
Intelligenza Artificiale
Guida all'autoattenzione: miglioramento della qualità del campione dei modelli di diffusione

I modelli di diffusione del denoising sono strutture di intelligenza artificiale generativa che sintetizzano le immagini dal rumore attraverso un processo iterativo di denoising. Sono celebrati per le loro eccezionali capacità e diversità nella generazione di immagini, in gran parte attribuite ai metodi di guida condizionali al testo o alla classe, inclusa la guida al classificatore e la guida senza classificatore. Questi modelli hanno avuto notevole successo nella creazione di immagini diverse e di alta qualità. Studi recenti hanno dimostrato che le tecniche di guida come le didascalie e le etichette svolgono un ruolo cruciale nel migliorare la qualità delle immagini generate da questi modelli.
Tuttavia, i modelli di diffusione e i metodi di guida incontrano limitazioni in determinate condizioni esterne. Il metodo Classifier-Free Guidance (CFG), che utilizza l'eliminazione delle etichette, aggiunge complessità al processo di formazione, mentre il metodo Classifier Guidance (CG) richiede ulteriore formazione sul classificatore. Entrambi i metodi sono in qualche modo vincolati dalla loro dipendenza da condizioni esterne duramente conquistate, che ne limitano il potenziale e li confinano in contesti condizionati.
Per affrontare queste limitazioni, gli sviluppatori hanno formulato un approccio più generale alla guida alla diffusione, noto come Self-Attention Guidance (SAG). Questo metodo sfrutta le informazioni provenienti da campioni intermedi di modelli di diffusione per generare immagini. Esploreremo SAG in questo articolo, discutendone il funzionamento, la metodologia e i risultati rispetto agli attuali framework e pipeline all'avanguardia.
Guida all'autoattenzione: miglioramento della qualità del campione dei modelli di diffusione
I modelli di diffusione del rumore (DDM) hanno guadagnato popolarità per la loro capacità di creare immagini dal rumore attraverso un processo iterativo di rimozione del rumore. L'abilità di sintesi delle immagini di questi modelli è in gran parte dovuta ai metodi di guida alla diffusione utilizzati. Nonostante i loro punti di forza, i modelli di diffusione e i metodi basati su linee guida devono affrontare sfide come maggiore complessità e maggiori costi computazionali.
Per superare le attuali limitazioni, gli sviluppatori hanno introdotto il metodo Self-Attention Guidance, una formulazione più generale della guida alla diffusione che non si basa sulle informazioni esterne provenienti dalla guida alla diffusione, facilitando così un approccio flessibile e senza condizioni per guidare. quadri di diffusione. L’approccio scelto dalla Self-Attention Guidance aiuta in definitiva a migliorare l’applicabilità dei tradizionali metodi di guida alla diffusione a casi con o senza requisiti esterni.
La guida all’autoattenzione si basa sul semplice principio della formulazione generalizzata e sul presupposto che anche le informazioni interne contenute nei campioni intermedi possano servire da guida. Sulla base di questo principio, il metodo SAG introduce innanzitutto la Blur Guidance, una soluzione semplice e diretta per migliorare la qualità del campione. La guida alla sfocatura mira a sfruttare le proprietà benigne della sfocatura gaussiana per rimuovere i dettagli su piccola scala in modo naturale guidando i campioni intermedi utilizzando le informazioni eliminate come risultato della sfocatura gaussiana. Sebbene il metodo della guida Blur migliori la qualità del campione con una scala guida moderata, non riesce a replicare i risultati su una scala guida ampia poiché spesso introduce ambiguità strutturale in intere regioni. Di conseguenza, il metodo di guida Sfocatura trova difficile allineare l'input originale con la previsione dell'input degradato. Per migliorare la stabilità e l'efficacia del metodo di guida Blur su una scala di guida più ampia, la Guida all'autoattenzione tenta di sfruttare il meccanismo di autoattenzione dei modelli di diffusione poiché i moderni modelli di diffusione contengono già un meccanismo di autoattenzione all'interno della loro architettura.
Partendo dal presupposto che l'autoattenzione è essenziale per catturare le informazioni salienti al suo interno, il metodo Self-Attention Guidance utilizza mappe di autoattenzione dei modelli di diffusione per offuscare in modo contraddittorio le regioni contenenti informazioni salienti e, nel processo, guida il modelli di diffusione con le informazioni residue richieste. Il metodo sfrutta quindi le mappe di attenzione durante il processo inverso dei modelli di diffusione, per aumentare la qualità delle immagini e utilizza l’autocondizionamento per ridurre gli artefatti senza richiedere formazione aggiuntiva o informazioni esterne.

