인공지능
Auto-GPT & GPT-Engineer: 오늘의 선도적인 AI 에이전트에 대한 심층 가이드

ChatGPT와 Auto-GPT, GPT-Engineer와 같은 자율적 AI 에이전트를 비교할 때 의사 결정 과정에서 상당한 차이가 나타납니다. ChatGPT는 대화 주도하기 위해 활발한 인간의 개입을 필요로 하며 사용자 프롬프트에 따라 지침을 제공하는 반면, 계획 과정은 주로 인간의 개입에 의존합니다.
제너레이티브 AI 모델인 트랜스포머는 이러한 자율적 AI 에이전트의 핵심 기술입니다. 이러한 트랜스포머는 대규모 데이터셋에서 훈련되어 복잡한推論 및 의사 결정 능력을 시뮬레이션할 수 있습니다.
자율 에이전트의 오픈 소스 루츠: Auto-GPT와 GPT-Engineer
이러한 자율적 AI 에이전트 중 많은 수가 혁신적인 개인이 전통적인 워크플로를 변환하는 오픈 소스 이니셔티브에서 비롯됩니다. 단순히 제안을 제공하는 것보다 Auto-GPT와 같은 에이전트는 온라인 쇼핑부터 기본 앱 구축까지 독립적으로 작업을 처리할 수 있습니다. OpenAI의 코드 인터프리터는 ChatGPT를 단순히 아이디어를 제안하는 것에서 그 아이디어로 문제를 해결하는 것으로 업그레이드하는 것을 목표로 합니다.
Auto-GPT와 GPT-Engineer는 모두 GPT 3.5와 GPT-4의 힘을 가지고 있습니다. 코드 논리를 이해하고 여러 파일을 결합하며 개발 프로세스를 가속화합니다.
Auto-GPT의 핵심 기능은 그 에이전트에 있습니다. 이러한 에이전트는 스케줄링과 같은 단순한 작업부터 전략적 의사 결정을 요구하는 더 복잡한 작업에 이르기까지 특정 작업을 수행하도록 프로그래밍됩니다. 그러나 이러한 AI 에이전트는 사용자가 설정한 경계 내에서 작동합니다. API를 통해 액세스를 제어함으로써 사용자는 AI가 수행할 수 있는 작업의 깊이와 범위를 결정할 수 있습니다.
예를 들어, ChatGPT와 통합된 채팅 웹 앱을 생성하는 경우 Auto-GPT는 목표를 실행 가능한 단계로 자동으로 분해합니다. 예를 들어 HTML 프론트 엔드 또는 Python 백엔드를 스크립팅하는 것입니다. 이 애플리케이션이 이러한 프롬프트를 자동으로 생성하는 동안 사용자는 여전히 모니터링하고 수정할 수 있습니다. AutoGPT의 제작자 @SigGravitas에 의해 보여지듯이, Python에 기반한 테스트 프로그램을 구축하고 실행할 수 있습니다.
https://twitter.com/SigGravitas/status/1642181498278408193
아래 다이어그램은 더 일반적인 자율적 AI 에이전트의 아키텍처를 설명하지만, 뒤쪽의 프로세스에 대한 유용한 통찰력을 제공합니다.

자율적 AI 에이전트 아키텍처
이 프로세스는 OpenAI API 키를 확인하고 초기화하는 여러 매개 변수,包括 짧은 기간의 메모리와 데이터베이스 내용을 포함한 프로세스로 시작됩니다. 일단 키 데이터가 에이전트에 전달되면 모델은 GPT3.5/GPT4와 상호 작용하여 응답을 가져옵니다. 이 응답은 JSON 형식으로 변환되어 에이전트가 다양한 함수를 실행할 수 있게 합니다. 예를 들어, 온라인 검색, 파일 읽기 또는 쓰기, 또는 코드 실행이 있습니다. Auto-GPT는 이러한 응답을 데이터베이스에 저장하는 사전 훈련된 모델을 사용하며, 향후 상호 작용은 이 저장된 정보를 참조하여 사용합니다. 루프는 작업이 완료될 때까지 계속됩니다.
