
인공 지능
영향력 있는 데이터 세트의 카르텔이 기계 학습 연구를 지배하고 있음, 새로운 연구 제안
캘리포니아 대학과 Google Research의 새로운 논문에 따르면 주로 영향력 있는 서구 기관과 정부 기관에서 수집한 소수의 '벤치마크' 기계 학습 데이터 세트가 AI 연구 부문을 점점 더 지배하고 있는 것으로 나타났습니다.
연구자들은 이러한 경향이 다음과 같은 매우 인기 있는 오픈 소스 데이터 세트로 '기본값'이 된다고 결론지었습니다. IMAGEnet, 여러 가지 실용적이고 윤리적이며 심지어 정치적인 우려의 원인을 제시합니다.
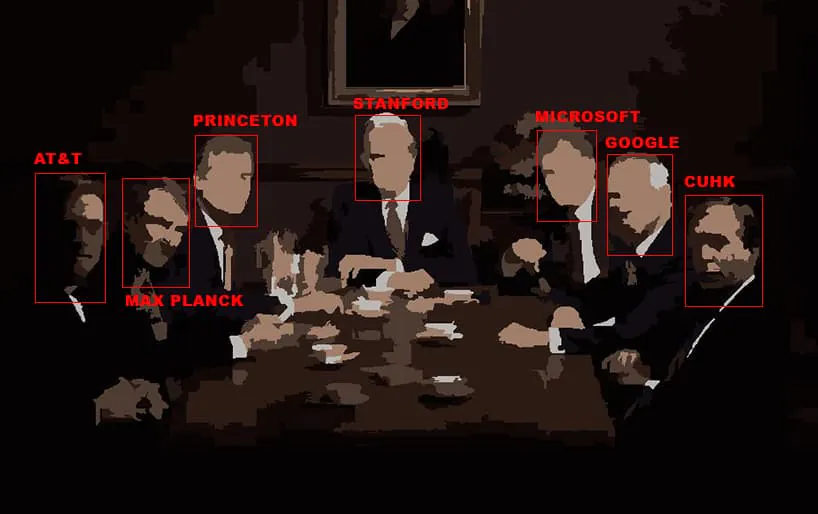
결과 중 – Facebook이 주도하는 커뮤니티 프로젝트의 핵심 데이터를 기반으로 함 코드와 논문 (PWC) – 저자는 다음과 같이 주장합니다. '널리 사용되는 데이터 세트는 소수의 엘리트 기관에서만 도입됩니다.', 그리고 이러한 '통합'이 최근 몇 년 동안 80%로 증가했습니다.
'[우리는] 전 세계적으로 데이터 세트 사용의 불평등이 증가하고 있으며, 50개의 샘플에서 모든 데이터 세트 사용의 43,140% 이상이 XNUMX개의 엘리트, 주로 서양 기관에서 도입한 데이터 세트에 해당한다는 것을 발견했습니다.'

지난 50년 동안 작업과 관련되지 않은 데이터 세트 사용 지도. 포함 기준은 기관 또는 회사가 알려진 사용량의 XNUMX% 이상을 차지하는 경우입니다. 오른쪽에 표시된 것은 지니 계수 기관 및 데이터 세트 모두에 대해 시간이 지남에 따라 데이터 세트 집중. 출처 : https://arxiv.org/pdf/2112.01716.pdf
주요 기관으로는 스탠포드 대학, 마이크로소프트, 프린스턴, 페이스북, 구글, 막스 플랑크 연구소, AT&T 등이 있습니다. 상위 XNUMX개 데이터 세트 소스 중 XNUMX개는 기업 기관입니다.
이 백서는 또한 이러한 엘리트 데이터 세트의 사용 증가를 다음과 같이 특징지었습니다. '과학의 불평등을 위한 수단'. 이것은 커뮤니티 승인을 추구하는 연구팀이 그러한 입지가 없고 동료들이 새로운 것에 적응해야 하는 원본 데이터 세트를 생성하는 것보다 일관된 데이터 세트에 대해 최첨단(SOTA) 결과를 달성하려는 동기가 더 많기 때문입니다. 표준 인덱스 대신 메트릭.
