Angolo di Anderson
Un Metodo Forense dei Dati per una Nuova Generazione di Deepfake

Sebbene la creazione di deepfake di individui privati sia diventata una preoccupazione pubblica crescente e viene sempre più vietata in varie regioni, dimostrare che un modello creato dall’utente – come ad esempio uno che consente la vendetta pornografica – sia stato specificamente addestrato su immagini di una persona particolare rimane estremamente difficile.
Per mettere il problema in contesto: un elemento chiave di un attacco deepfake è falsamente affermare che un’immagine o un video ritragga una persona specifica. Semplicemente affermare che qualcuno in un video è l’identità #A, piuttosto che solo un somigliante, è sufficiente per creare danni, e non è necessario utilizzare l’AI in questo scenario.
Tuttavia, se un attaccante genera immagini o video AI utilizzando modelli addestrati sui dati di una persona reale, i sistemi di riconoscimento facciale dei social media e dei motori di ricerca assoceranno automaticamente il contenuto contraffatto alla vittima – senza richiedere nomi nei post o nei metadati. Le immagini generate dall’AI assicurano l’associazione.
Quanto più distintivo è l’aspetto della persona, tanto più inevitabile diventa, fino a quando il contenuto contraffatto appare nelle ricerche di immagini e alla fine raggiunge la vittima.
Faccia a Faccia
Il mezzo più comune di diffusione di modelli focalizzati sull’identità è attualmente la Low-Rank Adaptation (LoRA), in cui l’utente addestra un piccolo numero di immagini per poche ore contro i pesi di un modello di base molto più grande come Stable Diffusion (per immagini statiche, per lo più) o Hunyuan Video, per video deepfake.
I bersagli più comuni delle LoRA, compresa la nuova generazione di LoRA basate su video, sono le celebrità femminili, la cui fama le espone a questo tipo di trattamento con meno critiche pubbliche rispetto al caso di vittime “sconosciute”, a causa dell’assunzione che tali opere derivate siano coperte dal “fair use” (almeno negli Stati Uniti e in Europa).

Le celebrità femminili dominano le liste LoRA e Dreambooth nel portale civit.ai. La LoRA più popolare attualmente ha più di 66.000 download, il che è considerevole, considerando che l’utilizzo di questa AI è ancora visto come un’attività “di nicchia”.
Non esiste un forum pubblico per le vittime non celebrità di deepfaking, che appaiono solo nei media quando si verificano casi di procedimenti giudiziari o quando le vittime parlano in outlet popolari.
Tuttavia, in entrambi gli scenari, i modelli utilizzati per contraffare le identità dei bersagli hanno “distillato” i dati di addestramento così completamente nello spazio latente del modello che è difficile identificare le immagini di origine utilizzate.
Se fosse possibile farlo entro un margine di errore accettabile, ciò consentirebbe di perseguire coloro che condividono le LoRA, poiché non solo dimostra l’intento di contraffare una specifica identità (ad esempio, quella di una persona “sconosciuta”, anche se il malefattore non la nomina durante il processo di diffamazione), ma esporrebbe anche l’uploader a accuse di violazione del copyright, se applicabile.
Quest’ultimo sarebbe utile in giurisdizioni in cui la regolamentazione legale delle tecnologie di deepfaking è carente o in ritardo.
Esposizione Eccessiva
L’obiettivo dell’addestramento di un modello di base, come il modello di base da diversi gigabyte che un utente potrebbe scaricare da Hugging Face, è che il modello diventi ben generalizzato e duttile. Ciò comporta l’addestramento su un numero adeguato di immagini diverse e con impostazioni adeguate, e la fine dell’addestramento prima che il modello “sovraccarichi” i dati.
Un modello sovraccaricato ha visto i dati così tante volte (eccessive) durante il processo di addestramento che tenderà a riprodurre immagini molto simili, esponendo così la fonte dei dati di addestramento.

