Cybersecurity
Perché gli attacchi di immagini contraddittorie non sono uno scherzo
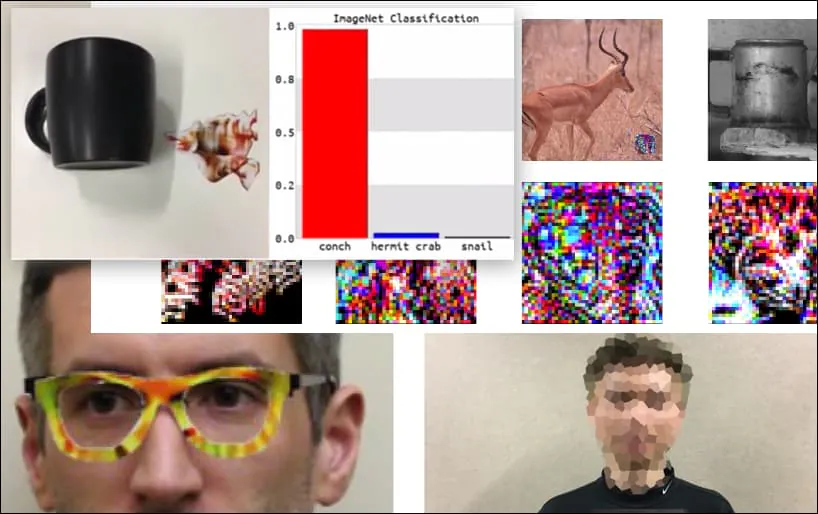
Attaccare i sistemi di riconoscimento delle immagini con immagini contraddittorie accuratamente realizzate è stato considerato una prova di concetto divertente ma banale negli ultimi cinque anni. Tuttavia, una nuova ricerca dall'Australia suggerisce che l'uso occasionale di set di dati di immagini molto popolari per progetti di IA commerciali potrebbe creare un nuovo problema di sicurezza duraturo.
Da un paio d'anni un gruppo di accademici dell'Università di Adelaide sta cercando di spiegare qualcosa di veramente importante sul futuro dei sistemi di riconoscimento delle immagini basati sull'intelligenza artificiale.
È qualcosa che sarebbe difficile (e molto costoso) da risolvere proprio adesso, e che sarebbe eccessivamente costoso porre rimedio una volta che le attuali tendenze nella ricerca sul riconoscimento delle immagini saranno state completamente sviluppate in implementazioni commercializzate e industrializzate tra 5-10 anni.
Prima di entrare nel vivo dell'argomento, diamo un'occhiata a un fiore classificato come il presidente Barack Obama, da uno dei sei video che il team ha pubblicato su pagina del progetto:
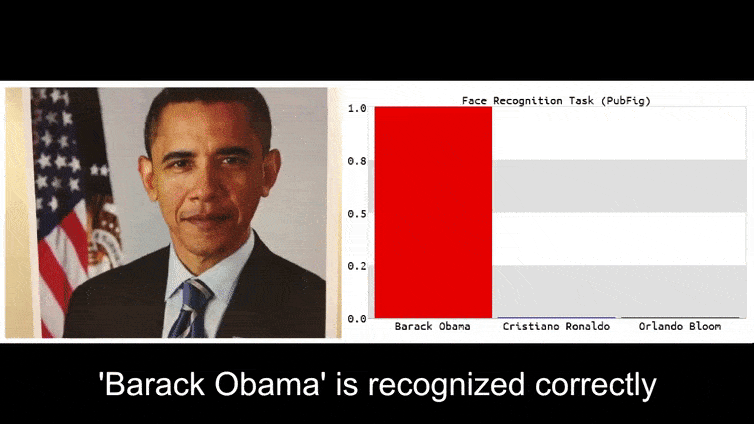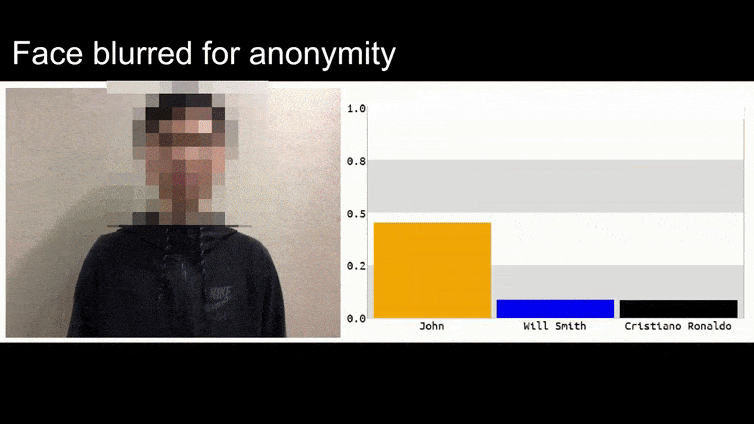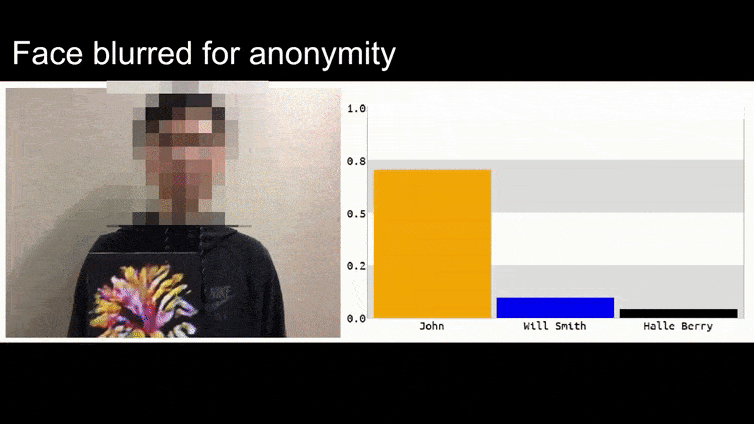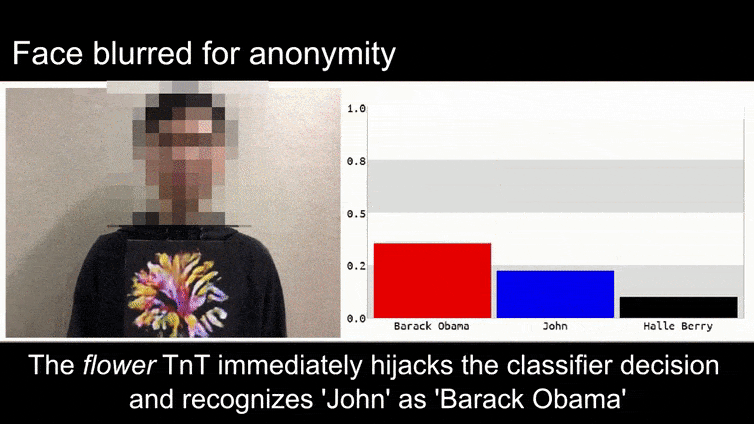
