인공지능
AudioSep : 설명한 모든 것을 분리합니다
LASS 또는 언어 쿼리 오디오 소스 분리是一种新的 CASA 또는 계산적 청각 장면 분석 패러다임으로, 자연어 쿼리를 사용하여 오디오 믹스에서 대상 사운드를 분리하는 것을 목표로 합니다. 이러한 쿼리는 디지털 오디오 작업 및 애플리케이션을 위한 자연스럽고 확장 가능한 인터페이스를 제공합니다. 최근 몇 년 동안 LASS 프레임워크는 특정 오디오 소스(예: 음악 악기)에서 원하는 성능을 달성하는 데 상당히 발전했지만, 오픈 도메인에서 대상 오디오를 분리하는 데는 여전히 한계가 있습니다.
AudioSep는 이러한 LASS 프레임워크의 현재 한계를 해결하기 위한 기초 모델입니다. AudioSep는 자연어 쿼리를 사용하여 대상 오디오를 분리하는 것을 목표로 합니다. AudioSep 프레임워크의 개발자는 대규모 멀티모달 데이터셋에서 모델을 광범위하게 훈련시켰으며, 음악 악기 분리, 오디오 이벤트 분리, 스피치 강화 등 다양한 오디오 작업에서 프레임워크의 성능을 평가했습니다. AudioSep의 초기 성능은 벤치마크를 충족하며, 인상적인 제로샷 학습 능력과 강력한 오디오 분리 성능을 보여줍니다.
이 기사에서는 AudioSep 프레임워크의 작동 방식에 대해 더 깊이 있게 살펴보겠습니다. 모델의 아키텍처, 훈련 및 평가에 사용된 데이터셋, AudioSep 모델의 작동에涉及된 기본 개념 등을 평가하겠습니다. CASA 프레임워크에 대한 기본적인 소개부터 시작하겠습니다.
CASA, USS, QSS, LASS 프레임워크 : AudioSep의 기초
CASA 또는 계산적 청각 장면 분석 프레임워크는 개발자가 인간의 청각 시스템과 유사한 방식으로 복잡한 사운드 환경을 인식할 수 있는 기계 청취 시스템을 설계하기 위한 프레임워크입니다. 사운드 분리, 특히 대상 사운드 분리는 CASA 프레임워크 내의 기본 연구 분야이며, “칵테일 파티 문제” 또는 개별 오디오 소스 녹음 또는 파일에서 실제 오디오 녹음을 분리하는 것을 목표로 합니다. 사운드 분리의 중요성은 주로 음악 소스 분리, 오디오 소스 분리, 스피치 강화, 대상 사운드 식별 등 다양한 응용 분야에 기인합니다.
과거에 수행된 대부분의 사운드 분리 작업은 음악 분리 또는 스피치 분리와 같은 하나 이상의 오디오 소스를 분리하는 데 중점을 두었습니다. USS 또는 유니버설 사운드 분리라는 새로운 모델은 실제 오디오 녹음에서 임의의 사운드를 분리하는 것을 목표로 합니다. 그러나 오디오 믹스에서 모든 사운드 소스를 분리하는 것은 현실 세계의 응용 프로그램에서 실시간으로 작동하는 데 도전적이고 제한적인 작업입니다. 이는 세계에 존재하는 다양한 사운드 소스의广泛性으로 인해 USS 방법이 실제 응용 분야에서 실현 가능하지 않기 때문입니다.
USS 방법의 대안은 QSS 또는 쿼리 기반 사운드 분리 방법입니다. QSS는 특정 쿼리 세트를 기반으로 오디오 믹스에서 개별 또는 대상 사운드 소스를 분리하는 것을 목표로 합니다. 이를 통해 QSS 프레임워크는 개발자와 사용자가 요구 사항에 따라 오디오 믹스에서 원하는 오디오 소스를 추출할 수 있도록 허용합니다. 이는 멀티미디어 콘텐츠 편집 또는 오디오 편집과 같은 디지털 실제 세계 응용 분야에서보다 실용적인 해결책을 제공합니다.