L’identità ‘Ann Graham Lotz’ può essere quasi perfettamente riprodotta nel modello Stable Diffusion V1.5. La ricostruzione è quasi identica ai dati di addestramento (a sinistra nell’immagine sopra). Fonte: https://arxiv.org/pdf/2301.13188
Tuttavia, i modelli sovraccaricati vengono generalmente scartati dai loro creatori piuttosto che distribuiti, poiché sono comunque inadatti allo scopo. Pertanto, questo è un evento forense improbabile. In ogni caso, il principio si applica più all’addestramento costoso e ad alto volume dei modelli di base, dove molteplici versioni della stessa immagine che sono entrate in un enorme set di dati di origine possono rendere alcune immagini di addestramento facili da invocare (vedi immagine e esempio sopra).
Le cose sono un po’ diverse nel caso dei modelli LoRA e Dreambooth (anche se Dreambooth è caduto in disgrazia a causa delle sue grandi dimensioni dei file). Qui, l’utente seleziona un numero molto limitato di immagini diverse di un soggetto e le utilizza per addestrare una LoRA.

A sinistra, output da un modello LoRA Hunyuan Video. A destra, i dati che hanno reso possibile la somiglianza (immagini utilizzate con il permesso della persona ritratta).
Spesso la LoRA avrà una parola chiave addestrata, come ad esempio [nome della celebrità]. Tuttavia, molto spesso il soggetto addestrato specifico apparirà nel output generato anche senza tali prompt, poiché anche una LoRA ben bilanciata (cioè non sovraccaricata) è un po’ “fissata” sul materiale su cui è stata addestrata e tenderà a includerlo in qualsiasi output.
Questa predisposizione, combinata con il numero limitato di immagini ottimali per un set di dati LoRA, espone il modello all’analisi forense, come vedremo.
Smaskare i Dati
Queste questioni sono affrontate in un nuovo articolo della Danimarca, che offre una metodologia per identificare le immagini di origine (o gruppi di immagini di origine) in un attacco di Membership Inference Attack (MIA) black-box. La tecnica coinvolge almeno in parte l’utilizzo di modelli addestrati su misura progettati per aiutare a esporre i dati di origine generando i propri “deepfake”:

Esempi di immagini ‘false’ generate dal nuovo approccio, a livelli di Classifier-Free Guidance (CFG) sempre crescenti, fino al punto di distruzione. Fonte: https://arxiv.org/pdf/2502.11619
Sebbene il lavoro, intitolato Membership Inference Attacks for Face Images Against Fine-Tuned Latent Diffusion Models, sia un contributo interessante alla letteratura su questo argomento specifico, è anche un articolo inaccessibile e scritto in modo conciso che necessita di una notevole decodifica. Pertanto, copriremo almeno i principi di base dietro il progetto qui e una selezione dei risultati ottenuti.
In effetti, se qualcuno addestra un modello AI sul tuo volto, il metodo degli autori può aiutare a dimostrare ciò cercando segni di memorizzazione nel modello generato.
Nel primo caso, un modello di destinazione viene addestrato su un set di immagini del viso, rendendolo più probabile che riproduca dettagli da quelle immagini nei suoi output. Successivamente, un modello di attacco viene addestrato utilizzando immagini generate dall’AI dal modello di destinazione come “positivi” (sospetti membri del set di addestramento) e altre immagini da un set di dati diverso come “negativi” (non membri).
Imparando le sottili differenze tra questi gruppi, il modello di attacco può prevedere se un’immagine data facesse parte del set di addestramento originale.
L’attacco è più efficace nei casi in cui il modello AI è stato addestrato estensivamente, il che significa che più il modello è specializzato, più è facile rilevare se alcune immagini sono state utilizzate.
Gli autori hanno anche scoperto che l’aggiunta di filigrane visibili alle immagini di addestramento rende la rilevazione ancora più facile – anche se le filigrane nascoste non aiutano molto.
Impressionante, l’approccio è stato testato in un ambiente black-box, il che significa che funziona senza accesso ai dettagli interni del modello, solo ai suoi output.