Fonte: https://www.youtube.com/watch?v=Klepca1Ny3c
Nell'immagine sopra, un sistema di riconoscimento facciale che sa chiaramente come riconoscere Barack Obama viene ingannato con l'80% di certezza che un uomo anonimizzato che tiene in mano un'immagine contraria stampata e creata ad arte di un fiore sia anch'esso Barack Obama. Al sistema non importa nemmeno che il "volto finto" sia sul petto del soggetto, anziché sulle spalle.
Anche se è impressionante che i ricercatori siano riusciti a realizzare questo tipo di acquisizione dell'identità generando un'immagine coerente (un fiore) invece del solito rumore casuale, sembra che exploit sciocchi come questo emergano abbastanza regolarmente nella ricerca sulla sicurezza della visione artificiale. . Ad esempio, quegli occhiali dalla fantasia strana che erano in grado di ingannare il riconoscimento facciale indietro nel 2016, o immagini contraddittorie appositamente predisposte che tentativo di riscrivere i segnali stradali.
Se siete interessati, il modello di rete neurale convoluzionale (CNN) attaccato nell'esempio precedente è VGGFace (VGG-16), addestrato sul dataset PubFig della Columbia University. Altri esempi di attacco sviluppati dai ricercatori hanno utilizzato risorse diverse in combinazioni differenti.