さらに, 개발자는 최근에 QSS 프레임워크의 확장인 LASS 프레임워크 또는 언어 쿼리 오디오 소스 분리 프레임워크를 제안했습니다. LASS는 대상 오디오 소스를 자연어 설명을 사용하여 오디오 믹스에서 임의의 사운드를 분리하는 것을 목표로 합니다. LASS 프레임워크는 사용자가 자연어 지시 세트를 사용하여 대상 오디오 소스를 추출할 수 있도록 허용하므로, 디지털 오디오 응용 분야에서 강력한 도구가 될 수 있습니다. 전통적인 오디오 쿼리 또는 비전 쿼리 방법과 비교하여, 오디오 분리에 자연어 지시를 사용하는 것은 유연성과 쿼리 정보의 획득을 더 쉽고 편리하게 만듭니다. 또한, 레이블 쿼리 기반 오디오 분리 프레임워크와 비교하여, LASS 프레임워크는 입력 쿼리의 수를 제한하지 않으며, 오픈 도메인으로 확장될 수 있습니다.
원래, LASS 프레임워크는 지도 학습에 의존하며, 모델은 레이블이 지정된 오디오-텍스트 페어 데이터 세트에서 훈련됩니다. 그러나 이러한 접근 방식의 주요 문제는 레이블이 지정된 오디오-텍스트 데이터의 제한된 가용성입니다. LASS 프레임워크가 레이블이 지정된 오디오-텍스트 레이블 데이터에 대한 의존도를 줄이기 위해, 모델은 멀티모달 감시 학습 접근 방식을 사용하여 훈련됩니다. 멀티모달 감시 접근 방식의 주요 목적은 쿼리 인코더로 CLIP 또는 대조 언어 이미지 사전 훈련 모델과 같은 멀티모달 대조적 사전 훈련 모델을 사용하는 것입니다. CLIP 프레임워크는 텍스트 임베딩을 다른 모달리티와 같은 오디오 또는 비전과 일치시킬 수 있으므로, 개발자는 데이터가 풍부한 모달리티를 사용하여 LASS 모델을 훈련시키고, 제로샷 설정에서 텍스트 데이터와 간섭할 수 있습니다. 현재 LASS 프레임워크는 작은 규모의 데이터셋을 사용하여 훈련되며, 수백 개의 잠재적 도메인에 대한 LASS 프레임워크의 응용 분야는 아직 탐索되지 않았습니다.
LASS 프레임워크의 현재 한계를 해결하기 위해, 개발자는 AudioSep를 도입했습니다. AudioSep는 자연어 설명을 사용하여 오디오 믹스에서 사운드를 분리하는 것을 목표로 하는 기초 모델입니다. AudioSep의 현재 초점은 기존의 대규모 멀티모달 데이터셋을 활용하여 오픈 도메인 응용 분야에서 LASS 모델의 일반화를 가능하게 하는 사전 훈련된 사운드 분리 모델을 개발하는 것입니다. 요약하면, AudioSep 모델은 “자연어 쿼리 또는 설명을 사용하여 오픈 도메인에서 유니버설 사운드 분리를 위한 기초 모델로, 대규모 오디오 및 멀티모달 데이터셋에서 훈련됩니다”라고 정의할 수 있습니다.
AudioSep : 주요 구성 요소 및 아키텍처
AudioSep 프레임워크의 아키텍처는 두 가지 주요 구성 요소로 구성됩니다. 텍스트 인코더와 분리 모델입니다.
텍스트 인코더
AudioSep 프레임워크는 자연어 쿼리에서 텍스트 임베딩을 추출하기 위해 CLIP 또는 대조 언어 이미지 사전 훈련 모델 또는 CLAP 또는 대조 언어 오디오 사전 훈련 모델의 텍스트 인코더를 사용합니다. 입력 텍스트 쿼리는 “N” 토큰의 시퀀스이며, 이를 텍스트 인코더가 처리하여 입력 언어 쿼리に対する 텍스트 임베딩을 추출합니다. 텍스트 인코더는 트랜스포머 블록의 스택을 사용하여 입력 텍스트 토큰을 인코딩하며, 출력 표현은 트랜스포머 계층을 통과한 후 집계되어, 고정된 길이의 D차원 벡터 표현이 생성됩니다. 여기서 D는 CLAP 또는 CLIP 모델의 차원을 나타냅니다. 텍스트 인코더는 훈련 기간 동안 고정됩니다.
CLIP 모델은 대조 학습을 사용하여 대규모 이미지-텍스트 페어 데이터셋에서 사전 훈련되며, 이는 텍스트 인코더가 텍스트 설명을 공유하는 시맨틱 공간에 매핑하는 것을 학습한다는 것을 의미합니다. AudioSep가 CLIP의 텍스트 인코더를 사용함으로써 얻는 이점은 시각적 임베딩을 대안으로 사용하여 비지도 오디오-시각 데이터에서 LASS 모델을 훈련할 수 있다는 것입니다. 이는 레이블이 지정된 오디오-텍스트 데이터가 필요하지 않게 됩니다.
