
인공 지능
Amazon Mechanical Turk의 단점이 자연어 생성 시스템을 위협할 수 있음

University of Massachusetts Amherst의 새로운 연구는 영어 교사와 크라우드 소싱 근로자를 맞붙였습니다. 아마존 기계 터크 자연어 생성의 출력을 평가할 때(NLG) 시스템, 느슨한 표준과 AMT 근로자들 사이의 소중한 작업의 '도박'이 이 부문의 발전을 방해할 수 있다고 결론지었습니다.
이 보고서는 개방형 NLG 평가 작업의 '산업 규모' 저렴한 아웃소싱이 이 부문에서 열등한 결과와 알고리즘으로 이어질 수 있는 범위에 대해 여러 가지 나쁜 결론을 내립니다.
연구원들은 또한 연구가 AMT를 사용한 개방형 텍스트 생성에 관한 45개의 논문 목록을 작성했으며 '대다수'가 Amazon의 크라우드 서비스 사용에 대한 중요한 세부 정보를 보고하지 않아 재현하기 어렵다는 것을 발견했습니다. 논문의 발견.
착취 노동
이 보고서는 Amazon Mechanical Turk의 착취적인 특성과 AMT를 유효하고 일관된 연구 리소스로 사용(및 인용)하여 AMT에 추가 신뢰를 제공하는 (예산 제약이 있을 수 있는) 학술 프로젝트 모두에 대한 비판을 제기합니다. 저자는 다음과 같이 언급합니다.
'AMT는 편리하고 저렴한 솔루션이지만 우리는 작업자 간의 높은 편차, 열악한 보정 및 인지적으로 요구되는 작업으로 인해 연구자가 오해의 소지가 있는 과학적 결론을 도출할 수 있음을 관찰합니다(예: 사람이 쓴 텍스트는 GPT-2의 텍스트보다 "더 나쁘다"). ).'
보고서는 플레이어가 아닌 게임을 비난하며 연구원은 다음을 관찰했습니다.
'[군중] 노동자들은 종종 그들의 노동에 대해 저임금을 받으며, 이는 연구의 질과 더 중요한 것은 이러한 군중 노동자들이 적절한 생계를 꾸릴 수 있는 능력에 해를 끼칩니다.'
XNUMXD덴탈의 종이제목 개방형 텍스트 생성을 평가하기 위해 Mechanical Turk를 사용하는 위험, 또한 AMT가 더 저렴하더라도 언어 교사 및 언어학자와 같은 '전문 평가자'를 사용하여 개방형 인공 NLG 콘텐츠를 평가해야 한다고 결론을 내립니다.
테스트 작업
시간 제약이 덜한 전문 독자와 AMT의 성능을 비교하기 위해 연구자들은 비교 테스트에서 실제로 사용된 AMT 서비스에 144달러를 지출했습니다(비록 '사용할 수 없는' 결과에 훨씬 더 많은 비용이 사용됨 – 아래 참조). 200개의 텍스트 중 하나를 평가하기 위해 사람이 만든 텍스트 콘텐츠와 인공적으로 생성된 텍스트로 나뉩니다.
동일한 작업을 전문 교사에게 맡기는 데는 $187.50의 비용이 들고, 작업을 복제하기 위해 Upwork 프리랜서를 고용하여 (AMT 작업자와 비교하여) 우수한 성능을 확인하는 데는 추가로 $262.50의 비용이 듭니다.
각 작업은 네 가지 평가 기준으로 구성됩니다. 문법('이야기 조각의 텍스트가 문법적으로 얼마나 정확합니까?'); 일관성 ('이야기 조각의 문장이 얼마나 잘 맞습니까?'); 호감('이야기 조각이 얼마나 재미있습니까?'); 및 관련성('이야기 조각이 프롬프트와 얼마나 관련이 있습니까?').
텍스트 생성
테스트용 NLG 자료를 얻기 위해 연구원들은 Facebook AI Research의 2018 계층적 신경 스토리 생성 데이터 세트, 매우 인기 있는 사용자(303,358만 명 이상의 사용자)가 구성한 15개의 영어 스토리로 구성되어 있습니다. r/쓰기 프롬프트 subreddit에서 구독자의 스토리는 현재 관행과 유사한 방식으로 한 문장의 '프롬프트'로 '시드'됩니다. 텍스트를 이미지로 생성 – 그리고 물론 개방형 자연어 생성 시스템.
데이터 세트에서 200개의 프롬프트를 무작위로 선택하여 Hugging-Face Transformers를 사용하여 중간 크기의 GPT-2 모델에 전달했습니다. 도서관. 따라서 동일한 프롬프트에서 Reddit 사용자의 사람이 작성한 담론적 에세이와 GPT-2 생성 텍스트의 두 세트의 결과를 얻었습니다.
동일한 AMT 작업자가 동일한 스토리를 여러 번 판단하는 것을 방지하기 위해 사례당 1,500개의 AMT 작업자 판단을 요청했습니다. 근로자의 영어 능력에 관한 실험(기사 끝 참조)과 노력이 적은 근로자의 할인 결과(아래 '짧은 시간' 참조)와 함께 AMT에 대한 총 지출이 약 $XNUMX USD로 증가했습니다.
공평한 경기장을 만들기 위해 모든 테스트는 PST 기준 오전 11.00시~오전 11시 30분 사이에 실시되었습니다.
결과 및 결론
거대한 연구는 많은 근거를 다루고 있지만 핵심 사항은 다음과 같습니다.
짧은 시간
이 논문은 Amazon이 보고한 평균 작업 시간 360초가 실제 작업 시간은 22초, 평균 작업 시간은 13 초만 – 소요 시간의 XNUMX/XNUMX 가장 빠른 작업을 복제하는 영어 교사.
