
Intelligenza Artificiale
EfficientViT: trasformatore di visione efficiente in termini di memoria per la visione artificiale ad alta risoluzione

Grazie alla loro elevata capacità, i modelli Vision Transformer hanno riscosso negli ultimi tempi un grande successo. Nonostante le loro prestazioni, i modelli dei trasformatori di visione presentano un grosso difetto: la loro notevole capacità di calcolo comporta costi di calcolo elevati, ed è il motivo per cui i trasformatori di visione non sono la prima scelta per le applicazioni in tempo reale. Per affrontare questo problema, un gruppo di sviluppatori ha lanciato EfficientViT, una famiglia di trasformatori di visione ad alta velocità.
Lavorando su EfficientViT, gli sviluppatori hanno osservato che la velocità dei modelli di trasformatori di corrente è spesso limitata da operazioni di memoria inefficienti, in particolare da funzioni basate sugli elementi e dal rimodellamento dei tensori nella rete MHSA o Multi-Head Self Attention. Per affrontare queste operazioni di memoria inefficienti, gli sviluppatori di EfficientViT hanno lavorato su un nuovo elemento costitutivo utilizzando un layout a sandwich, ovvero il modello EfficientViT fa uso di una singola rete Multi-Head Self Attention legata alla memoria tra strati FFN efficienti che aiuta a migliorare l'efficienza della memoria e migliorando anche la comunicazione complessiva del canale. Inoltre, il modello scopre anche che le mappe dell’attenzione spesso presentano elevate somiglianze tra le teste, il che porta a una ridondanza computazionale. Per affrontare il problema della ridondanza, il modello EfficientViT presenta un modulo di attenzione di gruppo a cascata che alimenta le teste dell'attenzione con diverse suddivisioni della funzionalità completa. Il metodo non solo aiuta a risparmiare sui costi computazionali, ma migliora anche la diversità di attenzione del modello.
Esperimenti completi eseguiti sul modello EfficientViT in diversi scenari indicano che EfficientViT supera i modelli efficienti esistenti per visione computerizzata pur ottenendo un buon compromesso tra precisione e velocità. Facciamo quindi un tuffo più profondo ed esploriamo il modello EfficientViT in modo un po' più approfondito.
Un'introduzione a Vision Transformers ed EfficientViT
I Vision Transformers rimangono uno dei framework più popolari nel settore della visione artificiale perché offrono prestazioni superiori ed elevate capacità computazionali. Tuttavia, con il costante miglioramento della precisione e delle prestazioni dei modelli del trasformatore di visione, aumentano anche i costi operativi e le spese generali di calcolo. Ad esempio, i modelli attuali noti per fornire prestazioni all'avanguardia su set di dati ImageNet come SwinV2 e V-MoE utilizzano rispettivamente parametri 3B e 14.7B. Le dimensioni enormi di questi modelli, insieme ai costi e ai requisiti computazionali, li rendono praticamente inadatti per dispositivi e applicazioni in tempo reale.
Il modello EfficientNet mira a esplorare come aumentare le prestazioni di modelli di trasformatori di visionee l'individuazione dei principi coinvolti nella progettazione di architetture quadro efficienti ed efficaci basate su trasformatori. Il modello EfficientViT si basa su strutture di trasformazione della visione esistenti come Swim e DeiT e analizza tre fattori essenziali che influenzano la velocità di interferenza dei modelli, tra cui la ridondanza del calcolo, l'accesso alla memoria e l'utilizzo dei parametri. Inoltre, il modello osserva che la velocità dei modelli del trasformatore di visione è legata alla memoria, il che significa che il pieno utilizzo della potenza di calcolo nelle CPU/GPU è impedito o limitato dal ritardo di accesso alla memoria, che si traduce in un impatto negativo sulla velocità di runtime dei trasformatori . Le funzioni a livello di elemento e il rimodellamento del tensore nella rete MHSA o Multi-Head Self Attention sono le operazioni più inefficienti in termini di memoria. Il modello osserva inoltre che la regolazione ottimale del rapporto tra FFN (rete feed forward) e MHSA può aiutare a ridurre significativamente il tempo di accesso alla memoria senza influire sulle prestazioni. Tuttavia, il modello osserva anche una certa ridondanza nelle mappe dell'attenzione come risultato della tendenza della testa dell'attenzione ad apprendere proiezioni lineari simili.
Il modello è un'elaborazione finale dei risultati ottenuti durante il lavoro di ricerca per EfficientViT. Il modello presenta un nuovo nero con un layout a sandwich che applica un singolo strato MHSA legato alla memoria tra gli strati Feed Forward Network o FFN. L'approccio non solo riduce il tempo necessario per eseguire operazioni legate alla memoria in MHSA, ma rende anche l'intero processo più efficiente in termini di memoria consentendo a più livelli FFN di facilitare la comunicazione tra canali diversi. Il modello si avvale anche di un nuovo modulo CGA o Cascaded Group Attention che mira a rendere i calcoli più efficaci riducendo la ridondanza computazionale non solo nelle teste di attenzione, ma aumenta anche la profondità della rete con conseguente elevata capacità del modello. Infine, il modello espande la larghezza del canale dei componenti essenziali della rete, comprese le proiezioni di valore, riducendo al contempo i componenti della rete con basso valore come le dimensioni nascoste nelle reti feed forward per ridistribuire i parametri nel quadro.