Il metodo raggiunto è computazionalmente intenso, come gli autori ammettono; tuttavia, il valore di questo lavoro sta nell’indicazione della direzione per ulteriori ricerche e nel dimostrare che i dati possono essere realisticamente estratti entro una tolleranza accettabile; pertanto, data la sua natura seminale, non è necessario che funzioni su uno smartphone a questo stadio.
Metodo/Dati
Questo studio ha utilizzato diversi set di dati del Technical University of Denmark (DTU, l’istituzione ospitante per i tre ricercatori) per addestrare il modello di destinazione e per addestrare e testare il modello di attacco.
I set di dati utilizzati sono stati derivati da DTU Orbit:
DseenDTU Il set di immagini di base.
DDTU Immagini estratte da DTU Orbit.
DseenDTU Una partizione di DDTU utilizzata per addestrare il modello di destinazione.
DunseenDTU Una partizione di DDTU che non è stata utilizzata per addestrare alcun modello di generazione di immagini e che è stata utilizzata per testare o addestrare il modello di attacco.
wmDseenDTU Una partizione di DDTU con filigrane visibili utilizzata per addestrare il modello di destinazione.
hwmDseenDTU Una partizione di DDTU con filigrane nascoste utilizzata per addestrare il modello di destinazione.
DgenDTU Immagini generate da un modello di diffusione latente (LDM) che è stato addestrato sul set di immagini DseenDTU.
I set di dati utilizzati per addestrare il modello di destinazione consistono di coppie di immagini e testo etichettate dal modello di etichettatura BLIP (forse non per coincidenza uno dei modelli più popolari non censurati nella comunità AI casuale).
BLIP è stato impostato per aggiungere la frase ‘a dtu headshot of a’ a ogni descrizione.
Inoltre, sono stati utilizzati diversi set di dati dell’Università di Aalborg (AAU) per i test, tutti derivati dal corpus AU VBN:
DAAU Immagini estratte da AAU vbn.
DseenAAU Una partizione di DAAU utilizzata per addestrare il modello di destinazione.
DunseenAAU Una partizione di DAAU che non è stata utilizzata per addestrare alcun modello di generazione di immagini e che è stata utilizzata per testare o addestrare il modello di attacco.
DgenAAU Immagini generate da un LDM che è stato addestrato sul set di immagini DseenAAU.
Equivalenti ai set precedenti, la frase ‘a aau headshot of a’ è stata utilizzata. Ciò ha garantito che tutte le etichette nel set di dati DTU seguissero il formato ‘a dtu headshot of a (…)’, rafforzando le caratteristiche fondamentali del set di dati durante l’addestramento.
Test
Sono stati condotti diversi esperimenti per valutare come si sono comportati gli attacchi di inferenza di appartenenza contro il modello di destinazione. Ogni test ha mirato a determinare se fosse possibile eseguire un attacco di successo all’interno dello schema mostrato di seguito, dove il modello di destinazione è stato addestrato su un set di immagini che è stato ottenuto senza autorizzazione.

Schema per l’approccio.
Con il modello addestrato richiesto per generare immagini di output, queste immagini sono state utilizzate come esempi positivi per addestrare il modello di attacco, mentre altre immagini non correlate sono state incluse come esempi negativi.
Il modello di attacco è stato addestrato utilizzando l’apprendimento supervisionato e quindi testato su nuove immagini per determinare se fossero state originariamente parte del set di dati utilizzato per addestrare il modello di destinazione. Per valutare l’accuratezza dell’attacco, il 15% dei dati di test è stato messi da parte per la convalida.
Poiché il modello di destinazione è stato addestrato su un set di dati noto, lo stato di appartenenza effettivo di ogni immagine è già stabilito quando si crea il set di dati di addestramento per il modello di attacco. Questo setup controllato consente una valutazione chiara di quanto efficacemente il modello di attacco possa distinguere tra immagini che facevano parte del set di addestramento e quelle che non lo facevano.