CLAP 모델은 CLIP 모델과 유사하게 작동하며, 대조 학습 목표를 사용하여 텍스트 및 오디오 인코더를 사용하여 오디오와 언어를 연결합니다. 이를 통해 텍스트와 오디오 설명을 오디오-텍스트 잠재 공간에 결합합니다.
분리 모델
AudioSep 프레임워크는 분리 백본으로 주파수 도메인 ResUNet 모델을 사용합니다. 모델은 먼저 Hann 창의 크기가 1024인 STFT 또는 짧은 시간 푸리에 변환을 적용하여 복소수 스펙트로그램, 크기 스펙트로그램 및 X의 위상을 추출합니다. 모델은 동일한 설정을 따르고, 크기 스펙트로그램을 처리하기 위한 인코더-디코더 네트워크를 구성합니다.
ResUNet 인코더-디코더 네트워크는 6개의 인코더 블록, 6개의 디코더 블록 및 4개의 병목 블록으로 구성됩니다. 각 인코더 블록은 4개의 잔차 합성곱 블록을 사용하여 스펙트로그램을 다운샘플링하여 병목 특징을 생성합니다. 디코더 블록은 4개의 잔차 전이 합성곱 블록을 사용하여 특징을 업샘플링하여 분리 구성 요소를 얻습니다. 각 인코더 블록과 해당 디코더 블록은 동일한 업샘플링 또는 다운샘플링률에서 작동하는 스킵 연결을 설정합니다. 잔차 블록은 2개의 누출한 레루 활성화 계층, 2개의 배치 정규화 계층 및 2개의 CNN 계층으로 구성되며, 또한 각 잔차 블록의 입력과 출력을 연결하는 추가 잔차 단축 경로를 도입합니다. ResUNet 모델은 복소수 스펙트로그램 X를 입력으로 받아, 크기 마스크 M을 출력으로 생성하며, 위상 잔차는 텍스트 임베딩에 조건화되어 스펙트로그램의 크기 및 각도를 조절합니다. 분리된 복소수 스펙트로그램은 예측된 크기 마스크와 위상 잔차를 STFT(짧은 시간 푸리에 변환)와 곱하여 추출할 수 있습니다.

AudioSep 프레임워크는 분리 모델과 텍스트 인코더를 연결하기 위해 ResUNet의 합성곱 블록을 배치한 후 FiLm 또는 피처 와이즈 선형 변조 계층을 사용합니다.
훈련 및 손실
AudioSep 모델의 훈련期间, 개발자는 라우드니스 오그멘테이션 방법을 사용하며, L1 손실 함수를 사용하여 AudioSep 프레임워크를 종단 간으로 훈련합니다.
데이터셋 및 벤치마크
이전 섹션에서 언급했듯이, AudioSep는 LASS 모델의 현재 제한 사항을 해결하기 위한 기초 모델입니다. AudioSep 모델은 멀티모달 학습 능력을 갖추기 위해 다양한 데이터셋에서 훈련되며, AudioSep 프레임워크를 훈련하기 위해 사용된 데이터셋 및 벤치마크에 대한 자세한 설명은 다음과 같습니다.
AudioSet
AudioSet은 약 200만 개의 10초 오디오 클립으로 구성된 대규모 약하게 레이블이 지정된 오디오 데이터셋입니다. 각 오디오 클립은 사운드 클래스의 존재 또는 부재에 따라 분류되며, 사운드 이벤트의 특정 타이밍 정보는 제공되지 않습니다. AudioSet 데이터셋에는 자연 사운드, 인간 사운드, 차량 사운드 등 약 500개의 서로 다른 오디오 클래스가 있습니다.
VGGSound
VGGSound 데이터셋은 AudioSet과 마찬가지로 YouTube에서 직접 소싱된 대규모 시각-오디오 데이터셋으로, 약 20만 개의 10초 길이의 비디오 클립으로 구성되어 있습니다. VGGSound 데이터셋에는 인간 사운드, 자연 사운드, 새 소리 등 약 300개의 사운드 클래스가 있습니다. VGGSound 데이터셋의 사용은 대상 사운드의 책임 있는 객체가 해당 시각 클립에서 설명될 수 있음을 보장합니다.