Una tastiera viene riclassificata come una conchiglia, in un modello WideResNet50 su ImageNet. I ricercatori hanno anche assicurato che il modello non abbia pregiudizi nei confronti delle conchiglie. Guarda il video completo per dimostrazioni estese e aggiuntive su https://www.youtube.com/watch?v=dhTTjjrxIcU
Riconoscimento delle immagini come vettore di attacco emergente
I numerosi attacchi impressionanti che i ricercatori delineano e illustrano non sono critiche a singoli set di dati o specifiche architetture di apprendimento automatico che li utilizzano. Né è possibile difendersi facilmente cambiando set di dati o modelli, riaddestrando i modelli o con qualsiasi altro rimedio "semplice" che fa sì che gli esperti di apprendimento automatico ridicolizzino le sporadiche dimostrazioni di questo tipo di inganno.
Piuttosto, le imprese del team di Adelaide esemplificano un debolezza centrale nell'intera architettura attuale dello sviluppo dell'intelligenza artificiale per il riconoscimento delle immagini; una debolezza che potrebbe essere impostata per esporre molti futuri sistemi di riconoscimento delle immagini a una facile manipolazione da parte di aggressori e per mettere in secondo piano qualsiasi successiva misura difensiva.
Immaginate che le ultime immagini di attacchi avversari (come il fiore qui sopra) vengano aggiunte come "exploit zero-day" ai sistemi di sicurezza del futuro, proprio come gli attuali framework anti-malware e antivirus aggiornano ogni giorno le loro definizioni dei virus.
Il potenziale per nuovi attacchi alle immagini avversarie sarebbe inesauribile, perché l'architettura di base del sistema non prevedeva problemi a valle, come si è verificato con Internet, l' Insetto del Millennio e torre pendente di Pisa.
In che modo, allora, stiamo preparando la scena per questo?
Ottenere i dati per un attacco
Immagini avversarie come l'esempio del "fiore" sopra riportato vengono generate avendo accesso ai set di dati di immagini che hanno addestrato i modelli informatici. Non è necessario un accesso "privilegiato" ai dati di addestramento (o alle architetture dei modelli), poiché i set di dati più diffusi (e molti modelli addestrati) sono ampiamente disponibili in un ambiente torrent robusto e in costante aggiornamento.
Ad esempio, il venerabile set di dati Goliath of Computer Vision, ImageNet, lo è a disposizione di Torrent in tutte le sue numerose iterazioni, aggirando la sua consuetudine restrizioni, e mettendo a disposizione elementi secondari cruciali, come ad esempio insiemi di convalida.

Fonte: https://academictorrents.com
Se si hanno i dati, è possibile (come osservano i ricercatori di Adelaide) effettuare in modo efficace il "reverse engineering" di qualsiasi set di dati popolare, come Paesaggi urbani, o CIFARE.
Nel caso di PubFig, il set di dati che ha consentito l'"Obama Flower" nell'esempio precedente, la Columbia University ha affrontato una tendenza crescente nei problemi di copyright relativi alla ridistribuzione dei set di dati di immagini istruendo i ricercatori su come riprodurre il set di dati tramite link curati, piuttosto che rendere la compilazione direttamente disponibile, osservando "Sembra che questo sia il modo in cui si stanno evolvendo altri grandi database basati sul web".
Nella maggior parte dei casi, non è necessario: Kaggle stime che i dieci set di dati di immagini più popolari nella visione artificiale sono: CIFAR-10 e CIFAR-100 (entrambi direttamente scaricabile); CALTECH-101 e 256 (entrambi disponibili ed entrambi attualmente disponibili come torrent); MNISTA (ufficialmente disponibile, anche su torrent); ImageNet (vedi sopra); Pascal COV (disponibile, anche su torrent); MS COCO (disponibile, e su torrent); Sport-1M (disponibile); e YouTube-8M (disponibile).
Questa disponibilità è anche rappresentativa della più ampia gamma di set di dati di immagini di visione artificiale disponibili, poiché l'oscurità è la morte in una cultura di sviluppo open source del tipo "pubblica o muori".
In ogni caso, la scarsità di maneggevole nuovi set di dati, l'elevato costo dello sviluppo dei set di immagini, la dipendenza dai "vecchi preferiti" e la tendenza a adatta semplicemente i set di dati più vecchi tutti aggravano il problema delineato nel nuovo documento di Adelaide.