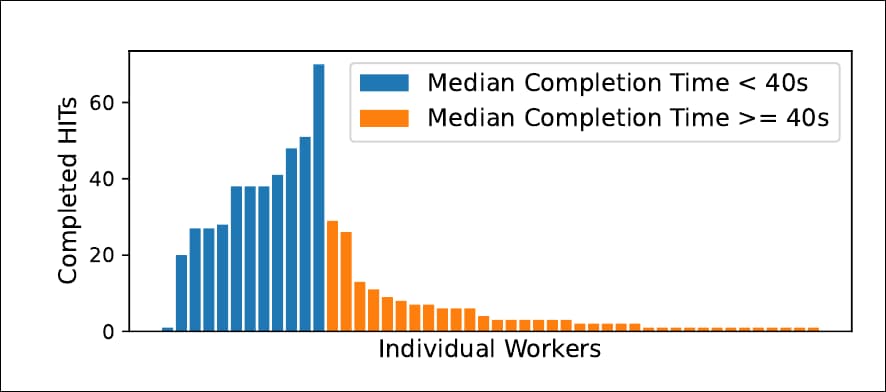
연구 2일차부터: 개별 작업자(주황색)는 급여가 더 높은 교사 및 (나중에) 훨씬 더 급여가 높은 Upwork 계약자보다 각 작업을 평가하는 데 훨씬 적은 시간을 소비했습니다. 출처 : https://arxiv.org/pdf/2109.06835.pdf
AMT는 개별 작업자가 수행할 수 있는 HIT(Human Intelligence Tasks)에 제한을 두지 않기 때문에 실험당 많은 수의 작업을 완료한다는 (수익성 있는) 평판과 함께 AMT '빅 타자'가 등장했습니다. 동일한 작업자가 허용한 적중을 보상하기 위해 연구원은 연속적으로 제출된 HIT 사이의 시간을 측정하여 각 HIT의 시작 및 종료 시간을 비교했습니다. 이러한 방식으로 AMT의 보고된 부족분 작업 시간(초) 작업에 소요된 실제 시간에 초점이 맞춰졌습니다.
이러한 작업은 이렇게 단축된 시간 내에 수행할 수 없기 때문에 연구원은 다음과 같이 보상해야 했습니다.
'단락 길이의 이야기를 주의 깊게 읽고 13초 만에 네 가지 속성을 모두 평가하는 것은 불가능하기 때문에 HIT당 너무 적은 시간을 소비하는 작업자를 걸러낼 때 평균 평점에 미치는 영향을 측정합니다. 평균 시간이 40초 미만(낮은 막대)인 근로자는 평균적으로 약 42%의 평가가 걸러지는 것을 발견했습니다(모든 실험에서 20%-72% 범위).'
논문은 AMT에서 잘못 보고된 실제 근무 시간이 서비스를 사용하는 연구원들이 일반적으로 간과하는 '주요 문제'라고 주장합니다.
손잡기 필수
연구 결과는 또한 AMT 작업자가 두 텍스트를 나란히 보지 않는 한 사람이 쓴 텍스트와 기계가 쓴 텍스트를 확실하게 구별할 수 없다는 것을 시사합니다. '실제' 또는 인위적으로 생성된 텍스트의 단일 샘플을 기반으로 판단).
저품질 인공 텍스트의 우연한 수용
품질의 차이를 쉽게 구분할 수 있는 영어 교사와 달리 AMT 작업자는 품질이 낮은 GPT 기반 인공 텍스트를 인간이 작성한 고품질의 일관성 있는 텍스트와 동등하게 일관되게 평가했습니다.
준비 시간 없음, 제로 컨텍스트
진정성 평가와 같은 추상적인 작업에 올바른 사고 방식을 입력하는 것은 자연스럽게 오지 않습니다. 영어 교사는 평가 환경에 대한 감수성을 보정하기 위해 20개의 작업이 필요한 반면 AMT 작업자는 일반적으로 '오리엔테이션 시간'이 전혀 없어 입력의 품질이 떨어집니다.
게임 시스템
이 보고서는 AMT 작업자가 개별 작업에 소비하는 총 시간은 기록된 작업 기간 동안 하나의 작업에 집중하는 대신 여러 작업을 동시에 수락하고 브라우저의 다른 탭에서 작업을 실행하는 작업자에 의해 부풀려진다고 주장합니다.
원산지가 중요하다
AMT의 기본 설정은 근로자를 출신 국가별로 필터링하지 않으며 보고서 메모 선행 연구 AMT 작업자가 VPN을 사용하여 지리적 제한을 우회하여 원어민이 아닌 사용자가 영어 원어민으로 발표할 수 있음을 나타냅니다.
따라서 연구자들은 잠재적 응시자를 제한하는 필터를 사용하여 AMT에 대한 평가 테스트를 다시 실행했습니다. X-영어권 국가, 그 발견 '비영어권 국가의 근로자는 일관성, 관련성 및 문법을 평가했습니다…동일한 자격을 갖춘 영어권 국가의 근로자보다 현저히 낮음'.
보고서는 다음과 같이 결론을 내립니다.
'[전문적인] 언어학자나 언어 교사와 같은 평가자는 이미 서면 텍스트를 평가하도록 훈련을 받았기 때문에 가능할 때마다 사용되어야 하며 훨씬 더 비싸지 않습니다...'.
16년 2021월 XNUMX일 게시됨 - 18년 2021월 XNUMX일 업데이트됨: 태그 추가됨