Per questi test, è stato utilizzato il modello Stable Diffusion V1.5. Sebbene questo modello piuttosto vecchio appaia spesso nella ricerca a causa della necessità di test consistenti e del vasto corpus di lavori precedenti che lo utilizzano, questo è un uso appropriato; la versione V1.5 è rimasta popolare per la creazione di LoRA nella comunità di hobbyisti di Stable Diffusion per un lungo periodo, nonostante le successive versioni, e anche nonostante l’avvento di Flux – poiché il modello è completamente non censurato.
Il modello di attacco dei ricercatori si basava su Resnet-18, con i pesi pre-addestrati del modello mantenuti. L’ultimo strato di 1000 neuroni di ResNet-18 è stato sostituito con un strato completamente connesso con due neuroni. La perdita di addestramento era categorica cross-entropy, e l’ottimizzatore Adam è stato utilizzato.
Per ogni test, il modello di attacco è stato addestrato cinque volte utilizzando semi casuali diversi per calcolare gli intervalli di confidenza del 95% per le metriche chiave. La classificazione zero-shot con il modello CLIP è stata utilizzata come baseline.
(Si prega di notare che la tabella dei risultati principali originale nel paper è concisa e insolitamente difficile da capire. Pertanto, l’ho riformulata di seguito in un formato più utile all’utente. Si prega di fare clic sull’immagine per vederla in risoluzione più alta)
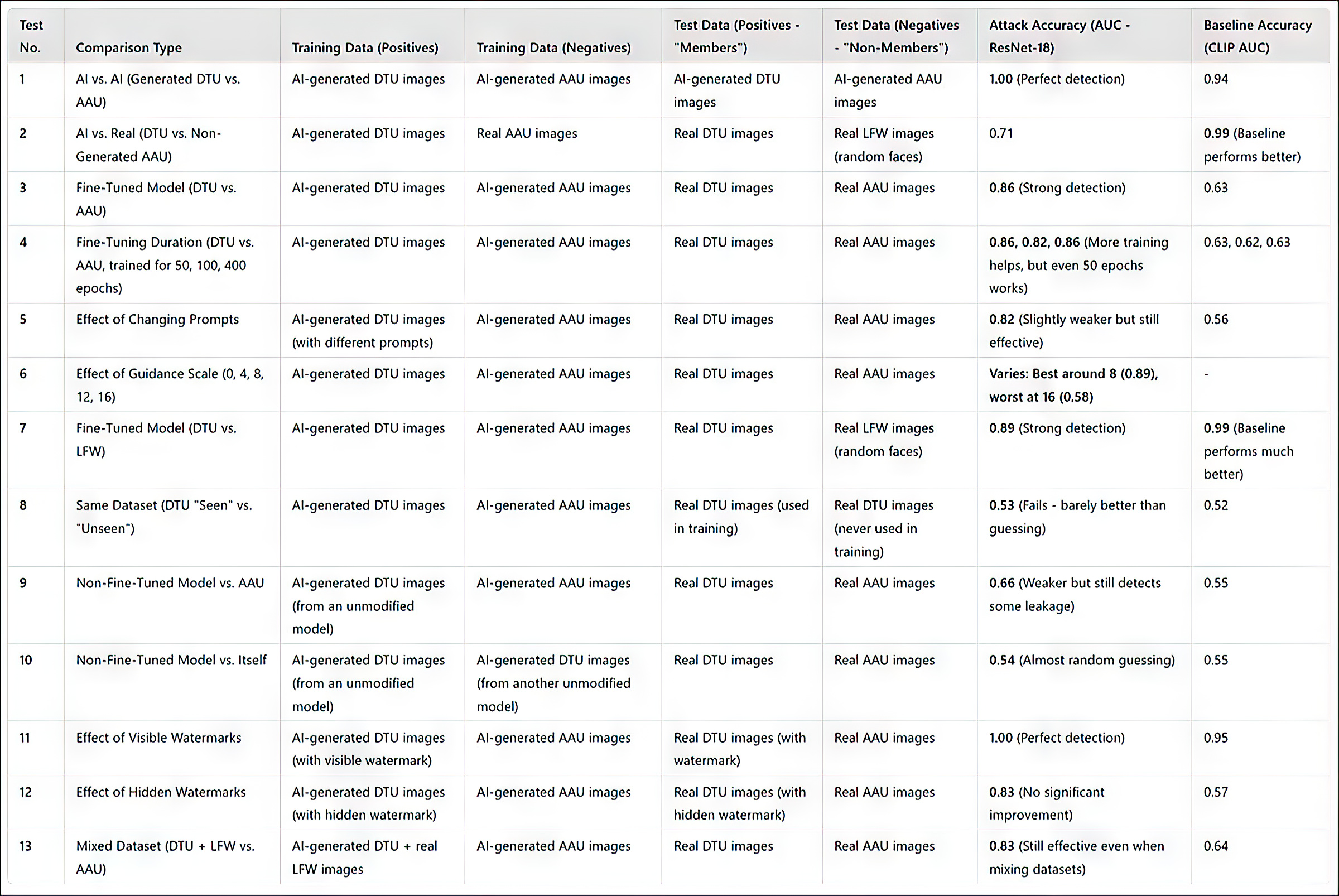
Riepilogo dei risultati di tutti i test. Fare clic sull’immagine per vederla in risoluzione più alta
Il metodo di attacco dei ricercatori si è rivelato più efficace quando si è trattato di modelli addestrati, in particolare quelli addestrati su un set specifico di immagini, come il viso di un individuo. Tuttavia, mentre l’attacco può determinare se un set di dati è stato utilizzato, fatica a identificare singole immagini all’interno di quel set di dati.
In termini pratici, quest’ultimo non è necessariamente un ostacolo all’utilizzo di un approccio come questo a scopo forense; mentre c’è relativamente poco valore nel dimostrare che un set di dati famoso come ImageNet sia stato utilizzato in un modello, un attaccante su un individuo privato (non una celebrità) tenderà ad avere meno scelta di dati di origine e dovrà sfruttare appieno i gruppi di dati disponibili come album di social media e altre raccolte online. Questi effettivamente creano un “hash” che può essere scoperto con i metodi descritti.
