Intelligenza artificiale
MIT: Misurazione del Bias dei Media nei Principali Canali di Notizie con Machine Learning

Uno studio del MIT ha utilizzato tecniche di machine learning per identificare la formulazione distorta in circa 100 dei più grandi e influenti canali di notizie negli Stati Uniti e oltre, compresi 83 delle più influenti pubblicazioni stampa. Si tratta di uno sforzo di ricerca che mostra la strada verso sistemi automatizzati che potrebbero potenzialmente auto-classificare il carattere politico di una pubblicazione e dare ai lettori una comprensione più profonda della posizione etica di un canale su argomenti di cui potrebbero essere appassionati.
Il lavoro si concentra sul modo in cui gli argomenti sono trattati con una formulazione particolare, come ad esempio immigrato irregolare | immigrato illegale, feto | bambino non nato, dimostanti | anarchici.
Il progetto ha utilizzato tecniche di Natural Language Processing (NLP) per estrarre e classificare tali istanze di ‘linguaggio carico’ (sulla base dell’assunzione che anche i termini apparentemente più ‘neutri’ rappresentano una posizione politica) in una mappa ampia che rivela il bias di sinistra e destra in oltre tre milioni di articoli da circa 100 canali di notizie, risultando in una mappa navigabile del paesaggio del bias delle pubblicazioni in questione.
Il documento proviene da Samantha D’Alonzo e Max Tegmark del Dipartimento di Fisica del MIT e osserva che una serie di iniziative recenti su ‘fact checking’, a seguito di numerosi scandali di ‘fake news’, possono essere interpretate come disoneste e servire gli interessi di particolari gruppi. Il progetto è destinato a fornire un approccio più basato sui dati per lo studio dell’uso del bias e del ‘linguaggio di influenza’ in un contesto di notizie suppostamente neutrale.

Uno spettro di (letteralmente) frasi da sinistra a destra, come derivato dallo studio. Fonte: https://arxiv.org/pdf/2109.00024.pdf
Elaborazione NLP
I dati di origine dello studio sono stati ottenuti dal database open source Newspaper3K e comprendevano 3.078.624 articoli ottenuti da 100 fonti di notizie, comprese 83 pubblicazioni stampa. I giornali sono stati selezionati in base alla loro portata, mentre le fonti di notizie online includevano articoli dal sito di analisi delle notizie militari Defense One e Science.