Auto-GPT와 GPT-Engineer 설정 가이드
Auto-GPT와 GPT-Engineer와 같은 최신 도구를 설정하면 개발 프로세스를 간소화할 수 있습니다. 아래는 두 도구를 설치하고 구성하는 데 도움이 되는 구조화된 가이드입니다.
Auto-GPT
Auto-GPT를 설정하는 것은 복잡해 보일 수 있지만 올바른 단계를 따라하면 간단해집니다. 이 가이드는 Auto-GPT를 설정하는 절차와 다양한 시나리오에 대한 통찰력을 제공합니다.
1. 사전 요구 사항:
- 파이썬 환경: 파이썬 3.8 이상이 설치되어 있는지 확인하십시오. 파이썬은 공식 웹사이트에서 얻을 수 있습니다.
- 리포지토리를 클론할 계획이라면 Git을 설치하십시오.
- OpenAI API 키: OpenAI와 상호 작용하려면 API 키가 필요합니다. OpenAI 계정에서 키를 얻으십시오

Open AI API 키 생성
메모리 백엔드 옵션: 메모리 백엔드는 AutoGPT가 작업에 필요한 데이터에 액세스하는 데 사용되는 저장 메커니즘입니다. AutoGPT는 단기 및 장기 저장 능력을 모두 사용합니다. Pinecone, Milvus, Redis 등이 사용 가능한 옵션입니다.
2. 작업 공간 설정:
- 가상 환경을 생성합니다:
python3 -m venv myenv - 환경을 활성화합니다:
- MacOS 또는 Linux:
source myenv/bin/activate
- MacOS 또는 Linux:
3. 설치:
- Auto-GPT 리포지토리를 클론합니다 (Git이 설치되어 있는지 확인하십시오):
git clone https://github.com/Significant-Gravitas/Auto-GPT.git - Auto-GPT의 버전 0.2.2에서 작업하려면 해당 버전으로 체크아웃합니다:
git checkout stable-0.2.2 - 다운로드된 리포지토리로 이동합니다:
cd Auto-GPT - 필요한 종속성을 설치합니다:
pip install -r requirements.txt
4. 구성:
- 메인
/Auto-GPT디렉토리에서.env.template을 찾습니다. 이를 복사하여.env로 이름을 변경합니다 .env를 열고 OpenAI API 키를OPENAI_API_KEY=옆에 설정합니다- 비슷하게, Pinecone 또는 다른 메모리 백엔드를 사용하려면
.env파일을 Pinecone API 키와 지역으로 업데이트합니다.
5. 명령줄 지침:
Auto-GPT는其 동작을 사용자 지정하는 데 사용할 수 있는豊富한 명령줄 인수를 제공합니다:
- 일반 사용::
- 도움말 표시:
python -m autogpt --help - AI 설정 조정:
python -m autogpt --ai-settings <파일 이름> - 메모리 백엔드 지정:
python -m autogpt --use-memory <메모리 백엔드>
- 도움말 표시:

AutoGPT CLI
6. Auto-GPT 시작:
구성이 완료되면 다음을 사용하여 Auto-GPT를 시작합니다:
- Linux 또는 Mac:
./run.sh start - Windows:
.run.bat
도커 통합 (권장 설정 접근 방식)
Auto-GPT를 컨테이너화하려는 사람들을 위해 도커는 간소화된 접근 방식을 제공합니다. 그러나 도커의 초기 설정은 약간 복잡할 수 있습니다. 도커의 설치 가이드를 참조하여 도움을 받으십시오.
다음 단계에 따라 OpenAI API 키를 수정합니다. 도커가 백그라운드에서 실행되고 있는지 확인하십시오. 이제 AutoGPT의 주요 디렉토리로 이동하여 터미널에서 다음 단계를 따르십시오
- 도커 이미지 빌드:
docker build -t autogpt . - 이제 실행:
docker run -it --env-file=./.env -v$PWD/auto_gpt_workspace:/app/auto_gpt_workspace autogpt
도커 컴포즈와 함께:
- 실행:
docker-compose run --build --rm auto-gpt - 추가 사용자 지정하려면 추가 인수를 통합할 수 있습니다. 예를 들어, –gpt3only 및 –continuous와 함께 실행하려면:
docker-compose run --rm auto-gpt --gpt3only--continuous - 대규모 데이터 세트에서 콘텐츠를 생성하는 Auto-GPT의 광범위한 자율성으로 인해 의도하지 않게 악의적인 웹 소스를 액세스할 수 있는 잠재적인 위험이 있습니다.