Come si può vedere nell'immagine sopra, il framework EfficientViT funziona meglio degli attuali modelli CNN e ViT all'avanguardia in termini sia di precisione che di velocità. Ma come è riuscito il framework EfficientViT a sovraperformare alcuni dei framework attualmente all’avanguardia? Scopriamolo.
EfficientViT: migliorare l'efficienza dei trasformatori di visione
Il modello EfficientViT mira a migliorare l'efficienza dei modelli esistenti di trasformatori di visione utilizzando tre prospettive,
- Ridondanza computazionale.
- Accesso alla memoria.
- Utilizzo dei parametri.
Il modello mira a scoprire in che modo i parametri di cui sopra influenzano l'efficienza dei modelli di trasformatori di visione e come risolverli per ottenere risultati migliori con una migliore efficienza. Parliamo di loro in modo un po' più approfondito.
Accesso alla memoria ed efficienza
Uno dei fattori essenziali che influenzano la velocità di un modello è il sovraccarico di accesso alla memoria o MAO. Come si può vedere nell'immagine seguente, diversi operatori nel trasformatore, tra cui l'addizione degli elementi, la normalizzazione e il rimodellamento frequente, sono operazioni inefficienti in termini di memoria, poiché richiedono l'accesso a diverse unità di memoria, il che è un processo che richiede tempo.
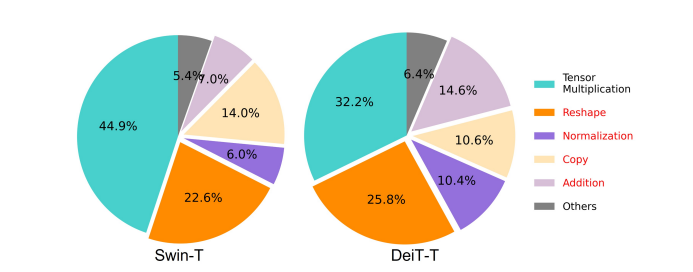
Sebbene esistano alcuni metodi che possono semplificare i calcoli standard dell'attenzione personale softmax come l'approssimazione di basso rango e l'attenzione scarsa, spesso offrono un'accelerazione limitata e degradano la precisione.
D'altra parte, il framework EfficientViT mira a ridurre i costi di accesso alla memoria riducendo la quantità di livelli inefficienti di memoria nel framework. Il modello riduce DeiT-T e Swin-T a piccole sottoreti con un throughput di interferenza più elevato di 1.25X e 1.5X e confronta le prestazioni di queste sottoreti con le proporzioni degli strati MHSA. Come si può vedere nell'immagine qui sotto, una volta implementato, l'approccio aumenta la precisione degli strati MHSA di circa il 20-40%.