Le fonti utilizzate nello studio.
Il documento riporta che il testo scaricato è stato ‘minimamente’ pre-elaborato. Le citazioni dirette sono state eliminate, poiché lo studio è interessato al linguaggio scelto dai giornalisti (anche se la selezione delle citazioni è di per sé un campo di studio interessante).
Le spellings britanniche sono state cambiate in americane per standardizzare il database, tutta la punteggiatura è stata rimossa e tutti i numeri ordinali sono stati rimossi. La capitalizzazione iniziale delle frasi è stata convertita in minuscolo, ma tutta l’altra capitalizzazione è stata mantenuta.
Le prime 100.000 frasi più comuni sono state identificate e infine classificate, purgate e fuse in una lista di frasi. Tutti i linguaggi ridondanti che potevano essere identificati (come ‘Condividi questo articolo’ e ‘articolo ripubblicato’) sono stati eliminati. Le variazioni tra frasi essenzialmente identiche (ad esempio ‘big tech’ e ‘Big Tech’, ‘cybersecurity’ e ‘cyber security’) sono state standardizzate.
‘Nutpicking’
Il test iniziale è stato sull’argomento ‘Black lives matter’ e ha potuto discernere il bias di frase e i sinonimi valenti attraverso i dati.
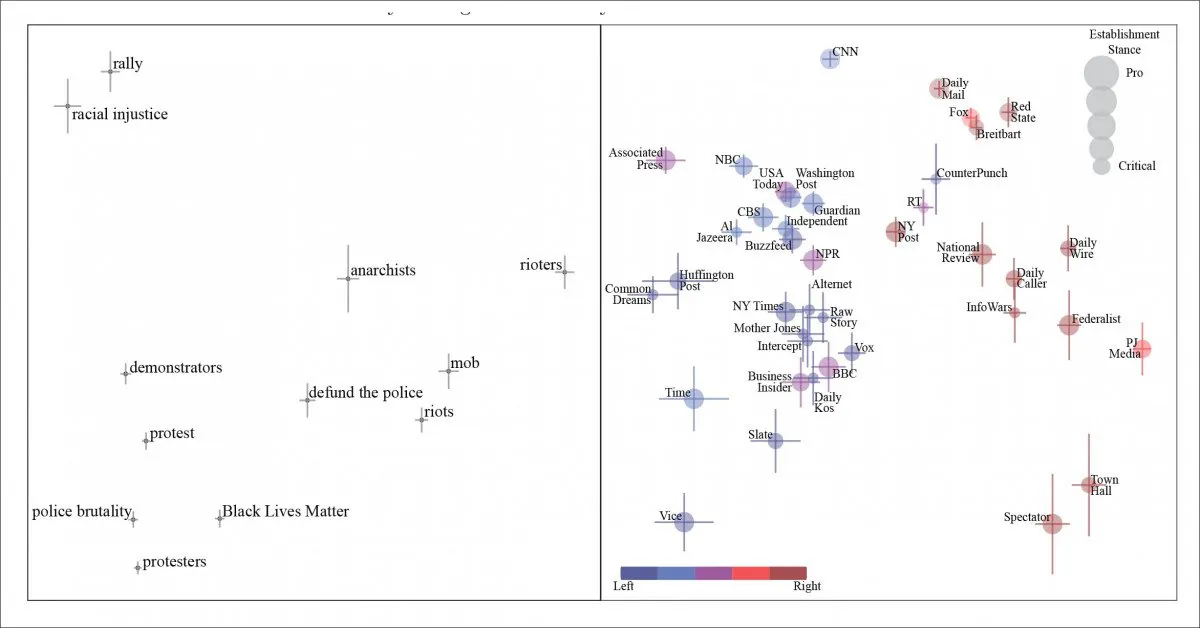
Componenti principali generalizzati per articoli su Black Lives Matter (BLM). Vediamo le persone che partecipano all’azione civile caratterizzate, letteralmente e figurativamente da sinistra a destra, come dimostranti, anarchici e, all’estremità destra dello spettro, come ‘teppisti’. I giornali che originano la frase sono rappresentati nel pannello di destra.
Mentre ‘protestanti’ transitano da ‘anarchici’ a ‘teppisti’ man mano che ci spostiamo lungo la posizione politica del canale in questione, il documento nota che l’estrazione e l’analisi NLP sono ostacolate dalla pratica di ‘nutpicking’ – dove un canale di notizie citerà una frase che è considerata valida da un segmento politico diverso della società e può (apparentemente) fare affidamento sul fatto che i suoi lettori vedano la frase in modo negativo. Il documento cita ‘defund the police’ come esempio di questo.
Naturalmente, ciò significa che una frase ‘di sinistra’ appare in un contesto altrimenti di destra e rappresenta una sfida insolita per un sistema NLP che si affida a frasi codificate per agire come indicatori di posizioni politiche.
Tali frasi sono ‘bi-valenti’ [SIC], mentre certe altre frasi hanno una connotazione negativa così universale (ad esempio ‘infanticidio’) che sono sempre rappresentate come negative in un’ampia gamma di canali.
La ricerca rivela anche mapping simili per argomenti ‘caldi’ come l’aborto, la censura tecnologica, l’immigrazione negli Stati Uniti e il controllo delle armi.
Hobby Horses
Ci sono alcune posizioni politiche controversie nei canali di notizie che non si dividono in modo prevedibile in questo modo, come l’argomento della spesa militare. Il documento ha scoperto che ‘di sinistra’ CNN è finito accanto al National Review e Fox News di destra su questo argomento.
In generale, tuttavia, la posizione politica può essere determinata da altre frasi, come la preferenza per la frase ‘complesso militare-industriale’ rispetto al più di destra ‘industria della difesa’. I risultati mostrano che il primo è utilizzato da canali critici dell’establishment come Canary e American Conservative, mentre il secondo è utilizzato più spesso da Fox e CNN.
La ricerca stabilisce diverse altre progressioni da linguaggio critico dell’establishment a linguaggio pro-establishment, tra cui il passaggio da ‘ucciso’ a ‘l’uccisione di’; ‘detenuti condannati’ a ‘persone carcerate’; e ‘produttori di petrolio’ a ‘big oil’.

