) 시스템을 구축하는 것입니다. Gemma 2와 Nomic 임베딩을 사용하여 간단한 로컬 RAG 시스템을 생성해 보겠습니다.
단계 1: 환경 설정
먼저 필요한 라이브러리가 설치되어 있는지 확인하십시오.
pip install langchain ollama nomic chromadb
단계 2: 문서 색인화
문서를 처리하기 위한 색인기를 생성합니다.
import os
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import DirectoryLoader
from langchain.vectorstores import Chroma
from langchain.embeddings import HuggingFaceEmbeddings












