Intelligenza Artificiale
GPT-4o di OpenAI: il modello di intelligenza artificiale multimodale che trasforma l'interazione uomo-macchina

OpenAI ha rilasciato il suo modello linguistico più recente e più avanzato: GPT-4o, noto anche come "Omni" modello. Questo rivoluzionario sistema di intelligenza artificiale rappresenta un enorme passo avanti, con capacità che offuscano il confine tra intelligenza umana e artificiale.
Al centro di GPT-4o c'è la sua natura multimodale nativa, che gli consente di elaborare e generare contenuti senza problemi attraverso testo, audio, immagini e video. Questa integrazione di più modalità in un unico modello è la prima nel suo genere e promette di rimodellare il modo in cui interagiamo con gli assistenti IA.
Ma GPT-4o è molto più di un semplice sistema multimodale. Vanta un incredibile miglioramento delle prestazioni rispetto al suo predecessore, GPT-4, e lascia nella polvere i modelli concorrenti come Gemini 1.5 Pro, Claude 3 e Llama 3-70B. Andiamo più a fondo in ciò che rende questo modello di intelligenza artificiale davvero rivoluzionario.
Prestazioni ed efficienza impareggiabili
Uno degli aspetti più impressionanti di GPT-4o sono le sue capacità prestazionali senza precedenti. Secondo le valutazioni di OpenAI, il modello ha un notevole vantaggio di 60 punti Elo rispetto al precedente top performer, GPT-4 Turbo. Questo vantaggio significativo colloca GPT-4o in una lega a sé stante, superando anche i modelli di intelligenza artificiale più avanzati attualmente disponibili.
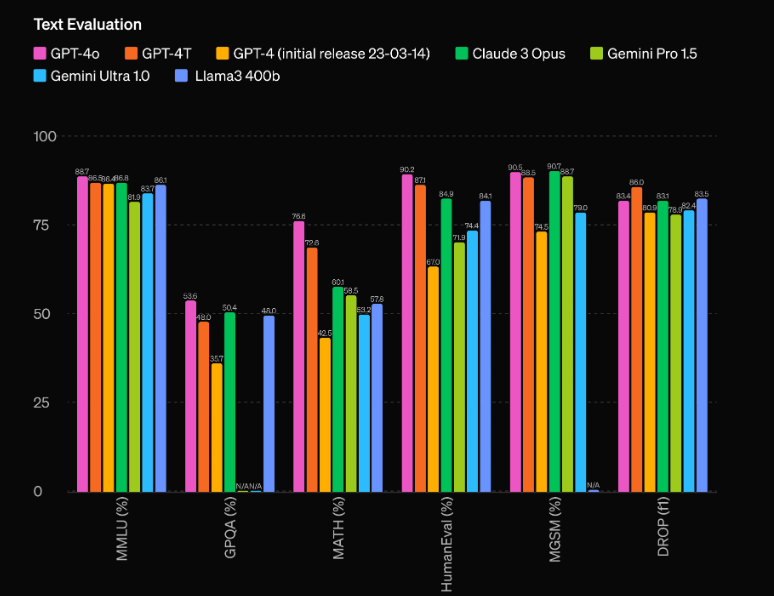
Ma le prestazioni grezze non sono l'unica area in cui GPT-4o brilla. Il modello vanta anche un’efficienza impressionante, funzionando al doppio della velocità di GPT-4 Turbo e costando solo la metà. Questa combinazione di prestazioni superiori e convenienza rende GPT-4o una proposta estremamente interessante per gli sviluppatori e le aziende che desiderano integrare funzionalità IA all'avanguardia nelle loro applicazioni.
Funzionalità multimodali: fusione di testo, audio e visione
Forse l'aspetto più innovativo di GPT-4o è la sua natura multimodale nativa, che gli consente di elaborare e generare contenuti senza soluzione di continuità in più modalità, inclusi testo, audio e visione. Questa integrazione di più modalità in un unico modello è la prima nel suo genere e promette di rivoluzionare il modo in cui interagiamo con gli assistenti IA.
Con GPT-4o, gli utenti possono impegnarsi in conversazioni naturali e in tempo reale utilizzando il parlato, con il modello che riconosce e risponde istantaneamente agli input audio. Ma le funzionalità non si fermano qui: GPT-4o può anche interpretare e generare contenuti visivi, aprendo un mondo di possibilità per applicazioni che vanno dall'analisi e generazione di immagini alla comprensione e creazione di video.
Una delle dimostrazioni più impressionanti delle capacità multimodali di GPT-4o è la sua capacità di analizzare una scena o un'immagine in tempo reale, descrivendo e interpretando accuratamente gli elementi visivi che percepisce. Questa caratteristica ha profonde implicazioni per applicazioni come le tecnologie assistive per i non vedenti, nonché in campi come la sicurezza, la sorveglianza e l’automazione.
Ma le capacità multimodali di GPT-4o vanno oltre la semplice comprensione e generazione di contenuti attraverso diverse modalità. Il modello può anche fondere perfettamente queste modalità, creando esperienze davvero coinvolgenti e coinvolgenti. Ad esempio, durante la demo live di OpenAI, GPT-4o è stato in grado di generare una canzone in base alle condizioni di input, fondendo la sua comprensione del linguaggio, della teoria musicale e della generazione audio in un output coeso e impressionante.
Utilizzando GPT0 utilizzando Python
import openai
# Replace with your actual API key
OPENAI_API_KEY = "your_openai_api_key_here"
# Function to extract the response content
def get_response_content(response_dict, exclude_tokens=None):
if exclude_tokens is None:
exclude_tokens = []
if response_dict and response_dict.get("choices") and len(response_dict["choices"]) > 0:
content = response_dict["choices"][0]["message"]["content"].strip()
if content:
for token in exclude_tokens:
content = content.replace(token, '')
return content
raise ValueError(f"Unable to resolve response: {response_dict}")
# Asynchronous function to send a request to the OpenAI chat API
async def send_openai_chat_request(prompt, model_name, temperature=0.0):
openai.api_key = OPENAI_API_KEY
message = {"role": "user", "content": prompt}
response = await openai.ChatCompletion.acreate(
model=model_name,
messages=[message],
temperature=temperature,
)
return get_response_content(response)
# Example usage
async def main():
prompt = "Hello!"
model_name = "gpt-4o-2024-05-13"
response = await send_openai_chat_request(prompt, model_name)
print(response)
if __name__ == "__main__":
import asyncio
asyncio.run(main())
Io ho:
- Importato direttamente il modulo openai invece di utilizzare una classe personalizzata.
- Rinominata la funzione openai_chat_resolve in get_response_content e apportate alcune piccole modifiche alla sua implementazione.
- Sostituita la classe AsyncOpenAI con la funzione openai.ChatCompletion.acreate, che è il metodo asincrono ufficiale fornito dalla libreria OpenAI Python.
- Aggiunta una funzione principale di esempio che dimostra come utilizzare la funzione send_openai_chat_request.
Tieni presente che devi sostituire "your_openai_api_key_here" con la tua chiave API OpenAI effettiva affinché il codice funzioni correttamente.


