Efficienza di calcolo
Gli strati MHSA tendono a incorporare la sequenza di input in più sottospazi o teste e calcolano le mappe di attenzione individualmente, un approccio noto per aumentare le prestazioni. Tuttavia, le mappe dell’attenzione non sono computazionalmente economiche e, per esplorarne i costi computazionali, il modello EfficientViT esplora come ridurre l’attenzione ridondante nei modelli ViT più piccoli. Il modello misura la massima somiglianza del coseno di ciascuna testa e delle restanti teste all'interno di ciascun blocco addestrando i modelli DeiT-T e Swim-T ridotti in larghezza con un'accelerazione dell'inferenza di 1.25×. Come si può osservare nell'immagine seguente, esiste un elevato numero di somiglianze tra le teste di attenzione, il che suggerisce che il modello comporta una ridondanza di calcolo perché numerose teste tendono ad apprendere proiezioni simili dell'esatta caratteristica completa.

Per incoraggiare le teste ad apprendere modelli diversi, il modello applica esplicitamente una soluzione intuitiva in cui a ciascuna testa viene alimentata solo una parte dell'intera funzionalità, una tecnica che ricorda l'idea della convoluzione di gruppo. Il modello addestra diversi aspetti dei modelli ridotti che presentano livelli MHSA modificati.
Efficienza dei parametri
I modelli ViT medi ereditano le loro strategie di progettazione come l'utilizzo di una larghezza equivalente per le proiezioni, l'impostazione del rapporto di espansione su 4 in FFN e l'aumento del sovraccarico sugli stadi dai trasformatori NLP. Le configurazioni di questi componenti devono essere riprogettate attentamente per i moduli leggeri. Il modello EfficientViT implementa la potatura strutturata Taylor per trovare automaticamente i componenti essenziali nei livelli Swim-T e DeiT-T ed esplora ulteriormente i principi di allocazione dei parametri sottostanti. Con determinati vincoli di risorse, i metodi di potatura rimuovono i canali non importanti e mantengono quelli critici per garantire la massima precisione possibile. La figura seguente confronta il rapporto tra canali e incorporamenti di input prima e dopo l'eliminazione nel framework Swin-T. È stato osservato che: Precisione di base: 79.1%; precisione ridotta: 76.5%.

L'immagine sopra indica che le prime due fasi della struttura preservano più dimensioni, mentre le ultime due fasi preservano molte meno dimensioni. Ciò potrebbe significare che una tipica configurazione di canale che raddoppia il canale dopo ogni fase o utilizza canali equivalenti per tutti i blocchi, potrebbe comportare una sostanziale ridondanza negli ultimi blocchi.
Trasformatore di visione efficiente: architettura
Sulla base degli insegnamenti ottenuti durante l'analisi di cui sopra, gli sviluppatori hanno lavorato alla creazione di un nuovo modello gerarchico che offra elevate velocità di interferenza, il EfficientViT modello. Diamo uno sguardo dettagliato alla struttura del framework EfficientViT. La figura seguente fornisce un'idea generica del quadro EfficientViT.
Gli elementi costitutivi del quadro EfficientViT
L'elemento costitutivo per una rete di trasformatori di visione più efficiente è illustrato nella figura seguente.

Il framework è costituito da un modulo di attenzione di gruppo a cascata, un layout sandwich efficiente in termini di memoria e una strategia di riallocazione dei parametri che si concentra sul miglioramento dell'efficienza del modello in termini rispettivamente di calcolo, memoria e parametri. Parliamo di loro in modo più dettagliato.
Disposizione del panino
Il modello utilizza un nuovo layout sandwich per creare un blocco di memoria più efficace ed efficiente per il framework. Il layout a sandwich utilizza livelli di autoattenzione meno legati alla memoria e fa uso di reti feed forward più efficienti in termini di memoria per la comunicazione dei canali. Per essere più specifici, il modello applica un singolo strato di auto-attenzione per la miscelazione spaziale che è inserito tra gli strati FFN. Il design non solo aiuta a ridurre il consumo di tempo di memoria grazie ai livelli di auto-attenzione, ma consente anche una comunicazione efficace tra diversi canali all'interno della rete grazie all'uso dei livelli FFN. Il modello applica inoltre un ulteriore livello di token di interazione prima di ogni livello di rete feed forward utilizzando DWConv o Convoluzione ingannevole e migliora la capacità del modello introducendo una distorsione induttiva delle informazioni strutturali locali.
Attenzione di gruppo a cascata
Uno dei maggiori problemi con gli strati MHSA è la ridondanza nelle teste di attenzione che rende i calcoli più inefficienti. Per risolvere il problema, il modello propone CGA o Cascaded Group Attention for Vision Transformers, un nuovo modulo di attenzione che prende ispirazione dalle convoluzioni di gruppo nelle CNN efficienti. In questo approccio, il modello alimenta le singole teste con suddivisioni delle caratteristiche complete e quindi scompone esplicitamente il calcolo dell'attenzione tra le teste. Suddividere le funzionalità invece di fornire funzionalità complete a ciascuna testa consente di risparmiare calcolo e rende il processo più efficiente e il modello continua a lavorare per migliorare ulteriormente la precisione e la sua capacità incoraggiando i livelli ad apprendere proiezioni su funzionalità che dispongono di informazioni più ricche.