위험을 완화하려면 도커와 같은 가상 컨테이너 내에서 Auto-GPT를 운영하여 의도하지 않은 콘텐츠가 외부 파일 및 시스템에 영향을 미치지 않도록 합니다. 또는 Windows 샌드박스를 사용할 수 있지만 각 세션이 종료될 때 상태를 유지하지 못합니다.
보안을 위해 항상 가상 환경에서 Auto-GPT를 실행하여 시스템이 예기치 않은 출력으로부터 격리되도록 합니다.
이 모든 것에도 불구하고, 원하는 결과를 얻지 못할 수 있습니다. Auto-GPT 사용자는 파일에 쓸 때 반복적인 문제를 보고했으며, 종종 파일 이름 문제로 인해 시도가 실패했습니다. 여기에는 다음과 같은 오류가 포함됩니다: Auto-GPT (릴리스 0.2.2)가 텍스트를 추가하지 못함. 오류 "write_to_file returned: 오류: 파일이 이미 업데이트되었습니다.
이 문제를 해결하기 위한 다양한 솔루션은 관련 GitHub 스레드에서 참조하실 수 있습니다.
GPT-Engineer
GPT-Engineer 워크플로:
- 프롬프트 정의: 프로젝트에 대한 자세한 설명을 자연어로 작성합니다.
- 코드 생성: 프롬프트에 따라 GPT-Engineer는 코드 스니펫, 함수 또는 전체 애플리케이션을 생성합니다.
- 개선 및 최적화: 생성 후에는 항상 향상을 위한 여지가 있습니다. 개발자는 특정 요구 사항을 충족하기 위해 생성된 코드를 수정하여 최고의 품질을 보장할 수 있습니다.
GPT-Engineer 설정 프로세스는 쉽게 따라할 수 있는 가이드로 요약되었습니다. 다음은 단계별 분해입니다:
1. 환경 준비: 시작하기 전에 프로젝트 디렉토리가 준비되어 있는지 확인하십시오. 터미널을 열고 다음 명령을 실행합니다
- 웹사이트라는 이름의 새 디렉토리를 생성합니다:
mkdir website- 디렉토리로 이동:
cd website
2. 리포지토리 클론: git clone https://github.com/AntonOsika/gpt-engineer.git .
3. 탐색 및 종속성 설치: 클론한 후 디렉토리로 전환하여 cd gpt-engineer 必要한 모든 종속성을 설치합니다 make install
4. 가상 환경 활성화: 운영 체제에 따라 생성된 가상 환경을 활성화합니다.
- 对于 macOS/Linux:
source venv/bin/activate
- 对于 Windows, API 키 설정으로 인해 약간 다릅니다:
set OPENAI_API_KEY=[your api key]
5. 구성 – API 키 설정: OpenAI와 상호 작용하려면 API 키가 필요합니다. 아직 키가 없으면 OpenAI 플랫폼에 가입한 다음:
- 对于 macOS/Linux:
export OPENAI_API_KEY=[your api key]
- 对于 Windows (위에서 언급한 대로):
set OPENAI_API_KEY=[your api key]
6. 프로젝트 초기화 및 코드 생성: GPT-Engineer의 마법은 projects 폴더에 있는 main_prompt 파일에서 시작됩니다.
- 새 프로젝트를 시작하려면:
cp -r projects/example/ projects/website
여기서 ‘website’를 프로젝트 이름으로 바꿉니다.
- 선택한 텍스트 편집기를 사용하여
main_prompt파일을 편집하여 프로젝트 요구 사항을 작성합니다.

- 프롬프트에 만족하면 실행:
gpt-engineer projects/website
생성된 코드는 프로젝트 폴더 내의 workspace 디렉토리에 있습니다.
