
Intelligenza Artificiale
Tre sfide in vista per una diffusione stabile

. rilasciare della diffusione stabile di stability.ai diffusione latente modello di sintesi delle immagini un paio di settimane fa potrebbe essere una delle rivelazioni tecnologiche più significative dal DeCSS nel 1999; è certamente il più grande evento nell'ambito delle immagini generate dall'intelligenza artificiale dal 2017 codice deepfake è stato copiato su GitHub e biforcuto in quello che sarebbe diventato DeepFaceLab e Cambia faccia, così come il software deepfake in streaming in tempo reale DeepFace dal vivo.
Di colpo, frustrazione dell'utente sulla restrizioni sui contenuti nell'API di sintesi delle immagini di DALL-E 2 sono stati spazzati via, poiché è emerso che il filtro NSFW di Stable Diffusion poteva essere disabilitato modificando un unica riga di codice. I reddit di Stable Diffusion incentrati sul porno sono nati quasi immediatamente e sono stati altrettanto rapidamente abbattuti, mentre il campo degli sviluppatori e degli utenti si è diviso su Discord nelle comunità ufficiali e NSFW e Twitter ha iniziato a riempirsi di fantastiche creazioni di Stable Diffusion.
Al momento, ogni giorno sembra portare qualche sorprendente innovazione da parte degli sviluppatori che hanno adottato il sistema, con plugin e aggiunte di terze parti scritti frettolosamente per Krita, Photoshop, Cinema4D, Frullatoree molte altre piattaforme applicative.

Nel frattempo, promptcraft – l’arte ormai professionale del “sussurro dell’IA”, che potrebbe finire per essere l’opzione di carriera più breve dai tempi del “raccoglitore Filofax” – sta già diventando commercializzato, mentre la monetizzazione anticipata di Stable Diffusion è in corso presso il Livello Patreon, con la certezza di offerte più sofisticate in arrivo, per chi non vuole navigare Basato su Conda installazioni del codice sorgente o i filtri NSFW proscrittivi delle implementazioni basate sul web.
Il ritmo dello sviluppo e la libera esplorazione da parte degli utenti procedono a una velocità così vertiginosa che è difficile guardare molto lontano. In sostanza, non sappiamo ancora esattamente con cosa abbiamo a che fare, né quali possano essere tutti i limiti o le possibilità.
Ciononostante, diamo un'occhiata a tre di quelli che potrebbero essere gli ostacoli più interessanti e impegnativi che la comunità Stable Diffusion, in rapida formazione e crescita, dovrà affrontare e, si spera, superare.
1: Ottimizzazione delle pipeline basate su tile
Presentato con risorse hardware limitate e limiti rigidi sulla risoluzione delle immagini di addestramento, sembra probabile che gli sviluppatori troveranno soluzioni alternative per migliorare sia la qualità che la risoluzione dell'output di Stable Diffusion. Molti di questi progetti implicheranno lo sfruttamento dei limiti del sistema, come la sua risoluzione nativa di soli 512 × 512 pixel.
Come sempre accade con le iniziative di visione artificiale e sintesi di immagini, Stable Diffusion è stato addestrato su immagini con rapporto quadrato, in questo caso ricampionate a 512×512, in modo che le immagini sorgente potessero essere regolarizzate e in grado di adattarsi ai vincoli delle GPU che addestrato il modello.
Pertanto, Stable Diffusion "pensa" (se pensa) in termini di 512×512, e certamente in termini quadrati. Molti utenti che stanno attualmente sondando i limiti del sistema segnalano che Stable Diffusion produce i risultati più affidabili e meno instabili con questo rapporto d'aspetto piuttosto limitato (vedere "affrontare i limiti" di seguito).
Sebbene varie implementazioni presentino l'upscaling tramite RealESRGAN (e può correggere i volti mal renderizzati tramite GFPGAN) diversi utenti stanno attualmente sviluppando metodi per suddividere le immagini in sezioni di 512x512px e unire le immagini insieme per formare opere composite più grandi.

Questo rendering 1024×576, una risoluzione normalmente impossibile in un singolo rendering Stable Diffusion, è stato creato copiando e incollando il file Python attention.py dal DoggettX fork di Stable Diffusion (una versione che implementa l'upscaling basato su tile) in un altro fork. Fonte: https://old.reddit.com/r/StableDiffusion/comments/x6yeam/1024x576_with_6gb_nice/
Sebbene alcune iniziative di questo tipo utilizzino codice originale o altre librerie, il porta txt2imghd di GOBIG (una modalità nel ProgRockDiffusion affamato di VRAM) è impostato per fornire presto questa funzionalità al ramo principale. Sebbene txt2imghd sia un porting dedicato di GOBIG, altri sforzi da parte degli sviluppatori della comunità comportano diverse implementazioni di GOBIG.

