
AI 101
Hvað er yfirfitting?
Hvað er yfirfitting?
Þegar þú þjálfar taugakerfi þarftu að forðast offita. Ofmátun er vandamál innan vélanáms og tölfræði þar sem líkan lærir mynstur þjálfunargagnasetts of vel, útskýrir þjálfunargagnasettið fullkomlega en nær ekki að alhæfa forspárgildi þess yfir á önnur gagnasöfn.
Til að setja það á annan hátt, þegar um er að ræða líkan sem er offitað mun það oft sýna mjög mikla nákvæmni á þjálfunargagnasettinu en litla nákvæmni á gögnum sem safnað er og keyrt í gegnum líkanið í framtíðinni. Það er fljótleg skilgreining á yfirfitting, en við skulum fara yfir hugtakið offitting nánar. Við skulum skoða hvernig offitting á sér stað og hvernig hægt er að forðast það.
Að skilja „Fit“ og Underfitting
Það er gagnlegt að skoða hugtakið undirfitting og „passa“ almennt þegar rætt er um ofklæðnað. Þegar við þjálfum líkan erum við að reyna að þróa ramma sem er fær um að spá fyrir um eðli, eða flokk, atriða innan gagnasafns, byggt á eiginleikum sem lýsa þessum hlutum. Líkan ætti að geta útskýrt mynstur innan gagnasafns og spáð fyrir um flokka framtíðargagnapunkta út frá þessu mynstri. Því betur sem líkanið útskýrir sambandið á milli eiginleika þjálfunarsettsins, því „hæfara“ líkanið okkar er.
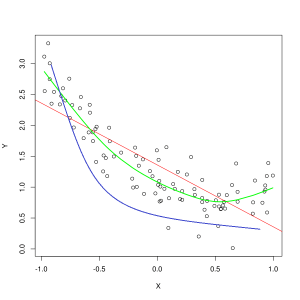
Blá lína táknar spár af líkani sem er vanhæft, en græna línan táknar líkan sem passar betur. Mynd: Pep Roca í gegnum Wikimedia Commons, CC BY SA 3.0, (https://commons.wikimedia.org/wiki/File:Reg_ls_curvil%C3%ADnia.svg)
Líkan sem útskýrir illa sambandið á milli eiginleika þjálfunargagnanna og nær því ekki að flokka framtíðargagnadæmi nákvæmlega er undirfitting þjálfunargögnin. Ef þú myndir setja línurit fyrir spáð samband líkans sem er vanhæft á móti raunverulegum skurðpunktum eiginleika og merkimiða, myndu spárnar fara út fyrir markið. Ef við hefðum línurit með raunverulegum gildum þjálfunarsetts merkt, myndi mjög vanhæft líkan missa verulega af flestum gagnapunktum. Líkan sem passar betur gæti skorið leið í gegnum miðju gagnapunktanna, þar sem einstakir gagnapunktar eru aðeins frá spágildum.
Vanfitting getur oft átt sér stað þegar ekki eru næg gögn til að búa til nákvæmt líkan, eða þegar reynt er að hanna línulegt líkan með ólínulegum gögnum. Fleiri þjálfunargögn eða fleiri eiginleikar munu oft hjálpa til við að draga úr vanhæfingu.
Svo hvers vegna myndum við ekki bara búa til líkan sem útskýrir hvert atriði í þjálfunargögnunum fullkomlega? Vissulega er fullkomin nákvæmni æskileg? Að búa til líkan sem hefur lært mynstur þjálfunargagnanna of vel er það sem veldur offitun. Þjálfunargagnasettið og önnur framtíðargagnasöfn sem þú keyrir í gegnum líkanið verða ekki nákvæmlega eins. Þeir munu líklega vera mjög líkir að mörgu leyti, en þeir munu einnig vera ólíkir í lykilatriðum. Þess vegna þýðir það að hanna líkan sem útskýrir þjálfunargagnasettið fullkomlega að þú endar með kenningu um tengsl eiginleika sem alhæfast ekki vel yfir í önnur gagnasafn.