Sinonimi valenti con bias dell’establishment, dall’alto in basso.
La ricerca riconosce che i canali possono ‘allontanarsi’ dalla loro posizione politica di base, sia a livello linguistico (come l’uso di frasi bi-valenti), o per vari altri motivi. Ad esempio, la venerabile pubblicazione di destra del Regno Unito The Spectator, fondata nel 1828, presenta frequentemente e in modo prominente articoli di sinistra che si contrappongono al flusso politico generale del suo contenuto – se ciò sia fatto per un senso di imparzialità o per inflammare periodicamente i suoi lettori di base in tempeste di commenti generatrici di traffico è una questione di congettura – e non è un caso facile per un sistema di machine learning che cerca token chiari e coerenti.
Questi particolari ‘hobby horses’ e l’uso ambiguo di ‘punti di vista scomodi’ tra i singoli canali di notizie confondono leggermente la mappa sinistra-destra che la ricerca offre infine, fornendo tuttavia un’indicazione generale dell’affiliazione politica.

Significato Trattenuto
Sebbene datato 2 settembre e pubblicato alla fine di agosto 2021, il documento ha guadagnato relativamente poca attenzione. In parte ciò potrebbe essere dovuto al fatto che la ricerca critica rivolta ai media mainstream è improbabile essere ricevuta con entusiasmo da essi; ma potrebbe anche essere dovuto alla riluttanza degli autori a produrre grafici chiari e inequivocabili che stratificano dove le pubblicazioni dei media influenti e potenti stanno su vari argomenti, insieme a valori aggregati che indicano la misura in cui una pubblicazione si inclina a sinistra o a destra. In effetti, gli autori sembrano prendersi cura di attenuare l’effetto potenzialmente incendiario dei risultati.
Allo stesso modo, i dati estensivi pubblicati del progetto mostrano i conteggi di frequenza di incidenti di parole, ma sembrano essere anonimizzati, rendendo difficile ottenere una chiara immagine del bias dei media attraverso le pubblicazioni studiate. Senza operativizzare il progetto in qualche modo, ciò lascia solo gli esempi selezionati presentati nel documento.
Studi futuri di questo tipo sarebbero probabilmente più utili se considerassero non solo la formulazione utilizzata per gli argomenti, ma anche se l’argomento è stato coperto affatto, poiché il silenzio parla a voce alta, e ha in sé un carattere politico distinto che spesso parla di più di semplici limitazioni di budget o altri fattori pragmatici che possono informare la selezione delle notizie.
Tuttavia, lo studio del MIT sembra essere il più grande del suo tipo fino ad ora e potrebbe costituire la base per futuri sistemi di classificazione e persino tecnologie secondarie come plug-in del browser che potrebbero avvertire i lettori casuali del colore politico della pubblicazione che stanno attualmente leggendo.
Bolle, Bias e Contraccolpo
Inoltre, dovrebbe essere considerato se tali sistemi ulteriormente aggraverebbero una delle questioni più controverse degli algoritmi di raccomandazione – la tendenza a portare un utente in ambienti in cui non vedono mai un punto di vista contrastante o sfidante, che probabilmente ulteriormente rafforzerà la posizione dell’utente su questioni chiave.
Se una tale bolla di contenuto sia un ‘ambiente sicuro’, un ostacolo alla crescita intellettuale o una protezione contro la propaganda parziale, è un giudizio di valore – una questione filosofica che è difficile affrontare dal punto di vista meccanicistico e statistico dei sistemi di machine learning.
Inoltre, proprio come lo studio del MIT ha preso le distanze per lasciare che i dati definiscano i risultati, la classificazione del valore politico delle frasi è inevitabilmente anche un tipo di giudizio di valore, e uno che non può facilmente resistere alla capacità del linguaggio di ricodificare contenuti tossici o controversi in nuove frasi che non sono nel manuale, nelle regole del forum o nel database di training.
Se una codificazione di questo tipo dovesse diventare incorporata in sistemi online popolari, sembra probabile che uno sforzo continuo per mappare la temperatura etica e politica dei principali canali di notizie potrebbe svilupparsi in una guerra fredda tra la capacità dell’AI di discernere il bias e la capacità dei publisher di esprimere la loro posizione in un idioma in evoluzione progettato per superare costantemente la comprensione dell’AI dei semantici.
14/09/21 – 1.41 GMT+2 – Cambiato ‘100 giornali’ in ‘100 canali di notizie’
4:58pm – Corretto la citazione del documento per includere Samantha D’Alonzo, e relative correzioni.












