
Intelligenza Artificiale
DALL-E 2 sta solo "incollando le cose insieme" senza capire le loro relazioni?

Un nuovo documento di ricerca dell'Università di Harvard suggerisce che DALL-E 2, il framework text-to-image che cattura i titoli dei titoli di OpenAI, ha notevoli difficoltà nel riprodurre anche le relazioni a livello infantile tra gli elementi che compone in foto sintetizzate, nonostante l'abbagliante raffinatezza di gran parte di la sua uscita.
I ricercatori hanno intrapreso uno studio sugli utenti coinvolgendo 169 partecipanti in crowdsourcing, a cui sono state presentate immagini DALL-E 2 basate sui principi umani più basilari della semantica delle relazioni, insieme ai prompt di testo che le avevano create. Quando è stato chiesto se i prompt e le immagini fossero correlati, meno del 22% delle immagini è stato percepito come pertinente ai prompt associati, in termini di relazioni molto semplici che a DALL-E 2 è stato chiesto di visualizzare.

Uno screenshot delle sperimentazioni condotte per il nuovo giornale. I partecipanti avevano il compito di selezionare tutte le immagini che corrispondevano al prompt. Nonostante il disclaimer in fondo all'interfaccia, in tutti i casi le immagini, all'insaputa dei partecipanti, sono state infatti generate dal prompt associato visualizzato. Fonte: https://arxiv.org/pdf/2208.00005.pdf
I risultati suggeriscono anche che l'apparente capacità di DALL-E di unire elementi disparati potrebbe diminuire man mano che è meno probabile che tali elementi si siano verificati nei dati di addestramento del mondo reale che alimentano il sistema.
Ad esempio, le immagini per il prompt "bambino che tocca una ciotola" hanno ottenuto un tasso di concordanza dell'87% (ovvero i partecipanti hanno cliccato sulla maggior parte delle immagini come pertinenti al prompt), mentre i rendering fotorealistici simili di "una scimmia che tocca un'iguana" hanno raggiunto solo l'11% concorda:


DALL-E fatica a rappresentare l'improbabile evento di una "scimmia che tocca un'iguana", probabilmente perché è raro, più probabilmente inesistente, nel set di addestramento.
Nel secondo esempio, DALL-E 2 spesso sbaglia la scala e persino la specie, presumibilmente a causa della scarsità di immagini del mondo reale che descrivono questo evento. Al contrario, è ragionevole aspettarsi un numero elevato di foto di formazione relative ai bambini e al cibo e che questo sottodominio/classe sia ben sviluppato.
La difficoltà di DALL-E nel giustapporre elementi dell'immagine fortemente contrastanti suggerisce che il pubblico è attualmente così abbagliato dalle capacità fotorealistiche e ampiamente interpretative del sistema da non aver sviluppato un occhio critico per i casi in cui il sistema ha effettivamente semplicemente "incollato" un elemento su un altro , come in questi esempi dal sito ufficiale di DALL-E 2:

Sintesi taglia e incolla, dagli esempi ufficiali per DALL-E 2. Fonte: https://openai.com/dall-e-2/
Il nuovo documento afferma*:
'La comprensione relazionale è una componente fondamentale dell'intelligenza umana, che si manifesta all'inizio dello sviluppo, e viene calcolato in modo rapido e automatico nella percezione.
La difficoltà di DALL-E 2 anche con le relazioni spaziali di base (come in, on, per) suggerisce che qualunque cosa abbia appreso, non ha ancora appreso i tipi di rappresentazioni che consentono agli esseri umani di strutturare il mondo in modo così flessibile e robusto.
"Un'interpretazione diretta di questa difficoltà è che sistemi come DALL-E 2 non hanno ancora composizionalità relazionale."
Gli autori suggeriscono che i sistemi di generazione di immagini guidate da testo come la serie DALL-E potrebbero trarre vantaggio dallo sfruttamento di algoritmi comuni alla robotica, che modellano identità e relazioni simultaneamente, a causa della necessità per l'agente di interagire effettivamente con l'ambiente piuttosto che semplicemente fabbricare una miscela di elementi diversi.
Uno di questi approcci, intitolato CLIPort, usa lo stesso Meccanismo CLIP che funge da elemento di valutazione della qualità in DALL-E 2:
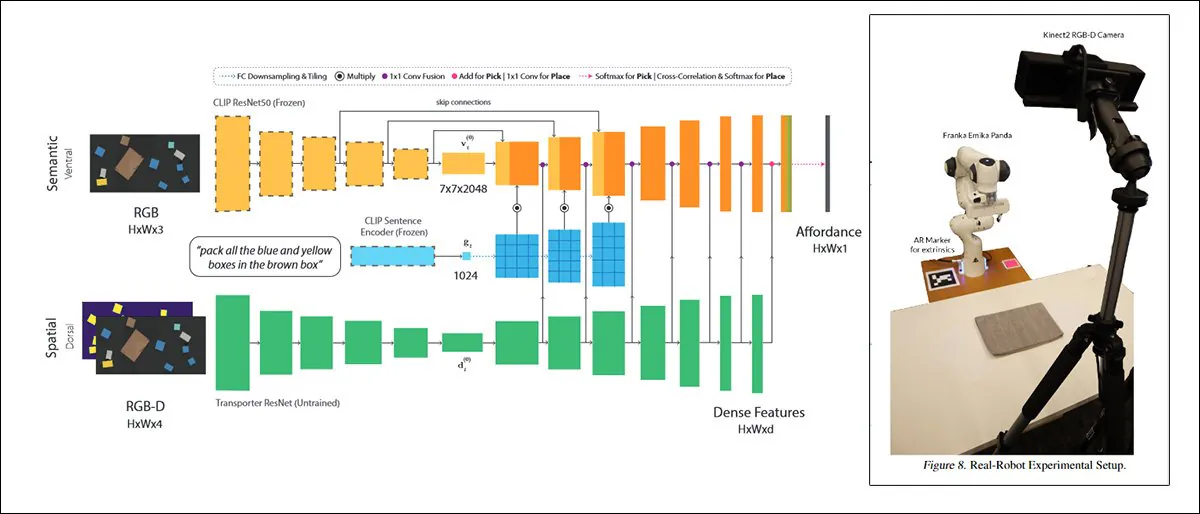
CLIPort, una collaborazione del 2021 tra l'Università di Washington e NVIDIA, utilizza CLIP in un contesto così pratico che i sistemi addestrati su di esso devono necessariamente sviluppare una comprensione delle relazioni fisiche, un motivatore assente in DALL-E 2 e simili "fantastici" quadri di sintesi delle immagini. Fonte: https://arxiv.org/pdf/2109.12098.pdf
Gli autori suggeriscono inoltre che "un altro aggiornamento plausibile" potrebbe essere per l'architettura dei sistemi di sintesi delle immagini come DALL-E da incorporare effetti moltiplicativi in un unico livello di calcolo, consentendo il calcolo delle relazioni in un modo ispirato alle capacità di elaborazione delle informazioni di biologico di riferimento.
La sezione Currents, dedicata a opere audaci e innovative di artisti emergenti e affermati, include la prima statunitense di Mare’s Nest di Ben Rivers, descritto come “un enigmatico road movie ambientato in un mondo post-apocalittico governato da bambini”. Tra gli altri titoli spiccano Dracula di Radu Jude e With Hasan in Gaza di Kamal Aljafari. nuovo documento è intitolato Testare la comprensione relazionale nella generazione di immagini guidate da testo, e proviene da Colin Conwell e Tomer D. Ullman del Dipartimento di Psicologia di Harvard.
Oltre le prime critiche
Commentando il "gioco di prestigio" dietro il realismo e l'integrità dell'output di DALL-E 2, gli autori notano lavori precedenti che hanno riscontrato carenze nei sistemi di immagini generative in stile DALL-E.
Nel giugno di quest'anno, UoC Berkeley noto la difficoltà che DALL-E ha nel gestire i riflessi e le ombre; lo stesso mese, uno studio dalla Corea ha indagato sull '"unicità" e l'originalità dell'output in stile DALL-E 2 con occhio critico; Uno analisi preliminare delle immagini di DALL-E 2, poco dopo il lancio, dalla NYU e dall'Università del Texas, hanno riscontrato vari problemi con la composizionalità e altri fattori essenziali nelle immagini di DALL-E 2; e il mese scorso, un lavoro congiunto tra l'Università dell'Illinois e il MIT ha offerto suggerimenti per miglioramenti architettonici a tali sistemi in termini di composizionalità.
I ricercatori notano inoltre che i luminari DALL-E come Aditya Ramesh hanno concesso i problemi del framework con rilegatura, dimensioni relative, testo e altre sfide.
Anche gli sviluppatori dietro il sistema di sintesi di immagini rivale di Google, Imagen, hanno proposto DrawBench, un nuovo sistema di confronto che misura l'accuratezza dell'immagine attraverso framework con diverse metriche.
