
AI 101
מה זה התאמה יתר?
מה זה התאמה יתר?
כאשר אתה מאמן רשת עצבית, אתה צריך להימנע מהתאמה יתר. יתר על המידה היא בעיה בתוך למידת מכונה וסטטיסטיקה שבה מודל לומד את הדפוסים של מערך אימון טוב מדי, מסביר בצורה מושלמת את מערך נתוני האימון אך אינו מצליח להכליל את כוח הניבוי שלו לקבוצות אחרות של נתונים.
במילים אחרות, במקרה של מודל התאמה יתר הוא יראה לעתים קרובות דיוק גבוה ביותר במערך האימון אך דיוק נמוך בנתונים שנאספו וירוצו במודל בעתיד. זו הגדרה מהירה של התאמה יתרה, אבל בואו נעבור על המושג התאמה יתר בפירוט רב יותר. בואו נסתכל כיצד מתרחשת התאמת יתר וכיצד ניתן להימנע ממנה.
הבנת "התאמה" ו-underfitting
זה מועיל להסתכל על הרעיון של חוסר התאמה ו"מתאים"בדרך כלל כאשר דנים בהתאמת יתר. כאשר אנו מאמנים מודל, אנו מנסים לפתח מסגרת המסוגלת לחזות את האופי, או המחלקה, של פריטים בתוך מערך נתונים, בהתבסס על התכונות המתארות את אותם פריטים. מודל אמור להיות מסוגל להסביר דפוס בתוך מערך נתונים ולחזות את המחלקות של נקודות נתונים עתידיות בהתבסס על דפוס זה. ככל שהמודל מסביר טוב יותר את הקשר בין תכונות מערך האימונים, כך המודל שלנו "מתאים" יותר.
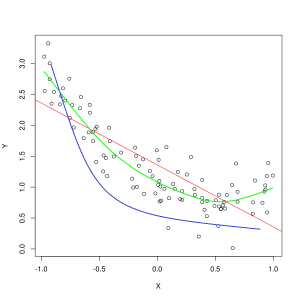
הקו הכחול מייצג תחזיות של מודל שאינו מתאים, בעוד שהקו הירוק מייצג מודל מתאים יותר. צילום: פפ רוקה דרך Wikimedia Commons, CC BY SA 3.0, (https://commons.wikimedia.org/wiki/File:Reg_ls_curvil%C3%ADnia.svg)
מודל שמסביר בצורה גרועה את הקשר בין התכונות של נתוני האימון ולכן אינו מצליח לסווג במדויק דוגמאות נתונים עתידיים הוא תת מתאים נתוני האימון. אם היית משרטט את היחס החזוי של מודל לא מתאים מול ההצטלבות האמיתית של התכונות והתוויות, התחזיות היו סוטה מהסימן. אם היה לנו גרף עם הערכים האמיתיים של ערכת אימונים מסומנת, מודל עם חוסר התאמה חמור היה מפספס באופן דרסטי את רוב נקודות הנתונים. מודל עם התאמה טובה יותר עשוי לחתוך נתיב דרך מרכז נקודות הנתונים, כאשר נקודות נתונים בודדות יורדות במעט מהערכים החזויים.
תת-התאמה יכולה להתרחש לעתים קרובות כאשר אין מספיק נתונים ליצירת מודל מדויק, או כאשר מנסים לעצב מודל ליניארי עם נתונים לא ליניאריים. יותר נתוני אימון או יותר תכונות יעזרו לעתים קרובות להפחית חוסר התאמה.
אז למה שלא ניצור מודל שמסביר כל נקודה בנתוני האימון בצורה מושלמת? אין ספק שרצוי דיוק מושלם? יצירת מודל שלמד את הדפוסים של נתוני האימון טוב מדי היא הגורמת להתאמת יתר. מערך נתוני ההדרכה ומערך נתונים עתידיים אחרים שתפעיל במודל לא יהיו זהים לחלוטין. סביר להניח שהם יהיו מאוד דומים במובנים רבים, אבל הם גם יהיו שונים במובנים מרכזיים. לכן, תכנון מודל שמסביר בצורה מושלמת את מערך ההדרכה פירושו שבסופו של דבר אתה מקבל תיאוריה לגבי הקשר בין תכונות שאינה מכללה היטב למערכי נתונים אחרים.