Un'immagine opportunamente astratta nel rendering originale da 512x512px (a sinistra e la seconda da sinistra); ingrandita da ESGRAN, che ora è più o meno nativa in tutte le distribuzioni Stable Diffusion; e a cui è stata data "un'attenzione speciale" tramite un'implementazione di GOBIG, producendo dettagli che, almeno entro i limiti della sezione dell'immagine, sembrano meglio ingranditi. Sfonte: https://old.reddit.com/r/StableDiffusion/comments/x72460/stable_diffusion_gobig_txt2imghd_easy_mode_colab/
Il tipo di esempio astratto presentato sopra ha molti "piccoli regni" di dettaglio che si adattano a questo approccio solipsistico all'upscaling, ma che potrebbero richiedere soluzioni guidate dal codice più impegnative per produrre un upscaling non ripetitivo e coeso che non Dai un'occhiata Come se fosse stato assemblato da più parti. Non da ultimo, nel caso dei volti umani, dove siamo insolitamente sensibili alle aberrazioni o agli artefatti "sconvolgenti". Pertanto, i volti potrebbero alla fine richiedere una soluzione dedicata.
Attualmente, Stable Diffusion non dispone di alcun meccanismo per focalizzare l'attenzione sul volto durante un rendering, nello stesso modo in cui gli esseri umani danno priorità alle informazioni facciali. Sebbene alcuni sviluppatori nelle community di Discord stiano prendendo in considerazione metodi per implementare questo tipo di "attenzione potenziata", al momento è molto più semplice migliorare manualmente (e, in futuro, automaticamente) il volto dopo il rendering iniziale.
Un volto umano ha una logica semantica interna e completa che non si trova in una "riquadro" dell'angolo inferiore (ad esempio) di un edificio, e quindi attualmente è possibile "ingrandire" in modo molto efficace e rielaborare un volto "abbozzato" nell'output di Stable Diffusion.