Invece, gli autori del nuovo documento suggeriscono che un risultato migliore potrebbe essere ottenuto contrapponendo la stima umana - piuttosto che metriche internecine e algoritmiche - alle immagini risultanti, per stabilire dove risiedono i punti deboli e cosa si potrebbe fare per mitigarli.
Lo studio
A tal fine, il nuovo progetto basa il suo approccio su principi psicologici e cerca di ritirarsi dalla corrente aumento di interesse in ingegneria tempestiva (che è, in effetti, una concessione alle carenze di DALL-E 2, o di qualsiasi sistema simile), per indagare e potenzialmente affrontare le limitazioni che rendono necessarie tali "soluzioni alternative".
Il documento afferma:
'L'attuale lavoro si concentra su un insieme di 15 relazioni di base precedentemente descritte, esaminate o proposte nella letteratura cognitiva, evolutiva o linguistica. L'insieme contiene sia relazioni spaziali radicate (per esempio 'X su Y'), sia relazioni agentiche più astratte (per esempio 'X che aiuta Y').
'I suggerimenti sono intenzionalmente semplici, senza complessità o elaborazione di attributi. Cioè, invece di un suggerimento come "un asino e un polpo stanno giocando". L'asino tiene una corda a un'estremità, il polpo tiene l'altra. L'asino tiene la corda in bocca. Un gatto sta saltando sopra la corda', usiamo 'una scatola su un coltello'.
"La semplicità cattura ancora un'ampia gamma di relazioni provenienti da vari sottodomini della psicologia umana e rende i potenziali fallimenti del modello più sorprendenti e specifici."
Per il loro studio, gli autori hanno reclutato 169 partecipanti da Prolific, tutti situati negli Stati Uniti, con un'età media di 33 anni e il 59% di sesso femminile.
Ai partecipanti sono state mostrate 18 immagini organizzate in una griglia 3×6 con il prompt in alto e un disclaimer in basso che affermava che tutte, alcune o nessuna delle immagini potrebbero essere state generate dal prompt visualizzato, e quindi è stato chiesto di selezionare le immagini che pensavano fossero correlate in questo modo.
Le immagini presentate agli individui erano basate sulla letteratura linguistica, evolutiva e cognitiva, che comprendeva un insieme di otto relazioni fisiche e sette relazioni "agente" (questo diventerà chiaro tra un momento).
Relazioni fisiche
in, su, sotto, coprendo, vicino, occluso da, incombente, e legato a.
Relazioni agenti
spingere, tirare, toccare, colpire, calciare, aiutare, e ostacolare.
Tutte queste relazioni sono state tratte dai campi di studio non CS precedentemente menzionati.
Sono state così derivate dodici entità da utilizzare nei prompt, con sei oggetti e sei agenti:
Oggetti
scatola, cilindro, coperta, scodella, tazza da tè, e coltello.
Agenti
uomo, donna, bambino, robot, scimmia, e iguana.
(I ricercatori ammettono che includere l'iguana, non un pilastro dell'arida ricerca sociologica o psicologica, era "un piacere")
Per ogni relazione, sono stati creati cinque diversi prompt campionando casualmente due entità cinque volte, ottenendo un totale di 75 prompt, ognuno dei quali è stato inviato a DALL-E 2, e per ciascuno dei quali sono state utilizzate le 18 immagini iniziali fornite, senza variazioni o seconde possibilità consentite.
Risultati
Il documento afferma*:
"I partecipanti hanno riportato in media una bassa quantità di concordanza tra le immagini di DALL-E 2 e i prompt utilizzati per generarle, con una media del 22.2% [18.3, 26.6] tra i 75 prompt distinti.
"I prompt agenti, con una media del 28.4% [22.8, 34.2] su 35 prompt, hanno generato un accordo maggiore rispetto ai prompt fisici, con una media del 16.9% [11.9, 23.0] su 40 prompt."