הבנת התאמה יתר
התאמת יתר מתרחשת כאשר מודל לומד את הפרטים בתוך מערך האימון טוב מדי, מה שגורם למודל לסבול כאשר תחזיות נעשות על נתונים חיצוניים. זה עשוי להתרחש כאשר המודל לא רק לומד את התכונות של מערך הנתונים, הוא גם לומד תנודות אקראיות או רעש בתוך מערך הנתונים, תוך מתן חשיבות להתרחשויות אקראיות/לא חשובות אלו.
סביר יותר להתרחש התאמה יתרה כאשר נעשה שימוש במודלים לא ליניאריים, מכיוון שהם גמישים יותר בעת לימוד תכונות נתונים. לאלגוריתמים לא פרמטריים של למידת מכונה יש לרוב פרמטרים וטכניקות שונות שניתן ליישם כדי להגביל את רגישות המודל לנתונים ובכך להפחית התאמה יתר. לדוגמא, מודלים של עצי החלטה הם רגישים מאוד להתאמת יתר, אך ניתן להשתמש בטכניקה הנקראת גיזום כדי להסיר באופן אקראי חלק מהפרטים שהמודל למד.
אם היית משרטט את התחזיות של המודל על צירי X ו-Y, היה לך קו חיזוי שמזגזג קדימה ואחורה, המשקף את העובדה שהמודל ניסה יותר מדי להתאים את כל הנקודות במערך הנתונים. ההסבר שלה.
שליטה בהתאמה יתר
כאשר אנו מאמנים מודל, אנו רוצים שהמודל לא יעשה שגיאות. כאשר ביצועי המודל מתכנסים לקראת ביצוע תחזיות נכונות על כל נקודות הנתונים במערך האימון, ההתאמה משתפרת. מודל עם התאמה טובה מסוגל להסביר כמעט את כל מערך האימון מבלי להתאים יותר מדי.
כאשר מודל מתאמן, הביצועים שלו משתפרים עם הזמן. שיעור השגיאות של הדגם יקטן ככל שיעבור זמן האימון, אך הוא יורד רק לנקודה מסוימת. הנקודה שבה הביצועים של הדגם בסט הבדיקה מתחילים לעלות שוב היא בדרך כלל הנקודה שבה מתרחשת התאמה יתר. על מנת לקבל את ההתאמה הטובה ביותר לדגם, אנו רוצים להפסיק את אימון הדגם בנקודת ההפסד הנמוכה ביותר בסט האימונים, לפני שהשגיאה תתחיל לגדול שוב. ניתן לקבוע את נקודת העצירה האופטימלית על ידי גרף של ביצועי המודל לאורך זמן האימון והפסקת האימון כאשר ההפסד הוא הנמוך ביותר. עם זאת, סיכון אחד בשיטה זו של בקרה על התאמת יתר הוא שציון נקודת הסיום לאימון בהתבסס על ביצועי המבחן פירושו שנתוני הבדיקה נכללים במידה מסוימת בהליך האימון, והם מאבדים את מעמדו כנתונים "לא נגעו" גרידא.
ישנן כמה דרכים שונות שבהן ניתן להילחם בהתאמת יתר. שיטה אחת להפחתת התאמת יתר היא שימוש בטקטיקה של דגימה מחדש, הפועלת על ידי הערכת הדיוק של המודל. אתה יכול גם להשתמש ב-a אימות מערך הנתונים בנוסף למערך הבדיקה ועריך את דיוק האימון מול ערכת האימות במקום מערך הבדיקה. זה שומר על מערך הנתונים של הבדיקה שלך בלתי נראה. שיטת דגימה חוזרת פופולרית היא אימות צולב של קפלי K. טכניקה זו מאפשרת לך לחלק את הנתונים שלך לתת-קבוצות שעליהן המודל מאומן, ולאחר מכן מנתחים את הביצועים של המודל בתתי-הקבוצות כדי להעריך את ביצועי המודל על נתונים חיצוניים.
שימוש באימות צולב הוא אחת הדרכים הטובות ביותר להעריך את דיוק המודל על נתונים בלתי נראים, ובשילוב עם מערך נתונים אימות ניתן לצמצם לעיתים קרובות התאמה יתרה למינימום.