In sintesi, il metodo Self-Attention Guidance
- È un approccio innovativo che utilizza mappe interne di autoattenzione delle strutture di diffusione per migliorare la qualità dell'immagine campione generata senza richiedere alcuna formazione aggiuntiva o fare affidamento su condizioni esterne.
- Il metodo SAG tenta di generalizzare i metodi di guida condizionale in un metodo privo di condizioni che può essere integrato con qualsiasi modello di diffusione senza richiedere risorse aggiuntive o condizioni esterne, migliorando così l’applicabilità dei quadri basati sulla guida.
- Il metodo SAG tenta inoltre di dimostrare le sue capacità ortogonali ai metodi e ai framework condizionali esistenti, facilitando così un aumento delle prestazioni facilitando l'integrazione flessibile con altri metodi e modelli.
Andando avanti, il metodo di guida all’autoattenzione apprende dai risultati di strutture correlate tra cui modelli di diffusione di denoising, guida al campionamento, metodi di autoattenzione dell’intelligenza artificiale generativa e rappresentazioni interne dei modelli di diffusione. Tuttavia, nella sua essenza, il metodo di guida all’autoattenzione implementa gli apprendimenti dai modelli probabilistici di diffusione del DDPM o denoising, dalla guida al classificatore, dalla guida senza classificatore e dai quadri di autoattenzione in diffusione. Ne parleremo in modo approfondito nella prossima sezione.
Guida all'autoattenzione: preliminari, metodologia e architettura
Modello probabilistico di diffusione del denoising o DDPM
DDPM o Modello probabilistico di diffusione denoising è un modello che utilizza un processo iterativo di rimozione del rumore per recuperare un'immagine dal rumore bianco. Tradizionalmente, un modello DDPM riceve un'immagine di input e una pianificazione della varianza in una fase temporale per ottenere l'immagine utilizzando un processo in avanti noto come processo Markoviano.
Classificatore e guida senza classificatore con implementazione GAN
GAN o Generative Adversarial Networks possiedono una diversità commerciale unica per la fedeltà e per portare questa capacità dei framework GAN ai modelli di diffusione, il framework Self-Attention Guidance propone di utilizzare un metodo di guida del classificatore che utilizza un classificatore aggiuntivo. Al contrario, un metodo di guida senza classificatore può essere implementato anche senza l’uso di un classificatore aggiuntivo per ottenere gli stessi risultati. Sebbene il metodo fornisca i risultati desiderati, non è ancora computazionalmente fattibile in quanto richiede etichette aggiuntive e limita inoltre il quadro a modelli di diffusione condizionale che richiedono condizioni aggiuntive come un testo o una classe insieme a ulteriori dettagli di formazione che aumentano la complessità del metodo. il modello.
Generalizzare la guida alla diffusione
Sebbene i metodi Classifier e Classifier-free Guidance forniscano i risultati desiderati e aiutino con la generazione condizionale nei modelli di diffusione, dipendono da input aggiuntivi. Per ogni dato passo temporale, l'input per un modello di diffusione comprende una condizione generalizzata e un campione perturbato senza la condizione generalizzata. Inoltre, la condizione generalizzata comprende informazioni interne al campione perturbato o una condizione esterna, o anche entrambe. La guida risultante è formulata con l'utilizzo di un regressore immaginario con il presupposto che possa prevedere la condizione generalizzata.
Migliorare la qualità dell'immagine utilizzando le mappe dell'autoattenzione
La Guida alla Diffusione Generalizzata implica che sia possibile fornire una guida al processo inverso dei modelli di diffusione estraendo informazioni salienti nella condizione generalizzata contenuta nel campione perturbato. Basandosi su ciò, il metodo Self-Attention Guidance cattura efficacemente le informazioni salienti per i processi inversi, limitando al tempo stesso i rischi che sorgono a seguito di problemi di fuori distribuzione nei modelli di diffusione pre-addestrati.
Guida alla sfocatura
La guida alla sfocatura nella Guida all'attenzione personale si basa sulla sfocatura gaussiana, un metodo di filtraggio lineare in cui il segnale di ingresso viene convoluto con un filtro gaussiano per generare un output. Con un aumento della deviazione standard, la sfocatura gaussiana riduce i dettagli su scala fine all'interno dei segnali di ingresso e produce segnali di ingresso localmente indistinguibili livellandoli verso la costante. Inoltre, gli esperimenti hanno indicato uno squilibrio di informazioni tra il segnale di ingresso e il segnale di uscita della sfocatura gaussiana in cui il segnale di uscita contiene informazioni su scala più fine.
Sulla base di questo apprendimento, il framework Self-Attention Guidance introduce la Blur guidance, una tecnica che esclude intenzionalmente le informazioni dalle ricostruzioni intermedie durante il processo di diffusione e, invece, utilizza queste informazioni per guidare le sue previsioni verso l'aumento della rilevanza delle immagini per il contesto. inserire informazioni. La guida alla sfocatura essenzialmente fa sì che la previsione originale si discosti maggiormente dalla previsione dell'input sfocato. Inoltre, la proprietà benigna della sfocatura gaussiana impedisce ai segnali di uscita di deviare significativamente dal segnale originale con una deviazione moderata. In parole semplici, la sfocatura si verifica naturalmente nelle immagini, il che rende la sfocatura gaussiana un metodo più adatto da applicare a modelli di diffusione pre-addestrati.
Nella pipeline di guida all'autoattenzione, il segnale di ingresso viene prima offuscato utilizzando un filtro gaussiano, quindi viene diffuso con rumore aggiuntivo per produrre il segnale di uscita. In questo modo, la pipeline SAG mitiga l'effetto collaterale della sfocatura risultante che riduce il rumore gaussiano e fa sì che la guida si basi sul contenuto anziché dipendere dal rumore casuale. Sebbene la guida alla sfocatura fornisca risultati soddisfacenti su strutture con scala di guida moderata, non riesce a replicare i risultati sui modelli esistenti con una scala di guida ampia poiché tende a produrre risultati rumorosi, come dimostrato nell'immagine seguente.