어쨌든 이 논문에서 인정한 것처럼 자체 데이터 세트를 만드는 것은 자원이 부족한 기관과 팀이 엄청나게 비용이 많이 드는 일입니다.
' 예비면 SOTA 벤치마킹에 의해 부여된 과학적 타당성은 일반적으로 연구자가 널리 인식된 데이터 세트에서 경쟁할 수 있음을 보여줌으로써 얻은 사회적 신뢰도와 일반적으로 혼동됩니다.
'우리는 이러한 역학 관계가 "매튜 효과"(즉, "부자는 더 부자가 되고 가난한 사람은 더 가난해짐")를 생성하여 성공적인 벤치마크와 이를 도입한 엘리트 기관이 해당 분야에서 큰 위상을 얻게 되었다고 가정합니다.
XNUMXD덴탈의 종이 제목이 감소, 재사용 및 재활용: 기계 학습 연구에서 데이터 세트의 수명, UCLA의 Bernard Koch와 Jacob G. Foster, Google Research의 Emily Denton과 Alex Hanna가 제공합니다.
이 작업은 통합을 향한 증가 추세에 따라 많은 문제를 제기하며 이를 문서화하고 충족했습니다. 일반적인 승인 오픈 리뷰에서. NeurIPS 2021의 한 리뷰어는 이 작업이 '기계 학습 연구에 관련된 모든 사람과 매우 관련이 있습니다.' 대학 과정에서 할당된 독서로 포함되는 것을 예견했습니다.
필요에서 부패로
저자들은 AI에 대한 관심과 투자가 두 번째로 무너지는 원인이 된 객관적인 평가 도구의 부족에 대한 해결책으로 현재의 'bench-the-benchmark' 문화가 등장했다고 지적합니다. XNUMX여 년 전, '전문가 시스템'의 새로운 연구에 대한 비즈니스 열정이 쇠퇴한 후:
'벤치마크는 일반적으로 데이터 세트 및 관련된 정량적 평가 지표를 통해 특정 작업을 공식화합니다. 이 관행은 원래 1980년대 "AI Winter" 이후 보조금으로 받은 가치를 보다 정확하게 평가하려는 정부 자금 제공자들에 의해 [머신 러닝 연구]에 도입되었습니다.'
이 논문은 이러한 비공식적 표준화 문화의 초기 이점(참여 장벽 감소, 일관된 메트릭 및 보다 민첩한 개발 기회)이 데이터 본문이 데이터를 효과적으로 정의할 수 있을 만큼 충분히 강력해질 때 자연적으로 발생하는 단점에 의해 압도되기 시작했다고 주장합니다. '이용 약관' 및 영향 범위.
저자는 이 문제에 대한 최근의 업계 및 학계의 생각에 따라 연구 커뮤니티가 다음과 같이 제안합니다. 더 이상 새로운 문제를 제기하지 않습니다 기존 벤치마크 데이터 세트를 통해 이러한 문제를 해결할 수 없는 경우.
그들은 또한 이 소수의 '골드' 데이터 세트에 대한 맹목적인 준수가 연구자들이 다음과 같은 결과를 달성하도록 장려한다는 점에 주목합니다. 과적합 (즉, 데이터 세트에 따라 다르며 실제 데이터, 새로운 학술 또는 원본 데이터 세트 또는 '황금 표준'의 다른 데이터 세트에서 반드시 수행할 가능성이 없습니다).
'소수의 벤치마크 데이터세트에 대한 연구 집중도가 높다는 점을 감안할 때, 기존 데이터세트에 대한 과대적합 및 해당 분야의 진행 상황을 잘못 표현하는 것을 방지하기 위해 다양한 형태의 평가가 특히 중요하다고 생각합니다.'
컴퓨터 비전 연구에 대한 정부의 영향력
논문에 따르면, 컴퓨터 비전 연구는 다른 분야보다 이 증후군의 영향을 더 많이 받으며, 저자들은 자연어 처리(NLP) 연구가 훨씬 덜 영향을 받는다고 지적했습니다. 저자는 NLP 커뮤니티가 다음과 같기 때문일 수 있다고 제안합니다. '더 일관된' 크기가 더 크고 NLP 데이터 세트는 액세스하기 쉽고 선별하기 쉬울 뿐만 아니라 데이터 수집 측면에서 더 작고 리소스 집약적이기 때문입니다.