AudioCaps
AudioCaps는 공개적으로 사용 가능한 가장 큰 오디오 캡션 데이터셋으로, AudioSet 데이터셋에서 추출된 약 5만 개의 10초 길이의 오디오 클립으로 구성되어 있습니다. AudioCaps 데이터는 훈련 데이터, 테스트 데이터 및 검증 데이터로 나뉘며, 오디오 클립은 Amazon Mechanical Turk 플랫폼을 사용하여 자연어 설명으로 인간이 주석을 달았습니다. 훈련 데이터셋의 각 오디오 클립에는 하나의 캡션이 있으며, 테스트 및 검증 데이터셋의 경우 각 클립에는 5개의 근거 참조 캡션이 있습니다.
ClothoV2
ClothoV2는 FreeSound 플랫폼에서 추출된 클립으로 구성된 오디오 캡션 데이터셋으로, AudioCaps와 마찬가지로 Amazon Mechanical Turk 플랫폼을 사용하여 오디오 클립이 자연어 설명으로 인간이 주석을 달았습니다.
WavCaps
WavCaps는 AudioSet과 마찬가지로 약 40만 개의 오디오 클립으로 구성된 대규모 약하게 레이블이 지정된 오디오 데이터셋으로, 총 런타임은 약 7568시간의 훈련 데이터에 해당합니다. WavCaps 데이터셋의 오디오 클립은 다양한 오디오 소스에서 추출되었으며, BBC Sound Effects, AudioSet, FreeSound, SoundBible 등이 포함됩니다.

훈련 세부 정보
훈련 기간 동안, AudioSep 모델은 훈련 데이터셋에서 두 개의 오디오 세그먼트를 임의로 샘플링하여 두 개의 서로 다른 오디오 클립에서 믹스하여 길이가 약 5초인 훈련 믹스를 생성합니다. 모델은 Hann 창의 크기가 1024인 STFT 또는 짧은 시간 푸리에 변환을 적용하여 웨이브폼 신호에서 복소수 스펙트로그램을 추출합니다.
모델은 텍스트 인코더로 CLIP/CLAP 모델의 텍스트 인코더를 사용하여 텍스트 임베딩을 추출하며, 텍스트 감시가 AudioSep의 기본 구성입니다. 분리 모델로 ResUNet 계층을 사용하며, 이는 30개의 계층, 6개의 인코더 블록 및 6개의 디코더 블록으로 구성됩니다. 각 인코더 블록에는 3×3 커널 크기를 가진 2개의 합성곱 계층이 있으며, 인코더 블록의 출력 피처 맵 수는 32, 64, 128, 256, 512 및 1024입니다. 디코더 블록은 인코더 블록과 대칭을 이루며, 개발자는 Adam 옵티마이저를 사용하여 AudioSep 모델을 배치 크기 96으로 훈련합니다.
평가 결과
학습된 데이터셋에서
다음 그림은 AudioSep 프레임워크의 성능을 학습된 데이터셋에서 비교합니다. 그림은 AudioSep 프레임워크의 벤치마크 평가 결과를 나타내며, 이는 스피치 강화 모델, LASS 및 CLIP와 같은 기준 시스템과 비교하여 나타냅니다. CLIP 텍스트 인코더를 사용하는 AudioSep 모델은 AudioSep-CLIP으로 나타나며, CLAP 텍스트 인코더를 사용하는 AudioSep 모델은 AudioSep-CLAP으로 나타납니다.

그림에서 볼 수 있듯이, AudioSep 프레임워크는 오디오 캡션 또는 텍스트 레이블을 입력 쿼리로서 사용할 때 잘 작동하며, 이는 이전의 벤치마크 LASS 및 오디오 쿼리 기반 사운드 분리 모델과 비교하여 AudioSep 프레임워크의 우수한 성능을 나타냅니다.
미학습된 데이터셋에서
제로샷 설정에서 AudioSep의 성능을 평가하기 위해, 개발자는 미학습된 데이터셋에서 성능을 계속 평가했습니다. AudioSep 프레임워크는 제로샷 설정에서 인상적인 분리 성능을 보여주며, 결과는 다음 그림에 나타나 있습니다.

さらに, 다음 그림은 AudioSep 모델을 Voicebank-Demand 스피치 강화와 비교한 결과를 나타냅니다.