Questi risultati potrebbero essere il risultato dell’ambiguità strutturale introdotta nel quadro dalla sfocatura globale che rende difficile per la pipeline SAG allineare le previsioni dell’input originale con l’input degradato, con conseguenti output rumorosi.
Meccanismo di auto-attenzione
Come accennato in precedenza, i modelli di diffusione di solito hanno una componente di auto-attenzione incorporata, ed è una delle componenti più essenziali in una struttura di modello di diffusione. Il meccanismo di Self-Attenzione è implementato al centro dei modelli di diffusione e consente al modello di prestare attenzione alle parti salienti dell'input durante il processo generativo, come dimostrato nell'immagine seguente con maschere ad alta frequenza nella riga superiore, e maschere di autoattenzione nella riga inferiore delle immagini infine generate.

Il metodo proposto di Self-Attention Guidance si basa sullo stesso principio e sfrutta le capacità delle mappe di auto-attenzione nei modelli di diffusione. Nel complesso, il metodo di guida all'autoattenzione offusca le patch autogestite nel segnale di ingresso o, in parole semplici, nasconde le informazioni delle patch a cui prestano attenzione i modelli di diffusione. Inoltre, i segnali di output nella Guida all’autoattenzione contengono regioni intatte dei segnali di input, il che significa che non risulta in un’ambiguità strutturale degli input e risolve il problema della sfocatura globale. La pipeline ottiene quindi le mappe di autoattenzione aggregate conducendo GAP o Global Average Pooling per aggregare le mappe di autoattenzione alla dimensione e sovracampionando il vicino più vicino per corrispondere alla risoluzione del segnale di ingresso.
Guida all'autoattenzione: esperimenti e risultati
Per valutarne le prestazioni, la pipeline Self-Attention Guidance viene campionata utilizzando 8 GPU Nvidia GeForce RTX 3090 ed è basata su IDDPM, ADM e Strutture di diffusione stabile.
Generazione incondizionata con guida all'attenzione di sé
Per misurare l'efficacia della pipeline SAG su modelli incondizionati e dimostrare la proprietà senza condizioni non posseduta da Classifier Guidance e dall'approccio Classifier Free Guidance, la pipeline SAG viene eseguita su framework pre-addestrati incondizionatamente su 50mila campioni.

