Intelligenza artificiale
Il primo anniversario di ChatGPT: ridisegnare il futuro dell’interazione con l’AI

Riflettendo sul primo anno di ChatGPT, è chiaro che questo strumento ha cambiato significativamente la scena dell’AI. Lanciato alla fine del 2022, ChatGPT si è distinto per il suo stile di conversazione user-friendly, che ha reso l’interazione con l’AI più simile a una chiacchierata con una persona che con una macchina. Questo nuovo approccio ha catturato rapidamente l’attenzione del pubblico. Già cinque giorni dopo il suo rilascio, ChatGPT aveva attirato un milione di utenti. All’inizio del 2023, questo numero era salito a circa 100 milioni di utenti mensili, e ad ottobre, la piattaforma stava registrando circa 1,7 miliardi di visite in tutto il mondo. Questi numeri parlano chiaro della sua popolarità e utilità.
Nell’ultimo anno, gli utenti hanno trovato tutti i modi creativi per utilizzare ChatGPT, dalle attività semplici come scrivere email e aggiornare i curriculum vitae a creare aziende di successo. Ma non si tratta solo di come le persone lo stanno utilizzando; la tecnologia stessa è cresciuta e migliorata. Inizialmente, ChatGPT era un servizio gratuito che offriva risposte testuali dettagliate. Ora, c’è ChatGPT Plus, che include ChatGPT-4. Questa versione aggiornata è stata addestrata su più dati, fornisce meno risposte errate e comprende meglio le istruzioni complesse.
Una delle maggiori aggiornamenti è che ChatGPT può ora interagire in più modi – può ascoltare, parlare e anche elaborare immagini. Ciò significa che puoi parlare con esso attraverso la sua app mobile e mostrargli le foto per ottenere risposte. Questi cambiamenti hanno aperto nuove possibilità per l’AI e hanno cambiato il modo in cui le persone vedono e pensano al ruolo dell’AI nelle nostre vite.
Dai suoi inizi come demo tecnologica al suo status attuale di attore importante nel mondo della tecnologia, il viaggio di ChatGPT è piuttosto impressionante. Inizialmente, era visto come un modo per testare e migliorare la tecnologia attraverso il feedback del pubblico. Ma è rapidamente diventato una parte essenziale del paesaggio dell’AI. Questo successo mostra quanto sia efficace affinare i grandi modelli linguistici (LLM) con l’apprendimento supervisionato e il feedback umano. Di conseguenza, ChatGPT può gestire una vasta gamma di domande e attività.
La corsa per sviluppare i sistemi AI più capaci e versatili ha portato a una proliferazione di modelli sia open-source che proprietari come ChatGPT. Comprendere le loro capacità generali richiede benchmark completi su una vasta gamma di attività. Questa sezione esplora questi benchmark, gettando luce su come i diversi modelli, compreso ChatGPT, si confrontano tra loro.
Valutazione degli LLM: i benchmark
- MT-Bench: questo benchmark testa la capacità di conversazione a più turni e di seguire le istruzioni in otto domini: scrittura, roleplay, estrazione di informazioni, ragionamento, matematica, codifica, conoscenze STEM e scienze umane/sociali. I modelli LLM più forti come GPT-4 vengono utilizzati come valutatori.
- AlpacaEval: basato sul set di valutazione AlpacaFarm, questo valutatore automatico LLM valuta i modelli in base alle risposte dei modelli LLM avanzati come GPT-4 e Claude, calcolando la percentuale di vittoria dei modelli candidati.
- Classifica LLM aperta: utilizzando il Language Model Evaluation Harness, questa classifica valuta gli LLM su sette benchmark chiave, tra cui sfide di ragionamento e test di conoscenza generale, in entrambi i setting zero-shot e few-shot.
- BIG-bench: questo benchmark collaborativo copre oltre 200 nuove attività linguistiche, che spaziano su una vasta gamma di argomenti e lingue. Ha lo scopo di sondare gli LLM e prevedere le loro future capacità.
- ChatEval: un framework di dibattito multi-agente che consente ai team di discutere e valutare autonomamente la qualità delle risposte dei diversi modelli su domande aperte e attività di generazione di linguaggio naturale tradizionali.
Prestazioni comparative
In termini di benchmark generali, gli LLM open-source hanno mostrato notevoli progressi. Llama-2-70B, ad esempio, ha ottenuto risultati impressionanti, in particolare dopo essere stato affinato con dati di istruzione. La sua variante, Llama-2-chat-70B, ha eccelso in AlpacaEval con una percentuale di vittoria del 92,66%, superando GPT-3.5-turbo. Tuttavia, GPT-4 rimane il modello di riferimento con una percentuale di vittoria del 95,28%.