AudioSep 프레임워크의 평가 결과는 제로샷 설정에서 미학습된 데이터셋에서 강력한 желаем한 성능을 나타내며, 이는 새로운 데이터 분포에서 사운드 작업을 수행하는 데 도움이 됩니다.
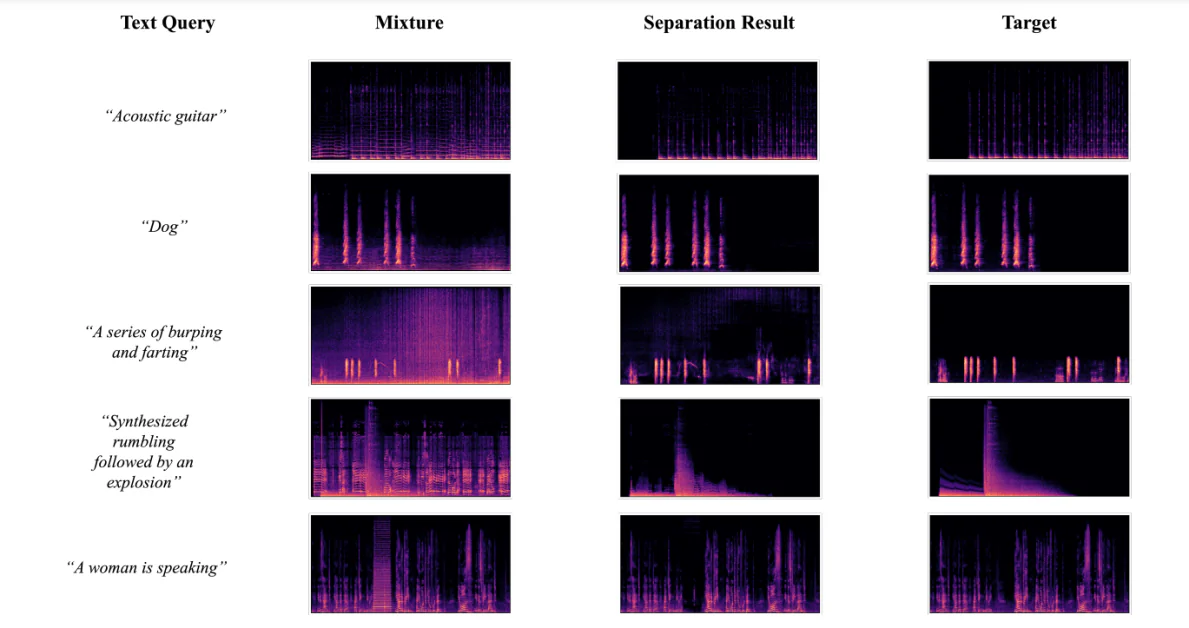
분리 결과의 시각화
다음 그림은 AudioSep-CLAP 프레임워크를 사용하여 다양한 오디오 또는 사운드에 대한 텍스트 쿼리를 사용하여 분리된 오디오 소스 및 오디오 믹스의 스펙트로그램을 시각화한 결과를 나타냅니다. 결과는 분리된 소스 패턴이 근거 참조 소스와 유사하다는 것을 보여주며, 이는 실험 동안 얻은 객관적인 결과를 추가로 지원합니다.
텍스트 쿼리의 비교
개발자는 AudioCaps Mini에서 AudioSep-CLAP 및 AudioSep-CLIP의 성능을 평가하며, AudioSet 이벤트 레이블, AudioCaps 캡션 및 재주석된 자연어 설명을 사용하여 다양한 쿼리의 영향을 조사합니다. 다음 그림은 AudioCaps Mini의 예시를 나타냅니다.

결론
AudioSep는 자연어 설명을 사용하여 오디오 분리를 위한 오픈 도메인 유니버설 사운드 분리 프레임워크입니다. 평가 결과, AudioSep 프레임워크는 제로샷 및 비지도 학습을 원활하게 수행할 수 있으며, 이는 오디오 캡션 또는 텍스트 레이블을 쿼리로서 사용할 때 잘 작동합니다. 결과 및 평가 성능은 AudioSep 프레임워크의 강력한 성능을 나타내며, 이는 현재 상태의 사운드 분리 프레임워크인 LASS를 능가하며, 현재의 사운드 분리 프레임워크의 제한 사항을 해결할 수 있을 것입니다.