Come si può osservare, l'implementazione della pipeline SAG migliora le metriche FID, sFID e IS dell'input incondizionato riducendo allo stesso tempo il valore di richiamo. Inoltre, i miglioramenti qualitativi derivanti dall'implementazione della pipeline SAG sono evidenti nelle seguenti immagini in cui le immagini in alto sono i risultati dei framework ADM e Stable Diffusion mentre le immagini in basso sono i risultati dei framework ADM e Stable Diffusion con il Conduttura SAG.


Generazione condizionale con SAG
L'integrazione della pipeline SAG nei framework esistenti offre risultati eccezionali nella generazione incondizionata e la pipeline SAG è in grado di garantire l'agnosticità delle condizioni che consente di implementare la pipeline SAG anche per la generazione condizionale.
Diffusione stabile con guida all’autoattenzione
Anche se il framework Stable Diffusion originale genera immagini di alta qualità, l'integrazione del framework Stable Diffusion con la pipeline Self-Attention Guidance può migliorare drasticamente i risultati. Per valutarne l'effetto, gli sviluppatori utilizzano prompt vuoti per la diffusione stabile con seme casuale per ciascuna coppia di immagini e utilizzano la valutazione umana su 500 coppie di immagini con e senza guida all'attenzione di sé. I risultati sono mostrati nell'immagine seguente.

Inoltre, l’implementazione di SAG può migliorare le capacità del framework di diffusione stabile poiché la fusione della guida senza classificatore con la guida all’attenzione personale può ampliare la gamma dei modelli di diffusione stabile alla sintesi da testo a immagine. Inoltre, le immagini generate dal modello di diffusione stabile con guida all'autoattenzione sono di qualità superiore con minori artefatti grazie all'effetto autocondizionante della pipeline SAG, come dimostrato nell'immagine seguente.

Limitazioni attuali
Sebbene l’implementazione della pipeline di Self-Attention Guidance possa migliorare sostanzialmente la qualità delle immagini generate, presenta alcune limitazioni.
Uno dei limiti principali è l'ortogonalità con Classifier-Guidance e Classifier-Free Guidance. Come si può osservare nell'immagine seguente, l'implementazione di SAG migliora il punteggio FID e il punteggio di previsione, il che significa che la pipeline SAG contiene un componente ortogonale che può essere utilizzato simultaneamente con i metodi di guida tradizionali.

Tuttavia, richiede ancora che i modelli di diffusione siano addestrati in modo specifico, il che aumenta la complessità e i costi computazionali.
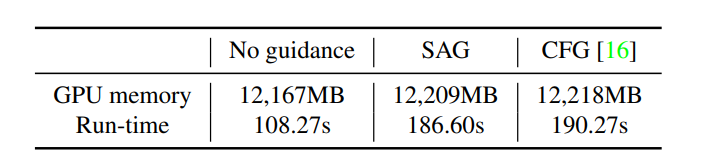
Inoltre, l'implementazione della Self-Attention Guidance non aumenta il consumo di memoria o di tempo, indicando che il sovraccarico derivante da operazioni come mascheramento e sfocatura in SAG è trascurabile. Tuttavia, aumenta ancora i costi computazionali in quanto include un passaggio aggiuntivo rispetto agli approcci senza guida.
Considerazioni finali
In questo articolo abbiamo parlato della Self-Attention Guidance, una formulazione innovativa e generale del metodo di orientamento che utilizza le informazioni interne disponibili all'interno dei modelli di diffusione per generare immagini di alta qualità. La guida all’autoattenzione si basa sul semplice principio della formulazione generalizzata e sul presupposto che anche le informazioni interne contenute nei campioni intermedi possano servire da guida. La pipeline di guida all'autoattenzione è un approccio senza condizioni e senza formazione che può essere implementato in vari modelli di diffusione e utilizza l'autocondizionamento per ridurre gli artefatti nelle immagini generate e aumentare la qualità complessiva.