Zephyr-7B, un modello più piccolo, ha dimostrato capacità paragonabili ai modelli LLM più grandi da 70B, in particolare in AlpacaEval e MT-Bench. Nel frattempo, WizardLM-70B, affinato con una vasta gamma di dati di istruzione, ha ottenuto il punteggio più alto tra gli LLM open-source in MT-Bench. Tuttavia, è ancora rimasto indietro rispetto a GPT-3.5-turbo e GPT-4.
Un’interessante novità, GodziLLa2-70B, ha ottenuto un punteggio competitivo nella classifica LLM aperta, mostrando il potenziale dei modelli sperimentali che combinano dataset diversi. Allo stesso modo, Yi-34B, sviluppato da zero, si è distinto con punteggi paragonabili a GPT-3.5-turbo e solo leggermente inferiore a GPT-4.
UltraLlama, con il suo affinamento su dati diversi e di alta qualità, ha eguagliato GPT-3.5-turbo nei suoi benchmark proposti e ha evenuto superato in aree di conoscenza del mondo e professionale.
Scalare verso l’alto: l’ascesa dei giganti LLM
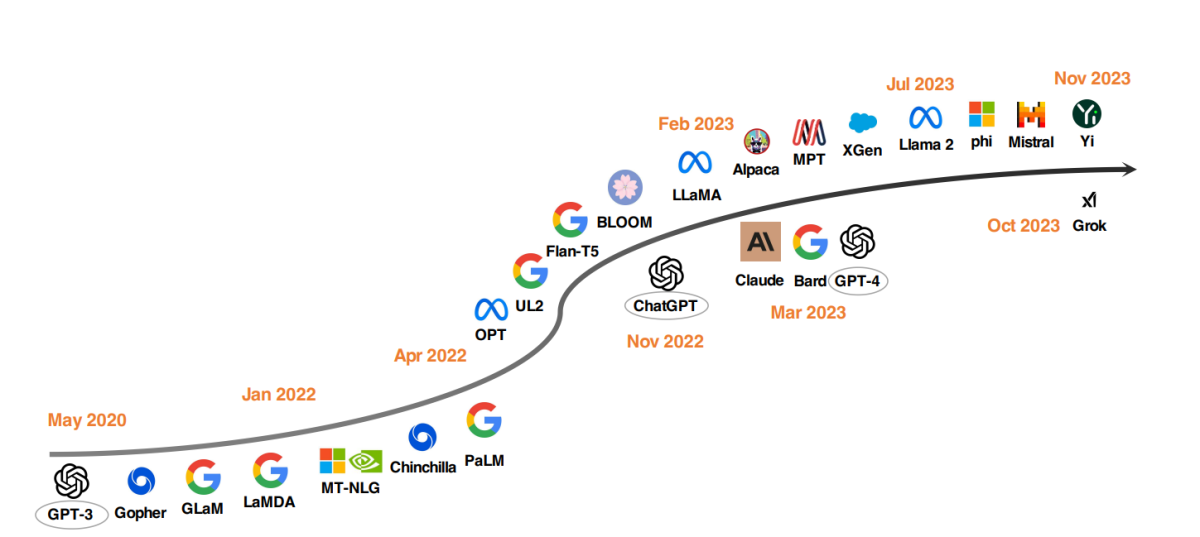
I principali modelli LLM dal 2020
Una tendenza notevole nello sviluppo degli LLM è stata la scalabilità dei parametri del modello. Modelli come Gopher, GLaM, LaMDA, MT-NLG e PaLM hanno spinto i limiti, culminando in modelli con fino a 540 miliardi di parametri. Questi modelli hanno mostrato capacità eccezionali, ma la loro natura chiusa ha limitato la loro applicazione più ampia. Ciò ha suscitato interesse nello sviluppo di LLM open-source, una tendenza che sta guadagnando slancio.
In parallelo con l’aumento delle dimensioni dei modelli, i ricercatori hanno esplorato strategie alternative. Invece di rendere i modelli più grandi, si sono concentrati sul miglioramento dell’addestramento pre-lancio dei modelli più piccoli. Esempi includono Chinchilla e UL2, che hanno dimostrato che più non è sempre meglio; strategie più intelligenti possono produrre risultati efficienti anche così. Inoltre, c’è stato un notevole interesse per l’addestramento delle istruzioni dei modelli linguistici, con progetti come FLAN, T0 e Flan-T5 che hanno apportato contributi significativi in questo settore.
Il catalizzatore ChatGPT
L’introduzione di ChatGPT di OpenAI ha segnato un punto di svolta nella ricerca NLP. Per competere con OpenAI, aziende come Google e Anthropic hanno lanciato i propri modelli, Bard e Claude, rispettivamente. Sebbene questi modelli mostrino prestazioni paragonabili a ChatGPT in molti compiti, sono ancora indietro rispetto all’ultimo modello di OpenAI, GPT-4. Il successo di questi modelli è principalmente attribuito all’apprendimento per rinforzo con feedback umano (RLHF), una tecnica che sta ricevendo una crescente attenzione per ulteriori miglioramenti.