7. 생성 후: GPT-Engineer는 강력하지만 항상 완벽하지는 않습니다. 생성된 코드를 검사하고 필요한 경우 수동으로 변경하여 모든 것이 원활하게 실행되는지 확인합니다.
예제 실행
프롬프트:
“Python에서 사용자 데이터를 대화형 차트로 시각화하는 기본 Streamlit 앱을 개발하고 싶습니다. 앱은 사용자가 CSV 파일을 업로드하고 차트 유형(예: 막대, 파이, 선)을 선택하여 데이터를 동적으로 시각화할 수 있어야 합니다. Pandas를 사용하여 데이터를 조작하고 Plotly를 사용하여 시각화를 할 수 있습니다.”
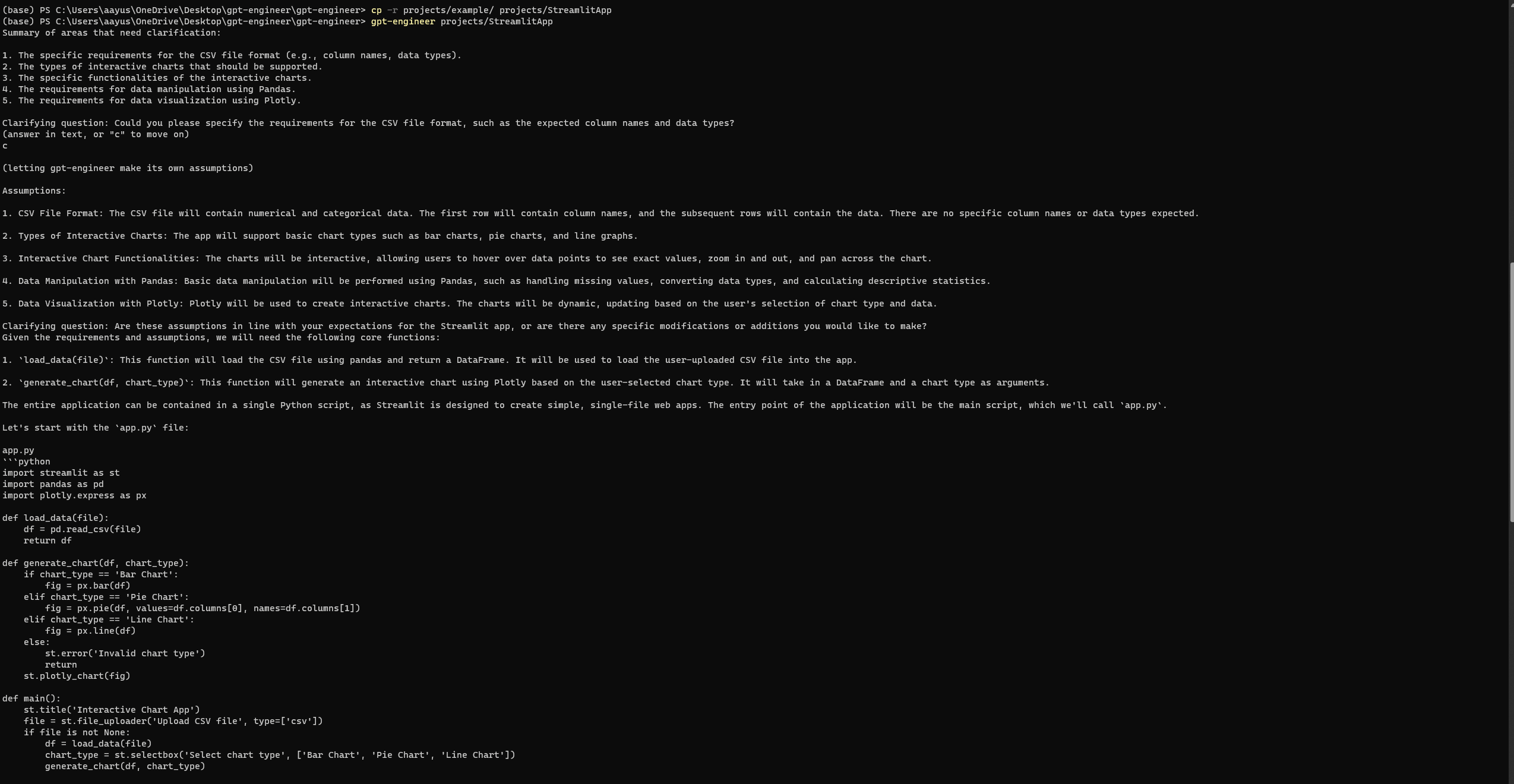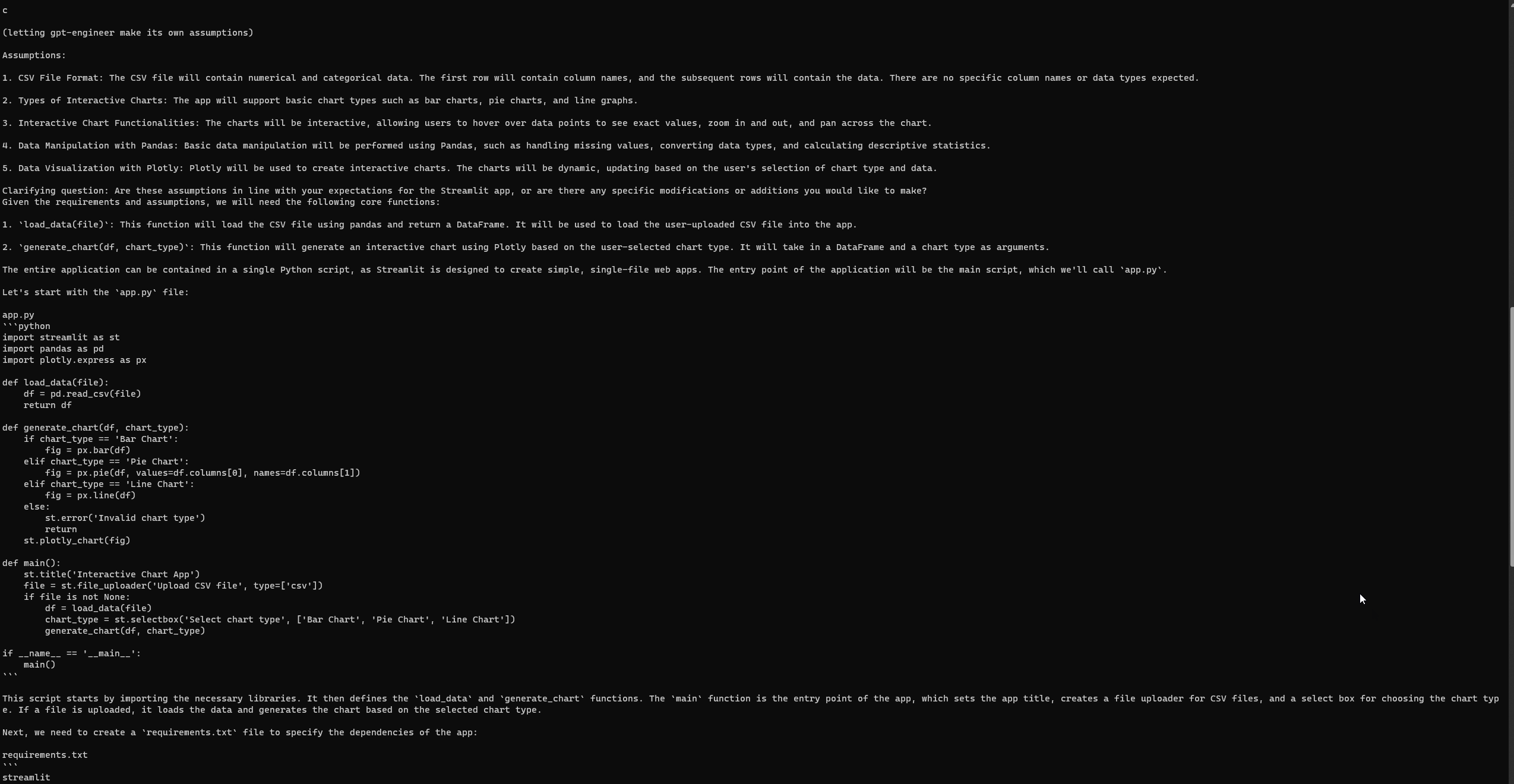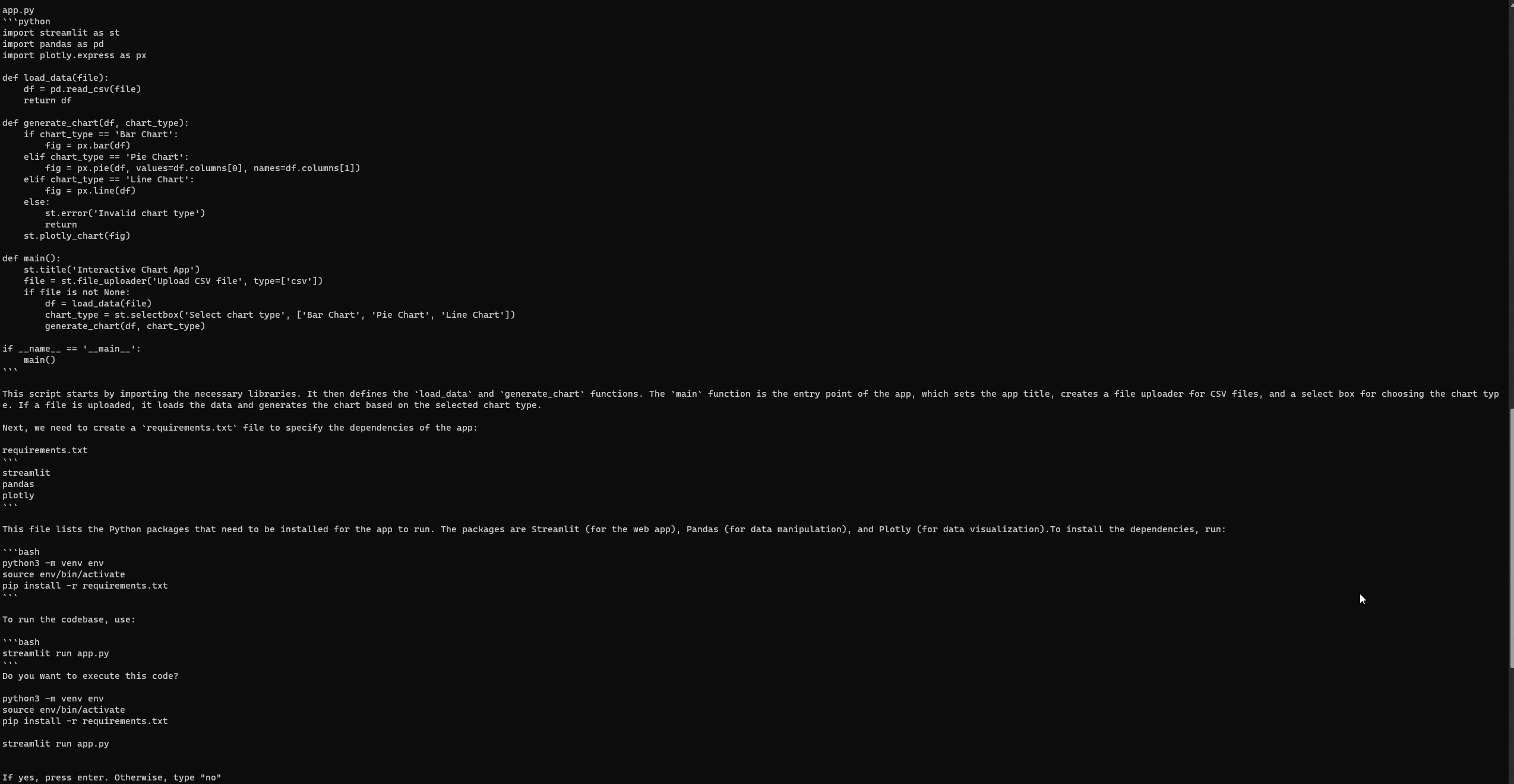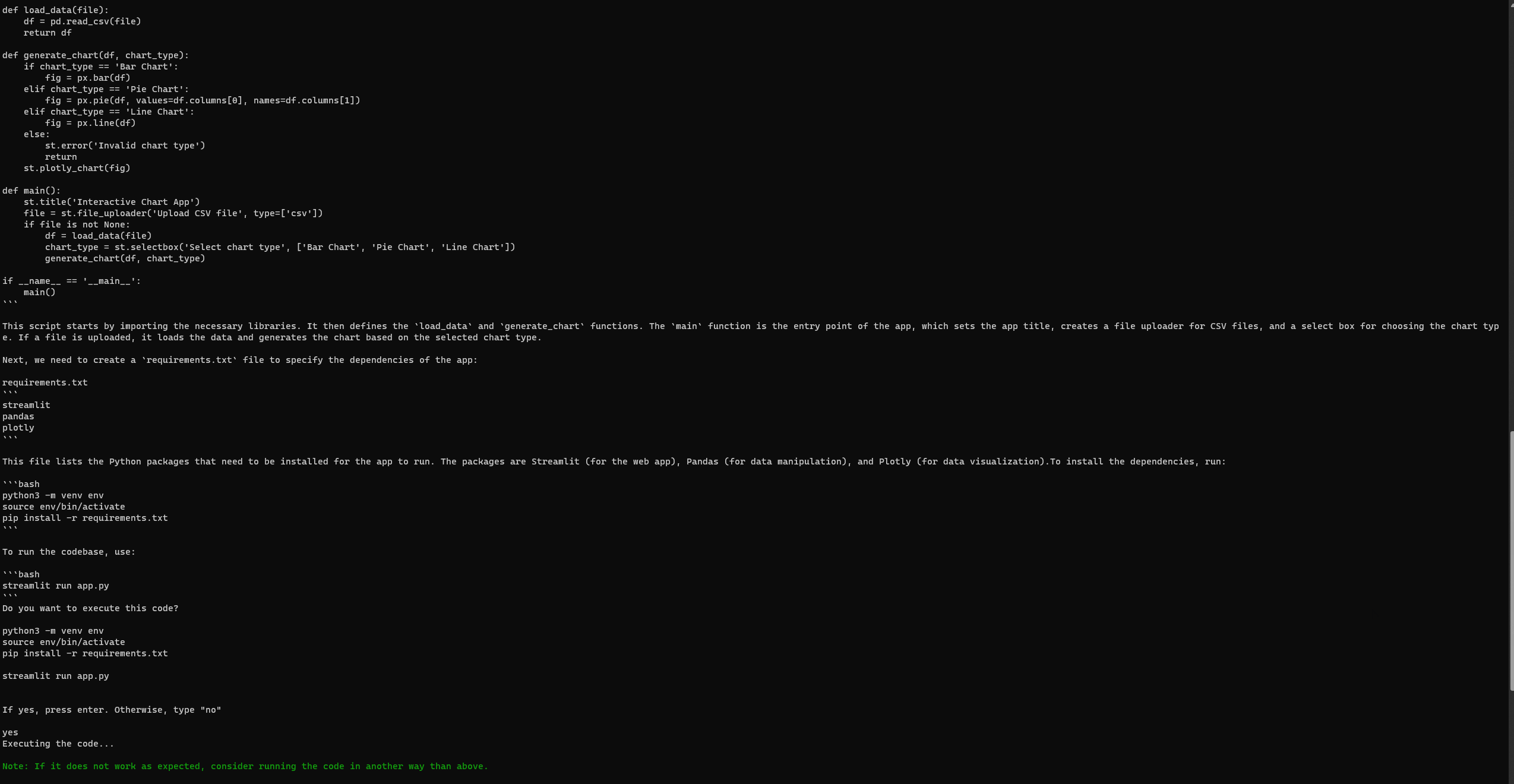
엔지니어링-GPT 설정 및 실행
Auto-GPT와 마찬가지로 GPT-Engineer도 완전한 설정 후에 때때로 오류를 발생시킬 수 있습니다. 그러나 세 번째 시도에서 성공적으로 다음 Streamlit 웹 페이지에 액세스했습니다. 오류를 확인하려면 공식 GPT-Engineer 리포지토리의 문제 페이지를 참조하십시오.

