Intelligenza artificiale
Enfabrica Presenta un Tessuto di Memoria Basato su Ethernet che Potrebbe Ridefinire l’Inferenza AI su Grande Scala
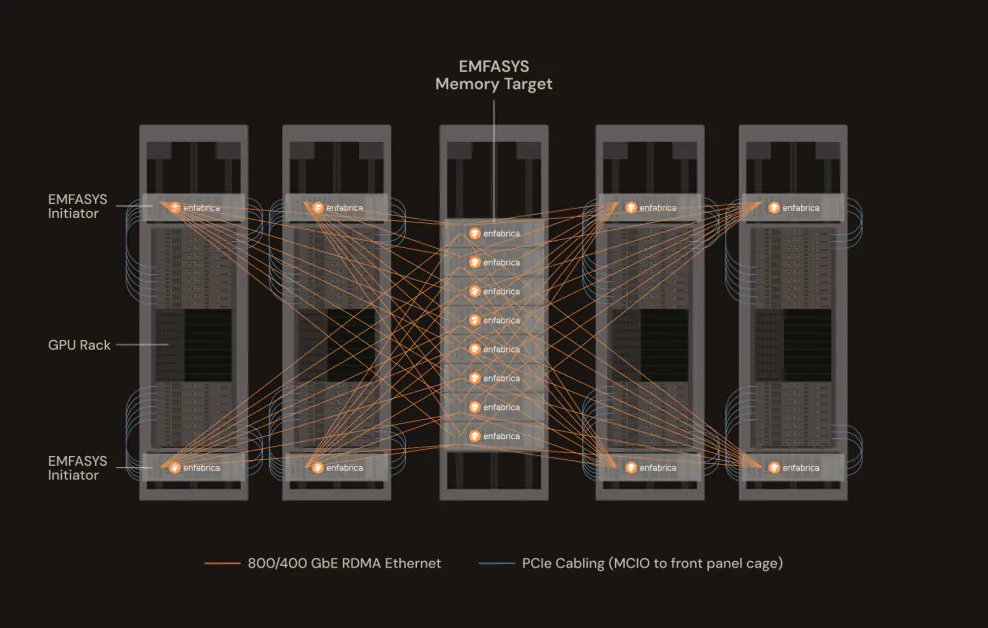
Enfabrica, una startup con sede nella Silicon Valley supportata da Nvidia, ha presentato un prodotto innovativo che potrebbe ridisegnare radicalmente il modo in cui i carichi di lavoro AI su larga scala vengono distribuiti e scalati. Il nuovo sistema di tessuto di memoria elastico (EMFASYS) di Enfabrica è il primo tessuto di memoria basato su Ethernet disponibile commercialmente, progettato specificamente per affrontare il collo di bottiglia fondamentale dell’inferenza AI generativa: l’accesso alla memoria.
In un momento in cui i modelli AI stanno diventando più complessi, consapevoli del contesto e persistenti, richiedendo grandi quantità di memoria per ogni sessione utente, EMFASYS offre un approccio innovativo per scollegare la memoria dal calcolo, consentendo ai data center AI di migliorare drasticamente le prestazioni, ridurre i costi e aumentare l’utilizzo delle risorse più costose: le GPU.
Cosa è un Tessuto di Memoria — e Perché è Importante?
Tradizionalmente, la memoria all’interno dei data center è stata strettamente legata al server o al nodo in cui risiede. Ogni GPU o CPU ha accesso solo alla memoria ad alta larghezza di banda direttamente collegata ad esso — di solito HBM per le GPU o DRAM per le CPU. Questa architettura funziona bene quando i carichi di lavoro sono piccoli e prevedibili. Ma l’AI generativa ha cambiato le regole. I LLM richiedono l’accesso a grandi finestre di contesto, storia utente e memoria multi-agente — tutti elementi che devono essere elaborati rapidamente e senza ritardi. Queste richieste di memoria spesso superano la capacità disponibile della memoria locale, creando collo di bottiglia che bloccano i core GPU e gonfiano i costi dell’infrastruttura.
Un tessuto di memoria risolve questo problema trasformando la memoria in una risorsa condivisa e distribuita — una sorta di pool di memoria collegato in rete accessibile da qualsiasi GPU o CPU nel cluster. Pensalo come creare una “nuvola di memoria” all’interno del rack del data center. Invece di replicare la memoria sui server o sovraccaricare la costosa HBM, un tessuto consente di aggregare, disaggregare e accedere alla memoria su richiesta attraverso una rete ad alta velocità. Ciò consente ai carichi di lavoro di inferenza AI di scalare in modo più efficiente senza essere vincolati dai limiti di memoria fisica di un singolo nodo.