A sinistra, il primo tentativo di Stable Diffusion con il prompt "Foto a colori a figura intera di Christina Hendricks che entra in un luogo affollato, indossando un impermeabile; Canon50, contatto visivo, elevato dettaglio, elevato dettaglio del viso". A destra, un volto migliorato ottenuto restituendo a Stable Diffusion il volto sfocato e abbozzato del primo rendering tramite Img2Img (vedi immagini animate sotto).
In assenza di una soluzione Textual Inversion dedicata (vedi sotto), funzionerà solo per le immagini di celebrità in cui la persona in questione è già ben rappresentata nei sottoinsiemi di dati LAION che hanno addestrato Stable Diffusion. Pertanto funzionerà su artisti del calibro di Tom Cruise, Brad Pitt, Jennifer Lawrence e una gamma limitata di autentici luminari dei media che sono presenti in un gran numero di immagini nei dati di origine.
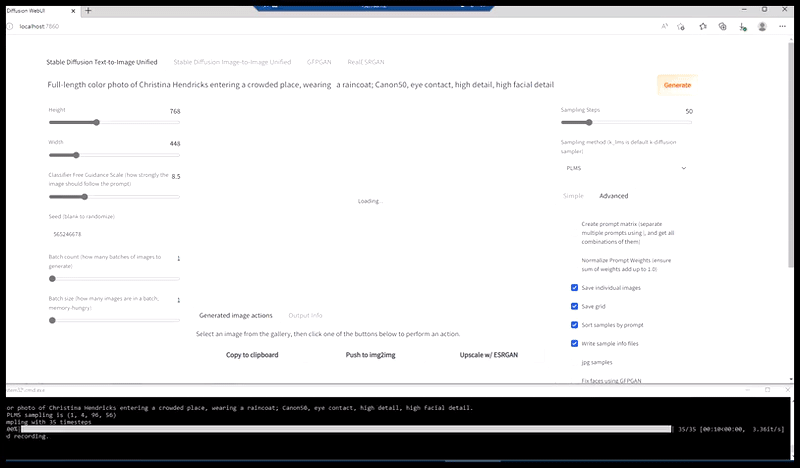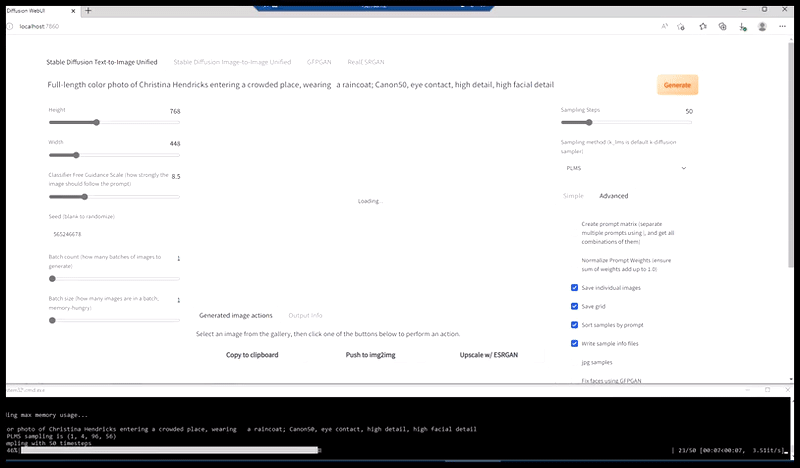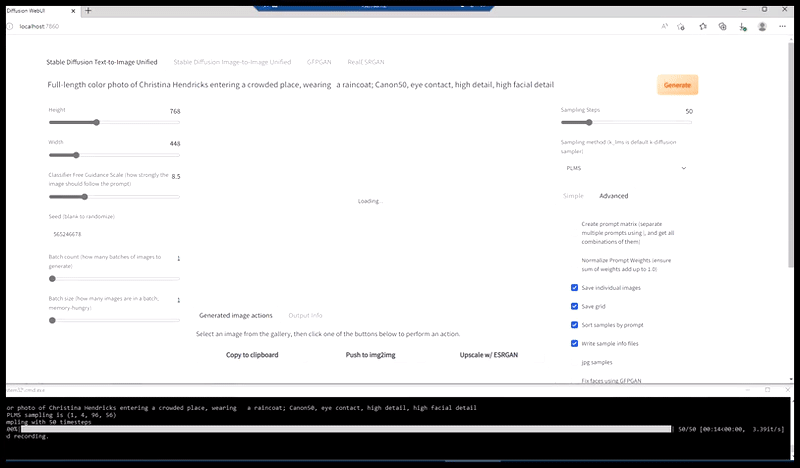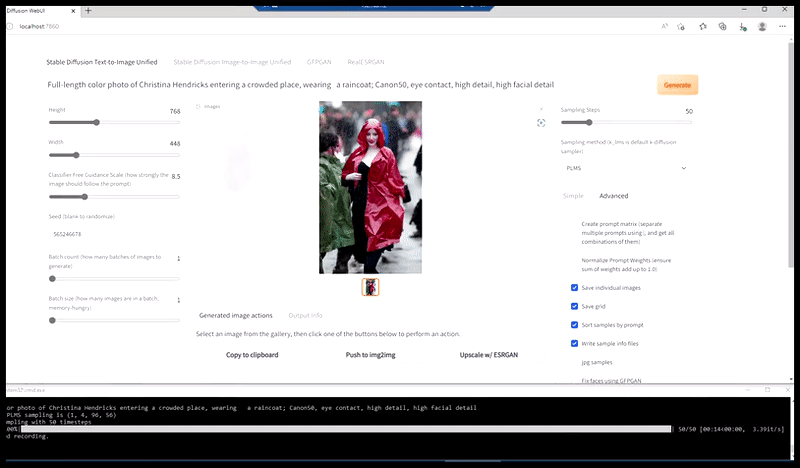
Generazione di un'immagine stampa plausibile con il prompt "Foto a colori a figura intera di Christina Hendricks che entra in un luogo affollato, indossando un impermeabile; Canon50, contatto visivo, elevato livello di dettaglio, elevato livello di dettaglio del viso".
Per le celebrità con carriere lunghe e durature, Stable Diffusion genererà solitamente un'immagine della persona in un'età recente (cioè più avanzata), e sarà necessario aggiungere aggiunte immediate come 'giovane' or 'nell'anno [ANNO]' per produrre immagini dall'aspetto più giovane.