Tipiche critiche ai metodi di attacco con immagini contraddittorie
La critica più frequente e persistente degli ingegneri dell'apprendimento automatico contro l'efficacia dell'ultima tecnica di attacco di immagini contraddittorie è che l'attacco è specifico per un particolare set di dati, un particolare modello o entrambi; che non è "generalizzabile" ad altri sistemi e, di conseguenza, rappresenta solo una minaccia banale.
La seconda lamentela più frequente è che l'attacco di immagine contraddittorio è 'scatola bianca', il che significa che avresti bisogno di un accesso diretto all'ambiente o ai dati di formazione. Questo è davvero uno scenario improbabile, nella maggior parte dei casi, ad esempio se si desidera sfruttare il processo di addestramento per i sistemi di riconoscimento facciale della polizia metropolitana di Londra, dovresti hackerare la tua strada dentro NEC, con una console o un'ascia.
Il "DNA" a lungo termine dei set di dati più diffusi sulla visione artificiale
Per quanto riguarda la prima critica, dovremmo considerare non solo che una manciata di set di dati di visione artificiale dominano l'industria per settore anno dopo anno (ad esempio ImageNet per più tipi di oggetti, CityScapes per le scene di guida e FFHQ per il riconoscimento facciale); ma anche che, in quanto semplici dati di immagini annotati, sono "indipendenti dalla piattaforma" e altamente trasferibili.
A seconda delle sue capacità, troverà qualsiasi architettura di addestramento alla visione artificiale alcuni caratteristiche di oggetti e classi nel set di dati ImageNet. Alcune architetture possono trovare più funzionalità di altre o creare connessioni più utili di altre, ma contro tutti i dovrebbe trovare almeno le funzionalità di livello più alto:

Dati ImageNet, con il numero minimo possibile di identificazioni corrette: caratteristiche di "alto livello".
Sono queste caratteristiche di "alto livello" che distinguono e "imprimono l'impronta digitale" a un set di dati e che rappresentano gli "agganci" affidabili a cui agganciare una metodologia di attacco alle immagini avversarie a lungo termine, in grado di estendersi a sistemi diversi e di crescere di pari passo con il "vecchio" set di dati, man mano che quest'ultimo viene perpetuato in nuove ricerche e prodotti.
Un'architettura più sofisticata produrrà identificazioni, caratteristiche e classi più accurate e granulari:

Tuttavia, più un generatore di attacchi contraddittori fa affidamento su questi abbassarla caratteristiche (ad esempio 'Giovane maschio caucasico' invece di 'Volto'), meno efficace sarà nelle architetture cross-over o successive che utilizzano versioni differenti del set di dati originale, come un sottoinsieme o un set filtrato, in cui molte delle immagini originali del set di dati completo non sono presenti:

Attacchi avversari su modelli pre-addestrati e "azzerati"
Che dire dei casi in cui scarichi semplicemente un modello pre-addestrato originariamente addestrato su un set di dati molto popolare e fornisci dati completamente nuovi?
Il modello è già stato addestrato su (ad esempio) ImageNet, e tutto ciò che resta è il pesi, che potrebbero aver impiegato settimane o mesi per l'addestramento e ora sono pronti per aiutarti a identificare oggetti simili a quelli che esistevano nei dati originali (ora assenti).

Una volta rimossi i dati originali dall'architettura di addestramento, ciò che resta è la "predisposizione" del modello a classificare gli oggetti nel modo in cui ha imparato a fare originariamente, il che sostanzialmente causerà la riformazione di molte delle "firme" originali, rendendole nuovamente vulnerabili agli stessi vecchi metodi di attacco alle immagini avversarie.
Quei pesi sono preziosi. Senza i dati or Con i pesi, si ottiene essenzialmente un'architettura vuota, senza dati. Sarà necessario addestrarla da zero, con un grande dispendio di tempo e risorse di calcolo, proprio come hanno fatto gli autori originali (probabilmente su hardware più potente e con un budget maggiore di quello a disposizione).
Il problema è che i pesi sono già piuttosto ben formati e resilienti. Sebbene si adattino in qualche modo durante l'addestramento, si comporteranno in modo simile sui nuovi dati come sui dati originali, producendo caratteristiche distintive su cui un sistema di attacco avversario può fare affidamento.