Riallocazione dei parametri
Per migliorare l'efficienza dei parametri, il modello rialloca i parametri nella rete espandendo la larghezza del canale dei moduli critici e restringendo la larghezza del canale dei moduli non così importanti. Sulla base dell'analisi di Taylor, il modello imposta dimensioni ridotte del canale per le proiezioni in ciascuna testa durante ogni fase oppure consente alle proiezioni di avere la stessa dimensione dell'input. Anche il rapporto di espansione della rete feed forward è stato ridotto a 2 da 4 per facilitare la ridondanza dei parametri. La strategia di riallocazione proposta che il framework EfficientViT implementa, assegna più canali a moduli importanti per consentire loro di apprendere meglio le rappresentazioni in uno spazio ad alta dimensione che minimizza la perdita di informazioni sulle caratteristiche. Inoltre, per accelerare il processo di interferenza e migliorare ulteriormente l'efficienza del modello, il modello rimuove automaticamente i parametri ridondanti nei moduli non importanti.

La panoramica del framework EfficientViT può essere spiegata nell'immagine sopra in cui le parti,
- Architettura di EfficientViT,
- Blocco layout sandwich,
- Attenzione di gruppo a cascata.
EfficientViT: architetture di rete

L'immagine sopra riassume l'architettura di rete del framework EfficientViT. Il modello introduce un incorporamento di patch sovrapposte [20,80] che incorpora patch 16×16 in token di dimensione C1 che migliora la capacità del modello di ottenere risultati migliori nell'apprendimento della rappresentazione visiva di basso livello. L’architettura del modello comprende tre fasi in cui ciascuna fase impila gli elementi costitutivi proposti del quadro EfficientViT e il numero di token su ciascun livello di sottocampionamento (sottocampionamento 2× della risoluzione) è ridotto di 4 volte. Per rendere il sottocampionamento più efficiente, il modello propone un blocco di sottocampione che ha anch'esso il layout sandwich proposto, con l'eccezione che un blocco residuo invertito sostituisce lo strato di attenzione per ridurre la perdita di informazioni durante il campionamento. Inoltre, invece del convenzionale LayerNorm(LN), il modello utilizza BatchNorm(BN) perché BN può essere ripiegato negli strati lineari o convoluzionali precedenti che gli conferiscono un vantaggio di runtime rispetto a LN.
Famiglia di modelli EfficientViT
La famiglia di modelli EfficientViT è composta da 6 modelli con diverse scale di profondità e larghezza e per ogni fase viene assegnato un determinato numero di teste. I modelli utilizzano meno blocchi nelle fasi iniziali rispetto alle fasi finali, un processo simile a quello seguito dal framework MobileNetV3 perché il processo di elaborazione della fase iniziale con risoluzioni più grandi richiede molto tempo. La larghezza viene aumentata nelle fasi con un piccolo fattore per ridurre la ridondanza nelle fasi successive. La tabella allegata di seguito fornisce i dettagli architettonici della famiglia di modelli EfficientViT dove C, L e H si riferiscono a larghezza, profondità e numero di teste nella fase particolare.