L’Approccio di Enfabrica: Ethernet e CXL, Insieme Finalmente
EMFASYS raggiunge questa architettura di memoria su scala rack combinando due tecnologie potenti: RDMA su Ethernet e Compute Express Link (CXL). Il primo consente il trasferimento di dati ad ultra-bassa latenza e ad alta velocità attraverso reti Ethernet standard. Il secondo consente di staccare la memoria dalle CPU e dalle GPU e di raggrupparla in risorse condivise, accessibili tramite collegamenti CXL ad alta velocità.
Al cuore di EMFASYS c’è il chip ACF-S di Enfabrica, un “SuperNIC” da 3,2 terabit al secondo (Tbps) che fonde il controllo di rete e memoria in un unico dispositivo. Questo chip consente ai server di interfacciarsi con enormi pool di memoria DRAM da 18 terabyte per nodo, distribuiti su tutto il rack. Crucialmente, ciò avviene utilizzando porte Ethernet standard, consentendo agli operatori di sfruttare l’infrastruttura del data center esistente senza investire in interconnessioni proprietarie.
Ciò che rende EMFASYS particolarmente attraente è la sua capacità di scaricare dinamicamente i carichi di lavoro vincolati alla memoria dalle costose HBM collegate alle GPU alle più economiche DRAM, mantenendo allo stesso tempo una latenza di accesso a livello di microsecondo. Lo stack software di EMFASYS include meccanismi di caching e bilanciamento del carico intelligenti che nascondono la latenza e orchestrano il movimento della memoria in modi trasparenti per i LLM in esecuzione sul sistema.
Implicazioni per l’Industria AI
Questo è più di una semplice soluzione hardware intelligente — rappresenta un cambiamento filosofico nel modo in cui l’infrastruttura AI viene costruita e scalata. Mentre l’AI generativa passa dalla novità alla necessità, con miliardi di query utente elaborate quotidianamente, il costo di servire questi modelli è diventato insostenibile per molte aziende. Le GPU sono spesso sottoutilizzate non a causa della mancanza di calcolo, ma perché rimangono inattive in attesa della memoria. EMFASYS affronta direttamente questo squilibrio.
Abilitando la memoria condivisa e collegata in rete accessibile via Ethernet, Enfabrica offre agli operatori dei data center un’alternativa scalabile all’acquisto continuo di altre GPU o HBM. Invece, possono aumentare la capacità di memoria in modo modulare, utilizzando DRAM e networking intelligenti, riducendo l’impronta complessiva e migliorando l’economia dell’inferenza AI.
Le implicazioni vanno oltre i risparmi immediati. Questa architettura disaggregata apre la strada a modelli di memoria come servizio, in cui il contesto, la storia e lo stato dell’agente possono persistere oltre una singola sessione o server, aprendo la porta a sistemi AI più intelligenti e personalizzati. Ciò stabilisce anche le basi per nuvole AI più resilienti, in cui i carichi di lavoro possono essere distribuiti elasticamente su un intero rack o data center senza rigide limitazioni di memoria.
Prospettive Future
Il sistema EMFASYS di Enfabrica è attualmente in fase di campionamento con clienti selezionati, e sebbene l’azienda non abbia divulgato i nomi di questi partner, Reuters riporta che importanti provider di servizi cloud AI stanno già testando il sistema. Ciò posiziona Enfabrica non solo come fornitore di componenti, ma come un attore chiave nella prossima generazione di infrastrutture AI.
Scollegando la memoria dal calcolo e rendendola disponibile su reti Ethernet ad alta velocità e a costo contenuto, Enfabrica sta gettando le basi per una nuova era di architettura AI — un’era in cui l’inferenza può scalare senza compromessi, in cui le risorse non sono più bloccate e in cui l’economia del dispiegamento di grandi modelli linguistici finalmente inizia ad avere senso.
In un mondo sempre più definito da sistemi AI ricchi di contesto e multi-agente, la memoria non è più un attore di supporto — è il palco. E Enfabrica scommette che chi costruisce il miglior palco definirà le prestazioni dell’AI per anni a venire.










