
Intelligenza Artificiale
Verso esseri umani IA in tempo reale con il rendering del lumigrafo neurale

Nonostante l'attuale ondata di interesse per i Neural Radiance Fields (NeRF), una tecnologia in grado di creare ambienti e oggetti 3D generati dall'intelligenza artificiale, questo nuovo approccio alla tecnologia di sintesi delle immagini richiede ancora molto tempo di formazione e manca di un'implementazione che consenta interfacce altamente reattive in tempo reale.
Tuttavia, una collaborazione tra alcuni nomi impressionanti dell'industria e del mondo accademico offre una nuova interpretazione di questa sfida (generalmente nota come Novel View Synthesis o NVS).
La ricerca carta, intitolato Rendering del lumigrafo neurale, afferma un miglioramento rispetto allo stato dell'arte di circa due ordini di grandezza, che rappresenta diversi passi avanti verso il rendering CG in tempo reale tramite pipeline di apprendimento automatico.

Neural Lumigraph Rendering (a destra) offre una migliore risoluzione degli artefatti di fusione e una migliore gestione dell'occlusione rispetto ai metodi precedenti. Fonte: https://www.youtube.com/watch?v=maVF-7×9644
Sebbene i crediti per il documento citino solo la Stanford University e la società di tecnologia di visualizzazione olografica Raxium (attualmente operante in Modalità Nascosta), i contributori includono un principale machine learning architetto in Google, un computer scienziato presso Adobe e il CTO at File Storia (che ha reso titoli recentemente con una versione AI di William Shatner).
Per quanto riguarda il recente blitz pubblicitario di Shatner, StoryFile sembra impiegare NLR nel suo nuovo processo per la creazione di entità interattive generate dall'intelligenza artificiale basate sulle caratteristiche e le narrazioni delle singole persone.

StoryFile prevede l'uso di questa tecnologia nelle esposizioni museali, nelle narrazioni interattive online, nelle esposizioni olografiche, nella realtà aumentata (AR) e nella documentazione del patrimonio – e sembra anche osservare potenziali nuove applicazioni della NLR nei colloqui di reclutamento e nelle applicazioni di appuntamenti virtuali:

Usi proposti da un video online di StoryFile. Fonte: https://www.youtube.com/watch?v=2K9J6q5DqRc
Acquisizione volumetrica per nuove interfacce di sintesi e video
Il principio dell'acquisizione volumetrica, attraverso la gamma di documenti che si stanno accumulando sull'argomento, è l'idea di acquisire immagini fisse o video di un soggetto e utilizzare l'apprendimento automatico per "riempire" i punti di vista che non erano coperti dall'originale schiera di telecamere.
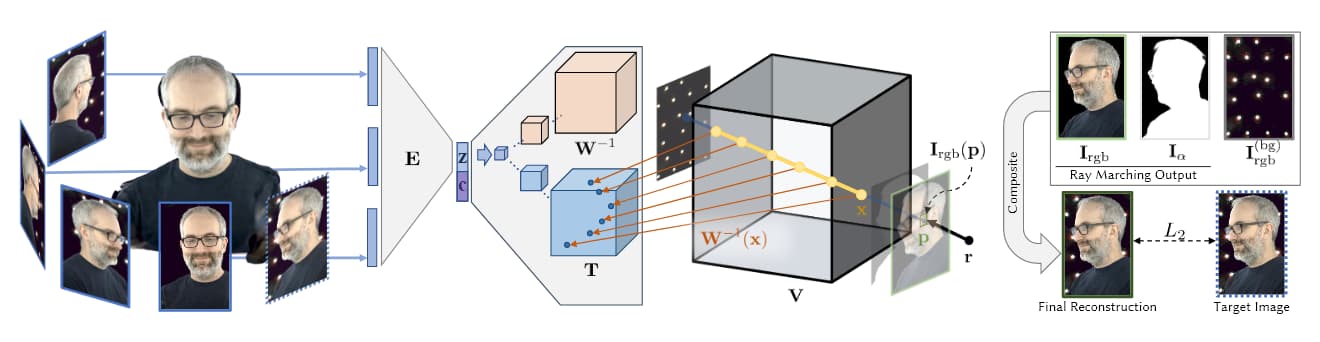
Fonte: https://research.fb.com/wp-content/uploads/2019/06/Neural-Volumes-Learning-Dynamic-Renderable-Volumes-from-Images.pdf
Nell'immagine sopra, tratta dalla ricerca AI 2019 AI di Facebook (vedi sotto), vediamo le quattro fasi dell'acquisizione volumetrica: più telecamere ottengono immagini/filmati; l'architettura codificatore/decodificatore (o altre architetture) calcola e concatena la relatività delle viste; gli algoritmi di ray-marching calcolano il voxel (o altre unità geometriche spaziali XYZ) di ogni punto dello spazio volumetrico; e (nei documenti più recenti) avviene l'addestramento per sintetizzare un'entità completa che può essere manipolata in tempo reale.
È questa fase di addestramento spesso estesa e ricca di dati che, fino ad oggi, ha tenuto la sintesi di nuove viste fuori dal regno dell'acquisizione in tempo reale o altamente reattiva.
Il fatto che Novel View Synthesis realizzi una mappa 3D completa di uno spazio volumetrico significa che è relativamente banale unire questi punti insieme in una mesh generata dal computer tradizionale, catturando e articolando efficacemente un essere umano CGI (o qualsiasi altro oggetto relativamente delimitato) su- La mosca.
Gli approcci che utilizzano NeRF si basano su nuvole di punti e mappe di profondità per generare le interpolazioni tra i punti di vista sparsi dei dispositivi di acquisizione:

NeRF può generare profondità volumetrica attraverso il calcolo di mappe di profondità, piuttosto che la generazione di mesh CG. Fonte: https://www.youtube.com/watch?v=JuH79E8rdKc
Anche se NeRF lo è capace del calcolo delle mesh, la maggior parte delle implementazioni non lo utilizza per generare scene volumetriche.
Al contrario, il renderer differenziabile implicito (IDR) approccio, pubblicato dal Weizmann Institute of Science nell'ottobre 2020, dipende dallo sfruttamento delle informazioni mesh 3D generate automaticamente dagli array di acquisizione:

Esempi di acquisizioni IDR trasformate in mesh CGI interattive. Fonte: https://www.youtube.com/watch?v=C55y7RhJ1fE
Sebbene NeRF manchi della capacità di IDR per la stima della forma, IDR non può eguagliare la qualità dell'immagine di NeRF ed entrambi richiedono ampie risorse per l'addestramento e la raccolta (sebbene le recenti innovazioni in NeRF siano inizio a affrontare questo).

Attrezzatura fotografica personalizzata di NLR con 16 telecamere GoPro HERO7 e 6 telecamere centrali Back-Bone H7PRO. Per il rendering "in tempo reale", questi funzionano a un minimo di 60 fps. Fonte: https://arxiv.org/pdf/2103.11571.pdf
Invece, utilizza Neural Lumigraph Rendering SIRENA (Sinusoidal Representation Networks) per incorporare i punti di forza di ciascun approccio nel proprio framework, che ha lo scopo di generare output direttamente utilizzabile nelle pipeline grafiche esistenti in tempo reale.
SIREN è stato utilizzato per implementazioni simili nell'ultimo anno, e ora rappresenta a popolare chiamata API per i Colab hobbisti nelle comunità di sintesi delle immagini; tuttavia, l'innovazione di NLR consiste nell'applicare SIREN alla supervisione di immagini bidimensionali multi-vista, il che è problematico a causa della misura in cui SIREN produce un output sovradimensionato piuttosto che generalizzato.
Dopo che la mesh CG è stata estratta dalle immagini dell'array, la mesh viene rasterizzata tramite OpenGL e le posizioni dei vertici della mesh mappate sui pixel appropriati, dopodiché viene calcolata la fusione delle varie mappe che contribuiscono.
La mesh risultante è più generalizzata e rappresentativa di quella di NeRF (vedi immagine sotto), richiede meno calcoli e non applica dettagli eccessivi alle aree (come la pelle liscia del viso) che non possono beneficiarne:

Fonte: https://arxiv.org/pdf/2103.11571.pdf
Sul lato negativo, NLR non ha ancora alcuna capacità di illuminazione dinamica o riaccensionee l'output è limitato alle mappe delle ombre e ad altre considerazioni sull'illuminazione ottenute al momento dell'acquisizione. I ricercatori intendono affrontare questo problema in lavori futuri.
Inoltre, il documento ammette che le forme generate da NLR non sono accurate come alcuni approcci alternativi, come ad esempio Pixelwise View Selection per stereo multivista non strutturato, o la ricerca del Weizmann Institute menzionata in precedenza.
L'ascesa della sintesi volumetrica delle immagini
L'idea di creare entità 3D da una serie limitata di foto con reti neurali precede NeRF, con articoli visionari che risalgono al 2007 o prima. Nel 2019 il dipartimento di ricerca sull'intelligenza artificiale di Facebook ha prodotto un documento di ricerca seminale, Volumi neurali: apprendimento di volumi renderizzabili dinamici dalle immagini, che per prima ha abilitato interfacce reattive per esseri umani sintetici generati dall'acquisizione volumetrica basata sull'apprendimento automatico.

La ricerca di Facebook del 2019 ha consentito la creazione di un'interfaccia utente reattiva per una persona volumetrica. Fonte: https://research.fb.com/publications/neural-volumes-learning-dynamic-renderable-volumes-from-images/