EfficientViT: implementazione e risultati del modello
Il modello EfficientViT ha una dimensione batch totale di 2,048, è costruito con Timm e PyTorch, è addestrato da zero per 300 epoche utilizzando 8 GPU Nvidia V100, utilizza uno scheduler della velocità di apprendimento del coseno, un ottimizzatore AdamW e conduce il suo esperimento di classificazione delle immagini su ImageNet -1K. Le immagini in input vengono ritagliate e ridimensionate in modo casuale con una risoluzione di 224×224. Per gli esperimenti che coinvolgono la classificazione delle immagini a valle, il framework EfficientViT ottimizza il modello per 300 epoche e utilizza l'ottimizzatore AdamW con una dimensione batch di 256. Il modello utilizza RetineNet per il rilevamento di oggetti su COCO e procede all'addestramento dei modelli per altre 12 epoche con le stesse impostazioni.
Risultati su ImageNet
Per analizzare le prestazioni di EfficientViT, queste vengono confrontate con gli attuali modelli ViT e CNN sul set di dati ImageNet. I risultati del confronto sono riportati nella figura seguente. Come si può vedere, la famiglia di modelli EfficientViT supera nella maggior parte dei casi le strutture attuali e riesce a raggiungere un compromesso ideale tra velocità e precisione.

Confronto con CNN efficienti e ViT efficienti
Il modello confronta innanzitutto le sue prestazioni con CNN efficienti come EfficientNet e strutture CNN vanilla come MobileNets. Come si può vedere, rispetto ai framework MobileNet, i modelli EfficientViT ottengono un punteggio di precisione top-1 migliore, mentre funzionano rispettivamente 3.0X e 2.5X più velocemente su CPU Intel e GPU V100.
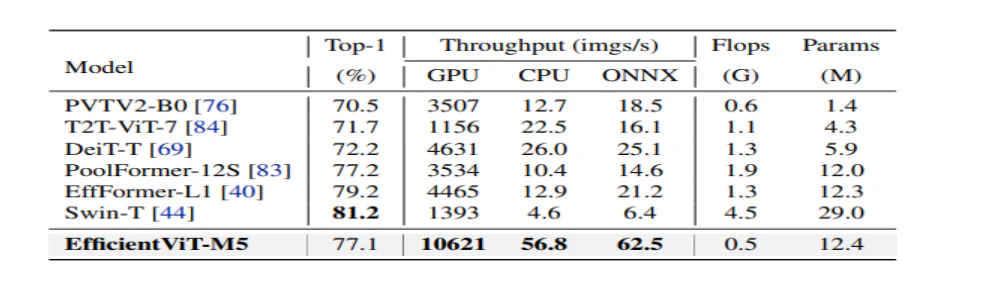
La figura sopra mette a confronto le prestazioni del modello EfficientViT con i modelli ViT su larga scala all'avanguardia eseguiti sul set di dati ImageNet-1K.
Classificazione delle immagini a valle
Il modello EfficientViT viene applicato a varie attività a valle per studiare le capacità di trasferimento di apprendimento del modello e l'immagine seguente riassume i risultati dell'esperimento. Come si può osservare, il modello EfficientViT-M5 riesce a ottenere risultati migliori o simili su tutti i set di dati pur mantenendo un throughput molto più elevato. L’unica eccezione è il set di dati Cars, dove il modello EfficientViT non riesce a fornire risultati accurati.

Rilevazione dell'oggetto
Per analizzare la capacità di EfficientViT di rilevare oggetti, viene confrontata con modelli efficienti sull'attività di rilevamento oggetti COCO e l'immagine seguente riassume i risultati del confronto.

Considerazioni finali
In questo articolo abbiamo parlato di EfficientViT, una famiglia di modelli di trasformatori di visione veloci che utilizzano l'attenzione di gruppo a cascata e forniscono operazioni efficienti in termini di memoria. Esperimenti approfonditi condotti per analizzare le prestazioni di EfficientViT hanno mostrato risultati promettenti poiché il modello EfficientViT supera nella maggior parte dei casi gli attuali modelli CNN e trasformatori di visione. Abbiamo anche cercato di fornire un'analisi sui fattori che giocano un ruolo nell'influenzare la velocità di interferenza dei trasformatori di visione.