Rumor e speculazioni intorno a Q* (Q-Star) di OpenAI
Recenti rapporti suggeriscono che i ricercatori di OpenAI possano aver raggiunto un notevole progresso nell’AI con lo sviluppo di un nuovo modello chiamato Q* (pronunciato Q stella). Presumibilmente, Q* ha la capacità di eseguire operazioni matematiche di livello scolastico, un risultato che ha scatenato discussioni tra gli esperti sulla sua potenziale importanza come pietra miliare verso l’intelligenza artificiale generale (AGI). Sebbene OpenAI non abbia commentato questi rapporti, le presunte capacità di Q* hanno generato notevole entusiasmo e speculazione sui social media e tra gli appassionati di AI.
Lo sviluppo di Q* è degno di nota perché i modelli linguistici esistenti come ChatGPT e GPT-4, sebbene capaci di alcuni compiti matematici, non sono particolarmente adatti a gestirli in modo affidabile. La sfida risiede nella necessità per i modelli AI di non solo riconoscere pattern, come fanno attualmente attraverso l’apprendimento profondo e i trasformatori, ma anche di ragionare e comprendere concetti astratti. La matematica, essendo un benchmark per il ragionamento, richiede che il modello AI pianifichi ed esegua più passaggi, dimostrando una profonda comprensione dei concetti astratti. Questa capacità segnerebbe un notevole balzo in avanti nelle capacità dell’AI, potenzialmente estendendosi oltre la matematica ad altri compiti complessi.
Tuttavia, gli esperti mettono in guardia contro l’eccessiva enfatizzazione di questo sviluppo. Sebbene un sistema AI in grado di risolvere problemi matematici in modo affidabile sarebbe un risultato impressionante, non segnala necessariamente l’avvento di un’AI superintelligente o AGI. La ricerca AI attuale, compresi gli sforzi di OpenAI, si è concentrata su problemi elementari, con vari gradi di successo in compiti più complessi.
Le potenziali applicazioni di progressi come Q* sono vastissime, andando dalla didattica personalizzata all’assistenza nella ricerca scientifica e nell’ingegneria. Tuttavia, è anche importante gestire le aspettative e riconoscere i limiti e le preoccupazioni di sicurezza associate a tali progressi. Le preoccupazioni sull’AI che rappresenta rischi esistenziali, una preoccupazione fondamentale di OpenAI, rimangono pertinenti, specialmente mentre i sistemi AI iniziano a interfacciarsi maggiormente con il mondo reale.
Il movimento LLM open-source
Per aumentare la ricerca sugli LLM open-source, Meta ha rilasciato la serie di modelli Llama, scatenando un’onda di nuovi sviluppi basati su Llama. Ciò include modelli affinati con dati di istruzione, come Alpaca, Vicuna, Lima e WizardLM. La ricerca si sta anche ramificando nell’ambito del miglioramento delle capacità degli agenti, del ragionamento logico e della modellazione del contesto lungo all’interno del framework Llama.
Inoltre, c’è una crescente tendenza a sviluppare potenti LLM a partire da zero, con progetti come MPT, Falcon, XGen, Phi, Baichuan, Mistral, Grok e Yi. Questi sforzi riflettono un impegno per democratizzare le capacità degli LLM chiusi, rendendo gli strumenti AI avanzati più accessibili e efficienti.
L’impatto di ChatGPT e dei modelli open-source sulla sanità
Stiamo guardando a un futuro in cui gli LLM assisteranno nella stesura di note cliniche, nel compilare moduli per il rimborso e nel sostenere i medici nella diagnosi e nella pianificazione del trattamento. Ciò ha attirato l’attenzione sia delle grandi aziende tecnologiche che delle istituzioni sanitarie.
I colloqui di Microsoft con Epic, un importante fornitore di software per la registrazione elettronica delle cartelle cliniche, segnalano l’integrazione degli LLM nella sanità. Iniziative sono già in corso presso UC San Diego Health e Stanford University Medical Center. Allo stesso modo, le partnership di Google con Mayo Clinic e il lancio di HealthScribe, un servizio di documentazione clinica AI di Amazon Web Services, segnano passi significativi in questa direzione.
Tuttavia, questi rapidi sviluppi sollevano preoccupazioni sul cedere il controllo della medicina agli interessi aziendali. La natura proprietaria di questi LLM rende difficile la loro valutazione. La loro possibile modifica o interruzione per motivi di profitto potrebbe compromettere l’assistenza ai pazienti, la privacy e la sicurezza.
La necessità urgente è quella di un approccio aperto e inclusivo allo sviluppo degli LLM nella sanità. Le istituzioni sanitarie, i ricercatori, i clinici e i pazienti devono collaborare a livello globale per costruire LLM open-source per la sanità. Questo approccio, simile al Trillion Parameter Consortium, consentirebbe di mettere in comune risorse computazionali, finanziarie e di expertise.












