사상 리더
대형 언어 모델에서 구식 事実를 신선하게 유지하는 3 가지 방법
대형 언어 모델(Large Language Models, LLM)인 GPT3, ChatGPT, BARD는 현재 모든 사람들의 관심을 끌고 있습니다. 모두가 이러한 도구가 사회에 좋거나 나쁘다는 의견과 미래의 인공지능에 대한 의미에 대해 의견을 가지고 있습니다. Google의 새로운 모델 BARD가 복잡한 질문을 약간 잘못 대답한 것에 대해 많은 비판을 받았습니다. “제임스 웹 우주 망원경에서 9살 아이에게 말할 수 있는 새로운 발견은 무엇입니까?”라는 질문에 대해 채팅봇은 세 가지 답변을 제공했으며, 그 중 두 가지가 올바르고 하나가 잘못되었습니다. 잘못된 것은 JWST가 최초의 “외계 행성” 사진을 찍었다는 것이었습니다. 이는 잘못된 것입니다. 따라서 모델에는 잘못된 事實가 저장되어 있었습니다. 대형 언어 모델이 효과적으로 작동하려면 이러한 事實를 업데이트하거나 새로운 지식으로 보완하는 방법이 필요합니다.
대형 언어 모델 내부에서 事實가 저장되는 방식을 살펴보겠습니다. 대형 언어 모델은 전통적인 의미에서 데이터베이스나 파일과 같이 정보와 事實를 저장하지 않습니다. 대신에, 광범위한 텍스트 데이터에 대해 훈련을 받았으며, 이러한 데이터에서 패턴과 관계를 학습했습니다. 이는 인간과 같은 방식으로 질문에 답변할 수 있게 하지만, 학습된 정보에 대한 특정한 저장 위치가 없습니다. 질문에 답변할 때, 모델은 입력된 내용에 따라 훈련을 통해 답변을 생성합니다. 언어 모델이 가지고 있는 정보와 지식은 모델의 메모리에 명시적으로 저장된 결과가 아니라, 훈련 데이터에서 학습한 패턴의 결과입니다. 대부분의 현대적인 LLM이 기반으로 하는 Transformer 아키텍처에는 질문에 답변하기 위해 사용되는 내부 인코딩된 事實가 있습니다.

따라서, LLM의 내부 메모리 내에 있는 事實가 잘못되거나 구식이라면, 새로운 정보를 프롬프트를 통해 제공해야 합니다. 프롬프트는 LLM에 질의와 함께 전송되는 텍스트이며, 지원되는 증거가 될 수 있는 새로운 事實나 수정된 事實를 포함할 수 있습니다. 이러한 방법에는 3 가지 접근 방식이 있습니다.
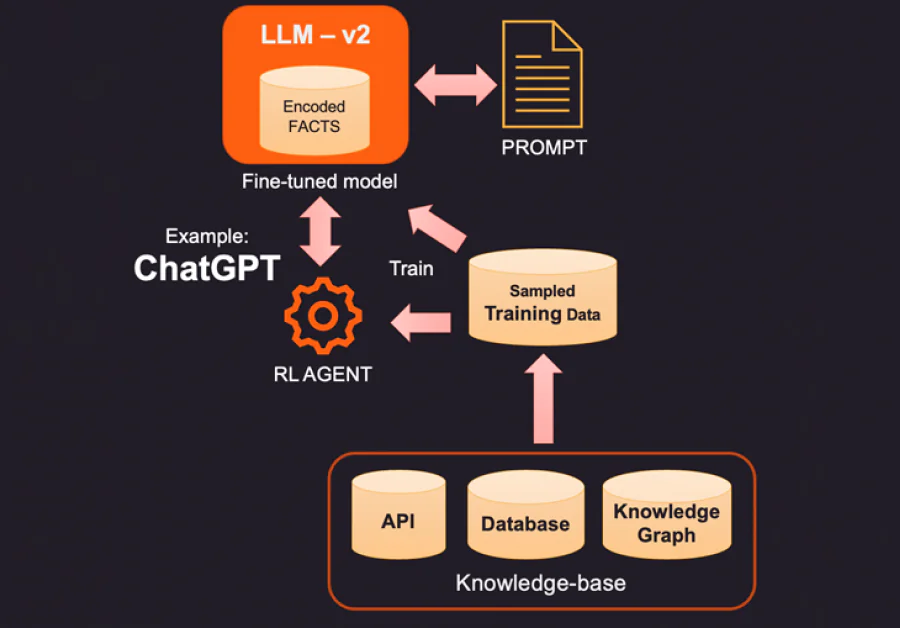
1. LLM의 인코딩된 事實를 수정하는 한 가지 방법은 외부 지식 베이스를 사용하여 관련된 새로운 事實를 제공하는 것입니다. 이 지식 베이스는 관련 정보를 얻기 위한 API 호출이나 SQL, No-SQL, 또는 벡터 데이터베이스의 조회가 될 수 있습니다. 더 고급적인 지식은 데이터 엔티티와 그들 사이의 관계를 저장하는 지식 그래프에서 추출할 수 있습니다. 사용자가 질의하는 정보에 따라 관련된 컨텍스트 정보를 검색하여 LLM에 추가적인 事實로 제공할 수 있습니다. 이러한 事實는 학습 프로세스를 개선하기 위해 훈련 예제와 같은 형식으로 포맷팅할 수 있습니다. 예를 들어, 모델이 답변을 제공하는 방법을 학습할 수 있도록 질문과 답변의 쌍을 전달할 수 있습니다.

2. LLM을 보완하는 더 혁신적인 방법(그리고 더 비싼 방법)은 실제로 훈련 데이터를 사용하는 微調整입니다. 따라서 지식 베이스에서 특정 事實를 조회하는 대신, 지식 베이스를 샘플링하여 훈련 데이터셋을 구축합니다. 감독 학습 기법인 微調整를 사용하여 이 추가적인 지식을 훈련한 새로운 LLM 버전을 만들 수 있습니다. 이 프로세스는 일반적으로 비용이 많이 들며, OpenAI에서 微調整된 모델을 구축하고 유지하는 데 몇 천 달러가 소요될 수 있습니다.当然, 비용은 시간이 지나면서 더 저렴해질 것입니다.
3. 또 다른 방법은 강화 학습(RL)과 같은 방법을 사용하여 인간의 피드백과 함께 에이전트를 훈련시키고, 질문에 답변하는 방법에 대한 정책을 학습하는 것입니다. 이 방법은 특정 작업에 대해熟練한 작은 모델을 구축하는 데 매우 효과적으로证明되었습니다. 예를 들어, OpenAI에서 출시한 유명한 ChatGPT는 감독 학습과 인간의 피드백을 사용한 RL의 조합으로 훈련되었습니다.

요약하면, 이 분야는 매우 빠르게 발전하고 있으며, 모든 주요 회사들이 इसम에 참여하여 차별화를 보여주고자 합니다. 우리는 곧 소매, 의료, 은행 등 대부분의 분야에서 인간과 같은 방식으로 응답할 수 있는 LLM 도구를 보게 될 것입니다. 이러한 LLM 기반 도구는 기업 데이터와 통합되어 데이터에 대한 접근을 간소화하고, 올바른 데이터를 올바른 사람에게 올바른 시간에 제공할 수 있습니다.