Skilningur á Overfitting
Offitting á sér stað þegar líkan lærir smáatriðin í þjálfunargagnasettinu of vel, sem veldur því að líkanið þjáist þegar spár eru gerðar á utanaðkomandi gögnum. Þetta getur átt sér stað þegar líkanið lærir ekki aðeins eiginleika gagnasafnsins, það lærir líka tilviljunarkenndar sveiflur eða hávaða innan gagnasafnsins, sem leggur áherslu á þessi tilviljanakenndu/ómikilvægu atvik.
Offitting er líklegri til að eiga sér stað þegar ólínuleg líkön eru notuð, þar sem þau eru sveigjanlegri þegar þau læra gagnaeiginleika. Óparametrísk vélnámsreiknirit hafa oft ýmsar færibreytur og tækni sem hægt er að beita til að takmarka næmni líkansins fyrir gögnum og draga þannig úr offitun. Sem dæmi, ákvarðanatréslíkön eru mjög viðkvæm fyrir offitun, en hægt er að nota tækni sem kallast pruning til að fjarlægja af handahófi sum smáatriðin sem líkanið hefur lært.
Ef þú myndir draga út spár líkansins á X- og Y-ásum, myndirðu hafa spálínu sem sikksakkar fram og til baka, sem endurspeglar þá staðreynd að líkanið hefur reynt of mikið að passa alla punkta gagnasafnsins inn í skýring hennar.
Stjórna yfirfitting
Þegar við þjálfum líkan viljum við helst að líkanið geri engar villur. Þegar frammistaða líkansins rennur saman í átt að því að gera réttar spár um alla gagnapunkta í þjálfunargagnasettinu, er hæfnin að verða betri. Líkan sem passar vel getur útskýrt næstum allt þjálfunargagnasettið án þess að offita það.
Þegar líkan þjálfar batnar árangur þess með tímanum. Villutíðni líkansins mun lækka eftir því sem æfingatíminn líður, en hún minnkar aðeins að vissu marki. Staðurinn þar sem frammistaða líkansins á prófunarsettinu byrjar að hækka aftur er venjulega punkturinn þar sem offitting á sér stað. Til þess að passa fyrir líkan sem best, viljum við hætta að þjálfa líkanið á þeim stað þar sem minnst tap er á þjálfunarsettinu, áður en villan fer að aukast aftur. Ákjósanlegur viðkomustaður er hægt að ganga úr skugga um með því að grafa frammistöðu líkansins allan æfingatímann og hætta þjálfun þegar tapið er minnst. Hins vegar er ein áhætta við þessa aðferð til að stjórna offitun að tilgreina endapunkt fyrir þjálfunina á grundvelli prófunarframmistöðu þýðir að prófunargögnin verða að einhverju leyti innifalin í þjálfunarferlinu og þau missa stöðu sína sem eingöngu „ósnert“ gögn.
Það eru nokkrar mismunandi leiðir til að berjast gegn offitun. Ein aðferð til að draga úr offitun er að nota endursýnisaðferð, sem virkar með því að meta nákvæmni líkansins. Þú getur líka notað a löggilding gagnasafni til viðbótar við prófunarsettið og teiknað þjálfunarnákvæmni á móti löggildingarsettinu í stað prófunargagnasettsins. Þetta heldur prófunargagnasettinu þínu óséðu. Vinsæl endursýnaaðferð er K-falt krossgilding. Þessi tækni gerir þér kleift að skipta gögnunum þínum í undirmengi sem líkanið er þjálfað á og síðan er frammistaða líkansins á undirmengunum greind til að áætla hvernig líkanið mun standa sig á utanaðkomandi gögnum.
Að nota krossfullgildingu er ein besta leiðin til að áætla nákvæmni líkans á óséðum gögnum, og þegar það er sameinað með staðfestingargagnasettum er oft hægt að halda ofþenslu í lágmarki.