Con una carriera importante, molto fotografata e coerente che dura da quasi 40 anni, l'attrice Jennifer Connelly è una delle poche celebrità di LAION che consentono a Stable Diffusion di rappresentare una gamma di età. Fonte: prepack Stable Diffusion, locale, checkpoint v1.4; suggerimenti legati all'età.
Ciò è in gran parte dovuto alla proliferazione della fotografia di stampa digitale (piuttosto che costosa, basata su emulsione) dalla metà degli anni 2000 in poi e alla successiva crescita del volume di output di immagini dovuto all'aumento della velocità della banda larga.
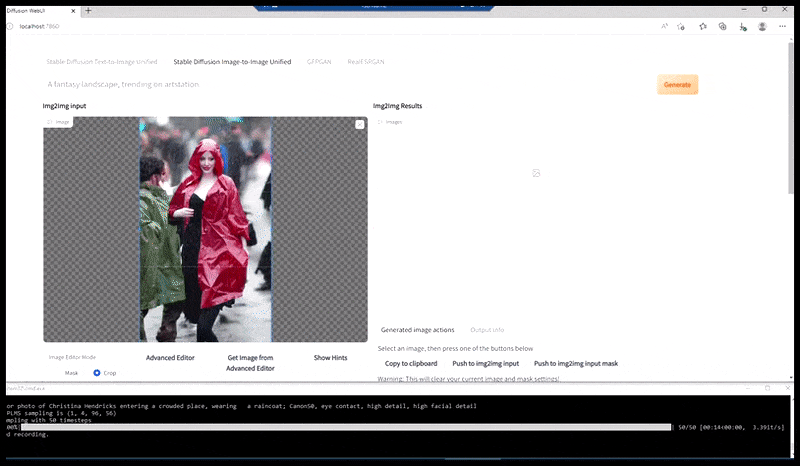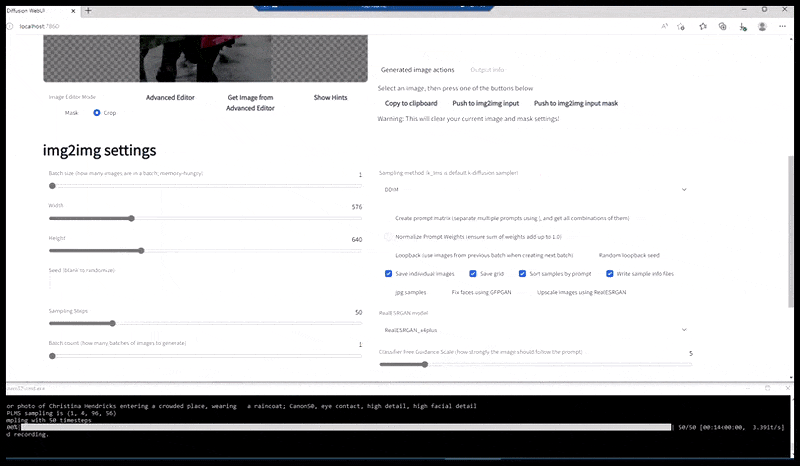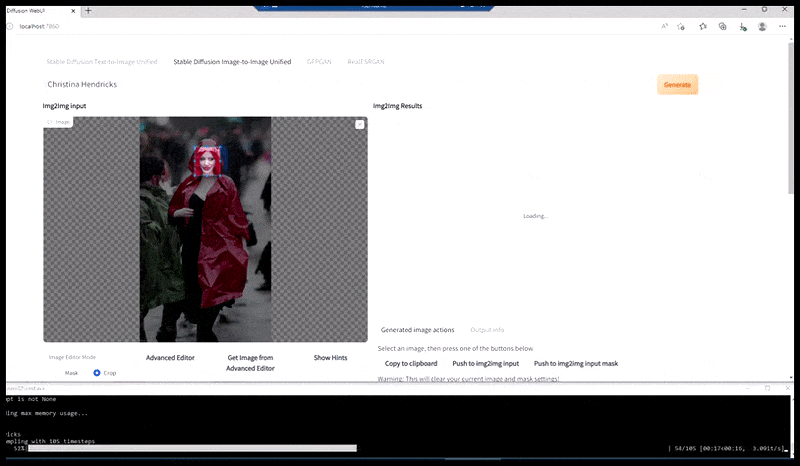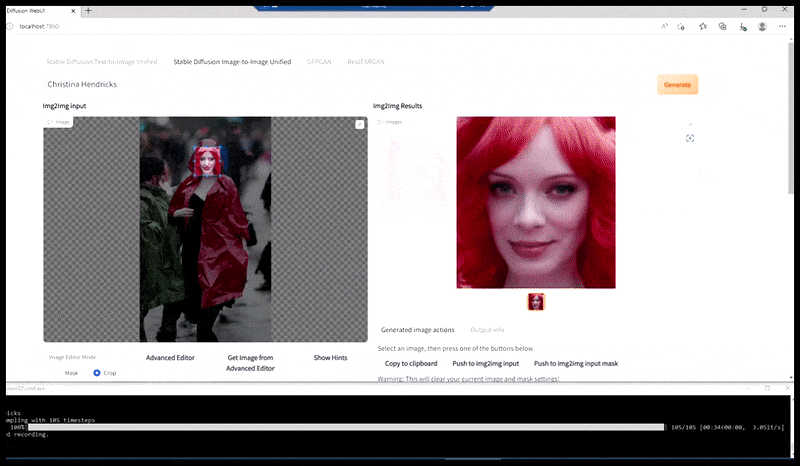
L'immagine renderizzata viene passata a Img2Img in Stable Diffusion, dove viene selezionata un'area di messa a fuoco e viene eseguito un nuovo rendering di dimensioni massime solo di quell'area, consentendo a Stable Diffusion di concentrare tutte le risorse disponibili sulla ricreazione del volto.
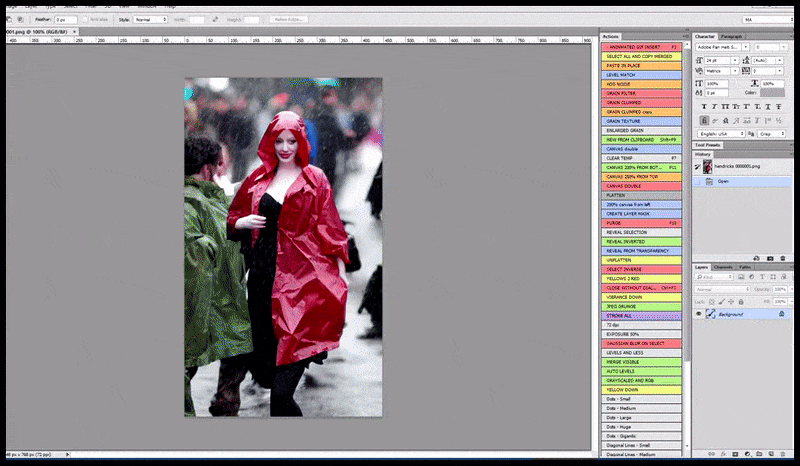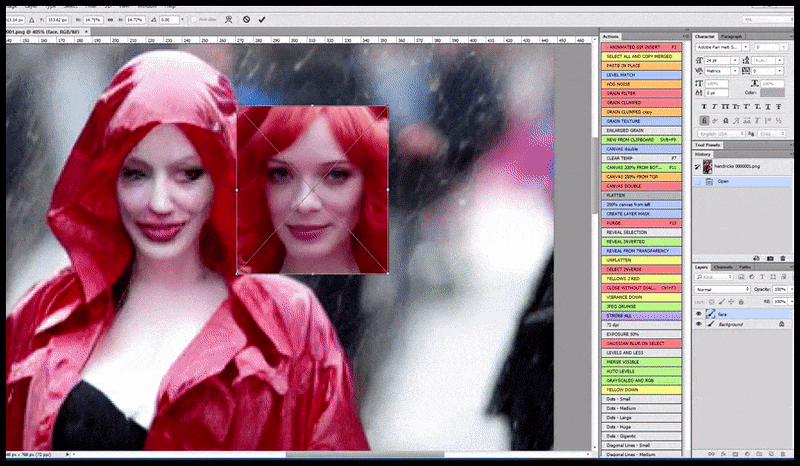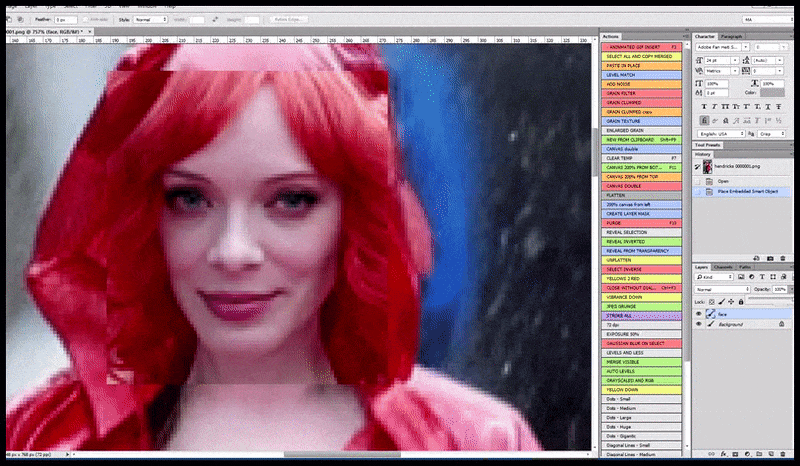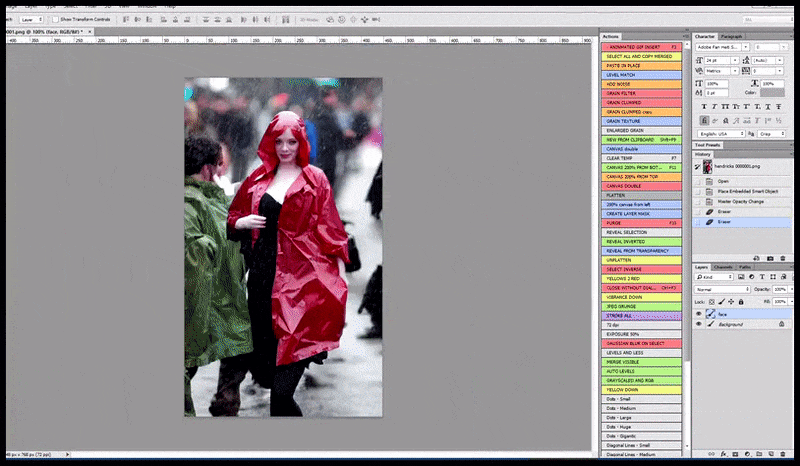
Ricomposizione del volto "ad alta attenzione" nel rendering originale. Oltre ai volti, questo processo funziona solo con entità che hanno un aspetto potenzialmente noto, coeso e integrale, come una porzione della foto originale che presenta un oggetto distinto, come un orologio o un'auto. Ingrandire una sezione, ad esempio, di un muro porterà a un muro riassemblato dall'aspetto molto strano, perché i rendering delle tessere non avevano un contesto più ampio per questo "pezzo di puzzle" durante il rendering.
Alcune celebrità presenti nel database risultano "pre-congelate" nel tempo, sia perché sono morte prematuramente (come Marilyn Monroe), sia perché hanno raggiunto solo una breve notorietà, producendo un elevato volume di immagini in un periodo di tempo limitato. Polling Stable Diffusion fornisce presumibilmente una sorta di indice di popolarità "attuale" per le star moderne e più anziane. Per alcune celebrità, sia più anziane che attuali, i dati di origine non contengono immagini sufficienti per ottenere una somiglianza molto buona, mentre la popolarità duratura di particolari star morte da tempo o altrimenti scomparse garantisce che la loro somiglianza ragionevole possa essere ottenuta dal sistema.