La ricerca nota che un altro modo per migliorare l’accuratezza è utilizzare immagini generate dall’AI come “non membri”, anziché affidarsi esclusivamente a immagini reali. Ciò evita tassi di successo artificialmente alti che altrimenti potrebbero fuorviare i risultati.
Un fattore aggiuntivo che influisce notevolmente sulla rilevamento, notano gli autori, è il watermarking. Quando le immagini di addestramento contengono filigrane visibili, l’attacco diventa molto efficace, mentre le filigrane nascoste offrono poco o nessun vantaggio.

La figura più a destra mostra la filigrana “nascosta” effettiva utilizzata nei test.
Infine, il livello di guida nella generazione di immagini da testo gioca anche un ruolo, con l’equilibrio ideale trovato su una scala di guida di circa 8. Anche quando non viene utilizzato alcun prompt diretto, un modello addestrato tende ancora a produrre output che assomigliano ai suoi dati di addestramento, rafforzando l’efficacia dell’attacco.
Conclusione
È un peccato che questo articolo interessante sia stato scritto in modo così inaccessibile, poiché dovrebbe essere di qualche interesse per i sostenitori della privacy e i ricercatori di AI occasionali.
Sebbene gli attacchi di inferenza di appartenenza possano rivelarsi uno strumento forense interessante e fruttuoso, è forse più importante, forse, per questo filone di ricerca sviluppare principi applicabili a livello generale, per evitare di finire nella stessa partita di “acchiapparello” che si è verificata per la rilevazione dei deepfake in generale, quando il rilascio di un modello più recente influisce negativamente sulla rilevazione e su sistemi forensi simili.
Dal momento che c’è qualche evidenza di un principio guida di alto livello pulito in questa nuova ricerca, possiamo sperare di vedere più lavoro in questa direzione.
Pubblicato per la prima volta venerdì 21 febbraio 2025