Risultati dello studio. I punti in nero denotano tutti i prompt, con ciascun punto un prompt individuale, e il colore si scompone a seconda che il soggetto del prompt fosse agentico o fisico (cioè un oggetto).
Per confrontare la differenza tra la percezione umana e algoritmica delle immagini, i ricercatori hanno eseguito i loro rendering attraverso l'open source di OpenAI ViT-L/14 Framework basato su CLIP. Facendo la media dei punteggi, hanno trovato una "moderata relazione" tra le due serie di risultati, il che è forse sorprendente, considerando la misura in cui CLIP stesso aiuta a generare le immagini.

Risultati del confronto CLIP (ViT-L/14) rispetto alle risposte umane.
I ricercatori suggeriscono che altri meccanismi all'interno dell'architettura, forse combinati con una preponderanza casuale (o mancanza) di dati nel set di addestramento, possono spiegare il modo in cui CLIP può riconoscere i limiti di DALL-E senza essere in grado, in tutti i casi, di fare qualcosa molto sul problema.
Gli autori concludono che DALL-E 2 ha solo una capacità teorica, se ce n'è, di riprodurre immagini che incorporano la comprensione relazionale, un aspetto fondamentale dell'intelligenza umana che si sviluppa in noi molto presto.
"L'idea che sistemi come DALL-E 2 non abbiano composizionalità può essere una sorpresa per chiunque abbia visto le risposte sorprendentemente ragionevoli di DALL-E 2 a suggerimenti come "un cartone animato di un ravanello baby daikon in tutù che cammina con un barboncino". Prompt come questi spesso generano un'approssimazione ragionevole di un concetto compositivo, con tutte le parti dei prompt presenti e presenti nei posti giusti.
'Composizionalità, tuttavia, non è solo la capacità di incollare insieme le cose, anche cose che potresti non aver mai osservato insieme prima. La composizionalità richiede una comprensione del norme che uniscono le cose. Le relazioni sono tali regole.'
L'uomo morde il T-Rex
Opinione Poiché OpenAI abbraccia a maggior numero di utenti dopo la sua recente monetizzazione beta di DALL-E 2, e poiché ora si deve pagare per la maggior parte delle generazioni, le carenze nella comprensione relazionale di DALL-E 2 potrebbero diventare più evidenti poiché ogni tentativo "fallito" ha un peso finanziario, e i rimborsi non sono disponibili.
Quelli di noi che hanno ricevuto un invito un po' prima hanno avuto tempo (e, fino a poco tempo fa, maggiore svago per giocare con il sistema) per osservare alcuni dei "problemi di relazione" che DALL-E 2 può emettere.
Ad esempio, per a Jurassic Park fan, è molto difficile convincere un dinosauro a inseguire una persona in DALL-E 2, anche se il concetto di "inseguimento" non sembra essere presente in DALL-E 2 sistema di censura, e anche se il lunga storia dei film sui dinosauri dovrebbe fornire abbondanti esempi di addestramento (almeno sotto forma di trailer e riprese pubblicitarie) per questo incontro di specie altrimenti impossibile.

Una tipica risposta di DALL-E 2 al prompt "Una foto a colori di un T-Rex che insegue un uomo lungo una strada". Fonte: DALL-E 2
Ho scoperto che le immagini di cui sopra sono tipiche delle variazioni sul "[dinosauro] che insegue [una persona]" progettazione del prompt e che nessuna quantità di elaborazione nel prompt può indurre il T-Rex a conformarsi effettivamente. Nella prima e nella seconda foto, l'uomo sta (più o meno) inseguendo il T-Rex; nel terzo, avvicinandosi ad esso con un disinvolto disinteresse per la sicurezza; e nell'immagine finale, apparentemente correndo parallelamente alla grande bestia. In circa 10-15 tentativi su questo tema, ho scoperto che anche il dinosauro è "distratto".
Potrebbe essere che gli unici dati di addestramento a cui DALL-E 2 poteva accedere fossero nella linea di 'l'uomo combatte il dinosauro', da scatti pubblicitari per film più vecchi come Un milione di anni a.C (1966), e quello di Jeff Goldblum volo famoso dal re dei predatori è semplicemente un valore anomalo in quella piccola tranche di dati.
* La mia conversione delle citazioni in linea degli autori in collegamenti ipertestuali.
Pubblicato per la prima volta l'4 agosto 2022.