I rendering Stable Diffusion rivelano rapidamente quali volti famosi sono ben rappresentati nei dati di addestramento. Nonostante la sua enorme popolarità come adolescente più grande al momento della scrittura, Millie Bobby Brown era più giovane e meno conosciuta quando i set di dati di origine LAION sono stati cancellati dal web, rendendo al momento problematica una somiglianza di alta qualità con Stable Diffusion.
Laddove i dati sono disponibili, le soluzioni up-res basate su tile in Stable Diffusion potrebbero andare oltre l'homing sul viso: potrebbero potenzialmente consentire volti ancora più precisi e dettagliati abbattendo le caratteristiche facciali e trasformando l'intera forza della GPU locale risorse sulle caratteristiche salienti individualmente, prima del riassemblaggio – un processo che attualmente è, di nuovo, manuale.

Questo non è limitato ai volti, ma è limitato a parti di oggetti che sono almeno altrettanto prevedibilmente collocati nel contesto più ampio dell'oggetto ospite e che sono conformi a incorporamenti di alto livello che ci si potrebbe ragionevolmente aspettare di trovare in un'iperscala insieme di dati.
Il vero limite è la quantità di dati di riferimento disponibili nel set di dati, perché, alla fine, i dettagli più approfonditi diventeranno totalmente "allucinati" (cioè fittizi) e meno autentici.
Tali ingrandimenti granulari di alto livello funzionano nel caso di Jennifer Connelly, perché è ben rappresentata in una gamma di età in LAION-estetica (il sottoinsieme primario di LAION 5B che utilizza Stable Diffusion) e in generale in LAION; in molti altri casi, l'accuratezza risentirebbe della mancanza di dati, rendendo necessaria una messa a punto (formazione aggiuntiva, vedere "Personalizzazione" di seguito) o l'inversione testuale (vedere di seguito).
I riquadri sono un modo potente e relativamente economico per consentire a Stable Diffusion di produrre output ad alta risoluzione, ma l'upscaling algoritmico a riquadri di questo tipo, se manca di un qualche tipo di meccanismo di attenzione più ampio e di livello superiore, potrebbe non essere all'altezza dell'auspicato- standard per una vasta gamma di tipi di contenuto.
2: Affrontare i problemi con gli arti umani
Stable Diffusion non è all'altezza del suo nome quando descrive la complessità delle estremità umane. Le mani possono moltiplicarsi in modo casuale, le dita si fondono, le terze gambe compaiono inaspettatamente e gli arti esistenti svaniscono senza lasciare traccia. A sua discolpa, Stable Diffusion condivide il problema con i suoi compagni di scuderia, e sicuramente con DALL-E 2.

Risultati non modificati di DALL-E 2 e Stable Diffusion (1.4) alla fine di agosto 2022, entrambi mostrano problemi agli arti. Il prompt è "Una donna che abbraccia un uomo".
I fan di Stable Diffusion che sperano che l'imminente checkpoint 1.5 (una versione più intensamente addestrata del modello, con parametri migliorati) risolva la confusione degli arti probabilmente rimarranno delusi. Il nuovo modello, che sarà rilasciato in circa due settimane, è attualmente in anteprima sul portale commerciale stability.ai Studio dei sogni, che utilizza 1.5 per impostazione predefinita e dove gli utenti possono confrontare il nuovo output con i rendering dei loro sistemi 1.4 locali o di altro tipo:

Fonte: prepack locale 1.4 e https://beta.dreamstudio.ai/

Fonte: prepack locale 1.4 e https://beta.dreamstudio.ai/

Fonte: prepack locale 1.4 e https://beta.dreamstudio.ai/
Come spesso accade, la qualità dei dati potrebbe essere la principale causa che contribuisce.
I database open source che alimentano i sistemi di sintesi delle immagini come Stable Diffusion e DALL-E 2 sono in grado di fornire molte etichette sia per i singoli esseri umani che per l'azione interumana. Queste etichette vengono addestrate in simbiosi con le loro immagini associate, o segmenti di immagini.

Gli utenti di Stable Diffusion possono esplorare i concetti acquisiti nel modello interrogando il dataset LAION-aesthetics, un sottoinsieme del più ampio dataset LAION 5B, che alimenta il sistema. Le immagini non sono ordinate in base alle etichette alfabetiche, ma in base al loro "punteggio estetico". Fonte: https://rom1504.github.io/clip-retrieval/
A buona gerarchia di Etichette e classi individuali che contribuiscono alla rappresentazione di un braccio umano sarebbe qualcosa di simile corpo>braccio>mano>dita>[sottocifre + pollice]> [segmenti di cifre]>unghie.