A lungo termine, anche questo preserva il "DNA" dei set di dati di visione artificiale che sono dodici o più anni, e potrebbe essere passato attraverso una notevole evoluzione dagli sforzi open source fino alle distribuzioni commercializzate, anche dove i dati di addestramento originali sono stati completamente eliminati all'inizio del progetto. Alcune di queste implementazioni commerciali potrebbero non avvenire ancora per anni.
Nessuna scatola bianca necessaria
Per quanto riguarda la seconda critica comune ai sistemi di attacco di immagini contraddittorie, gli autori del nuovo documento hanno scoperto che la loro capacità di ingannare i sistemi di riconoscimento con immagini di fiori create è altamente trasferibile attraverso una serie di architetture.
Pur osservando che il loro metodo 'Universal NaTuralistic adversarial paTches' (TnT) è il primo a utilizzare immagini riconoscibili (piuttosto che rumore di perturbazione casuale) per ingannare i sistemi di riconoscimento delle immagini, gli autori affermano anche:
'[TnTs] sono efficaci contro più classificatori all'avanguardia che vanno da ampiamente utilizzati WideResNet50 nel compito di riconoscimento visivo su larga scala di IMAGEnet set di dati ai modelli VGG-face nell'attività di riconoscimento facciale di PubFig set di dati in entrambi mirata e non mirato attacchi.
I 'TnTs possono possedere: i) il naturalismo ottenibile [con] trigger utilizzati nei metodi di attacco Trojan; e ii) la generalizzazione e la trasferibilità di esempi contraddittori ad altre reti.
"Ciò solleva preoccupazioni in termini di sicurezza e protezione per quanto riguarda le reti neurali neurali già implementate, nonché per le future implementazioni di reti neurali neurali, in cui gli aggressori possono utilizzare patch di oggetti dall'aspetto naturale e poco appariscenti per fuorviare i sistemi di reti neurali senza manomettere il modello e rischiare di essere scoperti".
Gli autori suggeriscono che le contromisure convenzionali, come il degrado del Clean Acc. di una rete, potrebbe teoricamente fornire una certa difesa contro le patch TnT, ma quello 'I tritoni possono ancora aggirare con successo questi metodi di difesa dimostrabili SOTA, con la maggior parte dei sistemi di difesa che raggiungono lo 0% di robustezza'.
Possibili altre soluzioni includono apprendimento federato, dove la provenienza delle immagini che contribuiscono è protetta, e nuovi approcci che potrebbero "criptare" direttamente i dati al momento dell'addestramento, come uno recentemente suggerito dall'Università di aeronautica e astronautica di Nanchino.
Anche in quei casi, sarebbe importante allenarsi veramente nuovi dati di immagine: ormai le immagini e le annotazioni associate nel piccolo gruppo dei set di dati CV più diffusi sono così integrate nei cicli di sviluppo in tutto il mondo da assomigliare più a software che a dati; software che spesso non viene aggiornato in modo significativo da anni.
Conclusione
Gli attacchi alle immagini avversarie sono resi possibili non solo dalle pratiche di apprendimento automatico open source, ma anche da una cultura di sviluppo dell'intelligenza artificiale aziendale che è motivata a riutilizzare set di dati di visione artificiale consolidati per diverse ragioni: si sono già dimostrati efficaci; sono molto più economici rispetto al "partire da zero"; e sono mantenuti e aggiornati da menti e organizzazioni all'avanguardia nel mondo accademico e industriale, con livelli di finanziamento e personale che sarebbero difficili da replicare per una singola azienda.
Inoltre, in molti casi in cui i dati non sono originali (a differenza di CityScapes), le immagini sono state raccolte prima delle recenti controversie sulla privacy e sulle pratiche di raccolta dei dati, lasciando questi vecchi set di dati in una sorta di purgatorio semilegale che può sembrare confortante come un "porto sicuro" dal punto di vista di un'azienda.
Attacchi TnT! Patch avversarie naturalistiche universali contro sistemi di reti neurali profonde è coautore di Bao Gia Doan, Minhui Xue, Ehsan Abbasnejad, Damith C. Ranasinghe dell'Università di Adelaide, insieme a Shiqing Ma del Dipartimento di Informatica della Rutgers University.
Aggiornato il 1° dicembre 2021, 7:06 GMT+2 – errore di battitura corretto.