엔지니어링-GPT를 사용하여 생성된 Streamlit 앱
현재의 병목 현상
운영 비용
Auto-GPT에서 수행된 단일 작업에는 수많은 단계가 포함될 수 있습니다. 중요的是, 이러한 단계 각각이 개별적으로 청구될 수 있으며 비용이 증가할 수 있습니다. Auto-GPT는 반복적인 루프에 갇히고 약속된 결과를 전달하지 못할 수 있습니다. 이러한 발생은 신뢰성을 손상시키고 투자를 저하합니다.
Streamlit 앱을 생성하려는 경우를 상상해 보십시오. 앱의 이상적인 길이는 8K 토큰입니다. 그러나 생성 과정에서 모델은 콘텐츠를 완료하기 위해 여러 중간 단계에 돌입합니다. GPT-4를 8K 컨텍스트 길이로 사용하는 경우 입력에 대해 $0.03로 청구되며 출력에 대해 $0.06로 청구됩니다. 이제 모델이 예기치 않은 루프에 빠져 특정 부분을 여러 번 다시 실행한다고 가정해 보십시오. 프로세스는 더 길어지며 반복마다 비용이 추가됩니다.
이를 방지하려면:
사용 제한을 OpenAI 청구 및 제한에서 설정합니다:
- 하드 제한: 설정한 임계값을 초과하는 사용을 제한합니다.
- 소프트 제한: 임계값에 도달하면 알림 이메일을 보냅니다.
기능 제한
Auto-GPT의 기능은 소스 코드에 설명된 대로 특정 경계를 가지고 있습니다. 문제 해결 전략은 내부 함수와 GPT-4 API에서 제공하는 접근성에 의해 규정됩니다. 심층적인 논의와 가능한 해결책에 대해서는 Auto-GPT 논의를 참조하십시오.
AI의 노동 시장 영향
기술과 노동 시장의 역동성은 끊임없이 진화하고 있으며 이 연구 논문에 자세히 문서화되어 있습니다. 주요 결론은 기술의 발전이 숙련된 노동자에게는ประโยชน을 가져다주지만 루틴 작업에 종사하는 사람들에게는 위험을 초래한다는 것입니다. 실제로 기술의 발전은 특정 작업을 대체할 수 있지만同時적으로 다양한 노동 집약적인 작업을 위한 길을 열어줍니다.

미국 노동자의 약 80%는 언어 학습 모델(LMs)이 일일 작업의 약 10%에 영향을 미칠 수 있다고 추정합니다. 이 통계는 AI와 인간 역할의 융합을 강조합니다.
AI의 노동력에서의 이중 역할:
- 긍정적인 측면: AI는 고객 서비스에서 재무 상담까지 다양한 작업을 자동화할 수 있으며, 전용 팀을 위한 자금이 부족한 소규모 기업에게 휴식을 제공할 수 있습니다.
- 우려: 자동화의 이점은 특히 고객 지원과 같은 인간의 개입이 중요한 분야에서 작업 손실에 대한 우려를 불러일으킵니다. 또한 AI가 기밀 데이터에 액세스하는 것과 관련된 윤리적인 미로가 있습니다. 이는 투명성, 책임성 및 AI의 윤리적인 사용을 보장하는 강력한 인프라를 필요로 합니다.
결론
명확하게, ChatGPT, Auto-GPT 및 GPT-Engineer와 같은 도구는 기술과 사용자 간의 상호 작용을 재정의하는 최전선에 있습니다. 오픈 소스 운동의 뿌리에서 비롯된 이러한 AI 에이전트는 기계 자율성의 가능성을 구현하며, 스케줄링에서 소프트웨어 개발까지 작업을 간소화합니다.
미래로 나아가면서 AI가 일상 루틴에 더 깊이 통합됨에 따라 AI의 능력과 인간의 역할을 균형 있게 유지하는 것이 중요합니다. 더 넓은 관점에서 볼 때, AI-노동 시장 역동성은 성장의 기회와 도전의 이중 이미지를描きます. 기술의 윤리와 투명성을 의식적으로 통합해야 합니다.