Segmentazione semantica granulare delle parti di una mano. Persino questa decostruzione insolitamente dettagliata considera ogni "dito" come un'entità unica, senza tenere conto delle tre sezioni di un dito e delle due sezioni di un pollice. Fonte: https://athitsos.utasites.cloud/publications/rezaei_petra2021.pdf
In realtà, è improbabile che le immagini di origine siano annotate in modo così coerente nell'intero set di dati e gli algoritmi di etichettatura senza supervisione probabilmente si fermeranno al punto superiore livello di – ad esempio – 'mano', e lasciare i pixel interni (che tecnicamente contengono informazioni sul 'dito') come una massa di pixel non etichettata da cui verranno derivate arbitrariamente delle caratteristiche, e che potrebbero manifestarsi in rendering successivi come un elemento stridente.

Come dovrebbe essere (in alto a destra, se non in alto) e come tende ad essere (in basso a destra), a causa delle risorse limitate per l'etichettatura o dello sfruttamento architettonico di tali etichette se esistono nel set di dati.
Quindi, se un modello di diffusione latente arriva a rendere un braccio, è quasi certo che almeno tenterà di rendere una mano all'estremità di quel braccio, perché braccio>mano è la gerarchia minima richiesta, piuttosto in alto in ciò che l'architettura conosce dell'"anatomia umana".
Dopodiché, "dita" potrebbe essere il raggruppamento più piccolo, anche se ci sono altre 14 sottoparti di dita/pollice da considerare quando si raffigurano le mani umane.
Se questa teoria è valida, non esiste un vero rimedio, a causa della mancanza di budget a livello di settore per l'annotazione manuale e della mancanza di algoritmi adeguatamente efficaci che potrebbero automatizzare l'etichettatura producendo bassi tassi di errore. In effetti, il modello potrebbe attualmente fare affidamento sulla coerenza anatomica umana per coprire le carenze del set di dati su cui è stato addestrato.
Una possibile ragione per cui non può fare affidamento su questo, di recente proposto alla Stable Diffusion Discord, è che il modello potrebbe confondersi sul numero corretto di dita che una mano umana (realistica) dovrebbe avere perché il database derivato da LAION che lo alimenta contiene personaggi dei cartoni animati che possono avere meno dita (il che è di per sé una scorciatoia per risparmiare lavoro).

Due dei potenziali responsabili della sindrome del "dito mancante" in modelli di diffusione stabile e simili. Di seguito, esempi di mani in stile cartoon tratti dal dataset LAION-aesthetics alla base di Stable Diffusion. Fonte: https://www.youtube.com/watch?v=0QZFQ3gbd6I
Se questo è vero, allora l'unica soluzione ovvia è quella di riqualificare il modello, escludendo i contenuti umani non realistici, assicurando che i casi di omissione genuina (ad esempio gli amputati) siano opportunamente etichettati come eccezioni. Dal solo punto di cura dei dati, questa sarebbe una vera sfida, in particolare per gli sforzi della comunità affamati di risorse.
Il secondo approccio sarebbe quello di applicare filtri che escludano tale contenuto (ad esempio "mano con tre/cinque dita") dalla manifestazione al momento del rendering, più o meno nello stesso modo in cui OpenAI ha, in una certa misura, filtrato GPT-3 e DALL-MI2, in modo che il loro output possa essere regolato senza dover riaddestrare i modelli di origine.