컴퓨터 비전, 특히 안면 인식(FR) 데이터 세트와 관련하여 저자는 기업, 국가 및 개인의 이익이 종종 충돌한다고 주장합니다.
'기업 및 정부 기관은 프라이버시와 충돌할 수 있는 목표(예: 감시)를 가지고 있으며 이러한 우선 순위에 대한 가중치는 학계 또는 AI의 광범위한 사회적 이해 관계자가 보유한 것과 다를 수 있습니다.'
얼굴 인식 작업의 경우 연구원들은 순전히 학술 데이터 세트의 발생률이 평균에 비해 크게 떨어짐을 발견했습니다.
'[33.69개 데이터 세트 중 1개](총 사용량의 2%)는 기업, 미군 또는 중국 정부(MS-Celeb-1M, CASIA-Webface, IJB-A, VggFaceXNUMX)에서 독점적으로 자금을 지원했습니다. MS-Celeb-XNUMXM은 다양한 이해관계자의 개인 정보 보호 가치를 둘러싼 논란 때문에 결국 철회되었습니다.'

이미지 생성 및 얼굴 인식 연구 커뮤니티에서 사용되는 상위 데이터 세트입니다.
위의 그래프에서 저자가 지적한 바와 같이 이미지 생성(또는 이미지 합성)이라는 비교적 최근의 분야는 이러한 용도로 사용되지 않는 기존의 훨씬 오래된 데이터 세트에 크게 의존하고 있음을 알 수 있습니다.
사실, 이 논문은 의도된 목적에서 벗어나 데이터 세트를 '마이그레이션'하는 경향이 증가하는 것을 관찰하여 새롭거나 외부 연구 부문의 요구에 대한 데이터 세트의 적합성과 예산 제약이 데이터 세트를 '일반화'할 수 있는 정도에 의문을 제기합니다. 연구자의 야망의 범위는 사용 가능한 자료와 새로운 데이터 세트가 견인력을 얻는 데 어려움을 겪는 매년 벤치마크 등급에 너무 집착하는 문화에 의해 제공되는 더 좁은 프레임에 있습니다.
'우리의 연구 결과는 또한 데이터 세트가 서로 다른 작업 커뮤니티 간에 정기적으로 전송된다는 것을 나타냅니다. 가장 극단적인 경우, 일부 작업 커뮤니티에 대해 순환되는 대부분의 벤치마크 데이터 세트는 다른 작업을 위해 생성되었습니다.'
기계 학습 전문가(Andrew Ng 포함) 최근 몇 년 동안 데이터 세트의 다양성과 큐레이션을 점점 더 요구하고 있는 저자는 이러한 정서를 지지하지만 이러한 종류의 노력이 성공하더라도 SOTA 결과 및 확립된 데이터 세트에 대한 현재 문화의 의존도에 의해 잠재적으로 약화될 수 있다고 생각합니다. :
'우리의 연구는 단순히 ML 연구원에게 더 많은 데이터 세트를 개발하도록 요청하고 데이터 세트 개발이 가치 있고 보상되도록 인센티브 구조를 바꾸는 것만으로는 데이터 세트 사용과 궁극적으로 MLR 연구 의제를 형성하고 설정하는 관점을 다양화하기에 충분하지 않을 수 있음을 시사합니다.
'데이터 세트 개발을 장려하는 것 외에도 우리는 자원이 부족한 기관의 사람들이 고품질 데이터 세트를 생성할 수 있도록 상당한 자금을 우선적으로 지원하는 형평성 중심의 정책 개입을 지지합니다. 이것은 사회적 및 문화적 관점에서 최신 ML 방법을 평가하는 데 사용되는 벤치마크 데이터 세트를 다양화할 것입니다.'
6년 2021월 4일, 49:2pm GMT+XNUMX – 제목의 소유격 수정됨. – 석사