Per Stable Diffusion, la distinzione semantica tra dita e persino arti può diventare orribilmente confusa, ricordando il filone "body horror" dei film horror degli anni '1980 di autori come David Cronenberg. Fonte: https://old.reddit.com/r/StableDiffusion/comments/x6htf6/a_study_of_stable_diffusions_strange_relationship/
Tuttavia, ancora una volta, ciò richiederebbe etichette che potrebbero non esistere in tutte le immagini interessate, lasciandoci con la stessa sfida logistica e di budget.
Si potrebbe sostenere che ci siano ancora due strade da percorrere: analizzare il problema con più dati e applicare sistemi interpretativi di terze parti che possano intervenire quando all'utente finale vengono presentati errori fisici del tipo descritto qui (come minimo, quest'ultima strada fornirebbe a OpenAI un metodo per fornire rimborsi per rendering "body horror", se l'azienda fosse motivata a farlo).
3: personalizzazione
Una delle possibilità più entusiasmanti per il futuro di Stable Diffusion è la prospettiva che utenti o organizzazioni sviluppino sistemi rivisti; modifiche che consentono di integrare nel sistema i contenuti al di fuori della sfera LAION preformata, idealmente senza la spesa ingovernabile di addestrare di nuovo l'intero modello, o il rischio comportato dall'addestrare un grande volume di nuove immagini a un esistente, maturo e capace modello.
Per analogia: se due studenti meno dotati si uniscono a una classe avanzata di trenta studenti, o si assimileranno e recupereranno, oppure saranno bocciati; in entrambi i casi, la media delle prestazioni della classe probabilmente non ne risentirà. Se si uniscono 15 studenti meno dotati, tuttavia, la curva dei voti dell'intera classe rischia di risentirne.
Allo stesso modo, la rete sinergica e abbastanza delicata di relazioni che si costruisce su un addestramento prolungato e costoso del modello può essere compromessa, in alcuni casi effettivamente distrutta, da un numero eccessivo di nuovi dati, abbassando la qualità dell'output per il modello su tutta la linea.
Il motivo principale per cui si fa questo è che il tuo interesse risiede nel dirottare completamente la comprensione concettuale delle relazioni e delle cose del modello e nell'appropriartene per la produzione esclusiva di contenuti simili al materiale aggiuntivo che hai aggiunto.
Quindi, la formazione di 500,000 Simpson frame in un punto di controllo di diffusione stabile esistente è probabile, alla fine, per ottenere una migliore Simpson simulatore di quanto avrebbe potuto offrire la build originale, presumendo che relazioni semantiche sufficientemente ampie sopravvivano al processo (ad es Homer Simpson che mangia un hot dog, che potrebbe richiedere materiale sugli hot dog che non era nel tuo materiale aggiuntivo, ma che esisteva già nel checkpoint), e presumendo che tu non voglia passare improvvisamente da Simpson contenuto alla creazione paesaggio favoloso di Greg Rutkowski – perché l'attenzione del tuo modello post-addestrato è stata enormemente distratta e non sarà più bravo a fare quel genere di cose come prima.
Un esempio notevole di questo è waifu-diffusione, che ha avuto successo 56,000 immagini anime post-addestrate in un checkpoint di diffusione stabile completato e addestrato. È una prospettiva ardua per un hobbista, tuttavia, poiché il modello richiede un minimo di 30 GB di VRAM, ben oltre quanto probabilmente sarà disponibile nella fascia consumer nelle prossime versioni della serie 40XX di NVIDIA.

L'addestramento di contenuti personalizzati in Stable Diffusion tramite waifu-diffusion: il modello ha impiegato due settimane di post-addestramento per produrre questo livello di illustrazione. Le sei immagini a sinistra mostrano l'avanzamento del modello, con il procedere dell'addestramento, nel creare un output coerente per soggetto basato sui nuovi dati di addestramento. Fonte: https://gigazine.net/gsc_news/en/20220121-how-waifu-labs-create/
Si potrebbero investire molti sforzi su tali "fork" di checkpoint di diffusione stabile, solo per poi essere ostacolati dal debito tecnico. Gli sviluppatori del Discord ufficiale hanno già indicato che le versioni successive dei checkpoint non saranno necessariamente retrocompatibili, anche con una logica di prompt che potrebbe aver funzionato con una versione precedente, poiché il loro interesse principale è ottenere il miglior modello possibile, piuttosto che supportare applicazioni e processi legacy.
Pertanto, un'azienda o un individuo che decide di trasformare un checkpoint in un prodotto commerciale non ha di fatto modo di tornare indietro; la sua versione del modello è, a quel punto, un "hard fork" e non sarà in grado di trarre vantaggi a monte dalle versioni successive di stability.ai, il che rappresenta un impegno notevole.
L'attuale e maggiore speranza per la personalizzazione di Stable Diffusion è Inversione testuale, dove l'utente si allena in una piccola manciata di CLIPimmagini allineate.

Una collaborazione tra l'Università di Tel Aviv e NVIDIA, l'inversione testuale consente l'addestramento di entità discrete e nuove, senza distruggere le capacità del modello di origine. Fonte: https://textual-inversion.github.io/
La principale limitazione apparente dell'inversione testuale è che si consiglia un numero molto basso di immagini, solo cinque. Ciò produce effettivamente un'entità limitata che può essere più utile per le attività di trasferimento dello stile piuttosto che per l'inserimento di oggetti fotorealistici.
Tuttavia, sono attualmente in corso esperimenti all'interno dei vari Discord di diffusione stabile che utilizzano un numero molto più elevato di immagini di addestramento, e resta da vedere quanto produttivo potrebbe rivelarsi il metodo. Ancora una volta, la tecnica richiede una grande quantità di VRAM, tempo e pazienza.
A causa di questi fattori limitanti, potremmo dover aspettare un po' per vedere alcuni degli esperimenti di inversione testuale più sofisticati degli appassionati di Stable Diffusion, e per vedere se questo approccio può "metterti in gioco" in un modo che sia più bello di un copia e incolla di Photoshop, pur mantenendo la sorprendente funzionalità dei checkpoint ufficiali.
Pubblicato per la prima volta il 6 settembre 2022.











