Kecerdasan buatan
SofGAN: A GAN Face Generator Yang Menawarkan Kontrol Lebih Besar
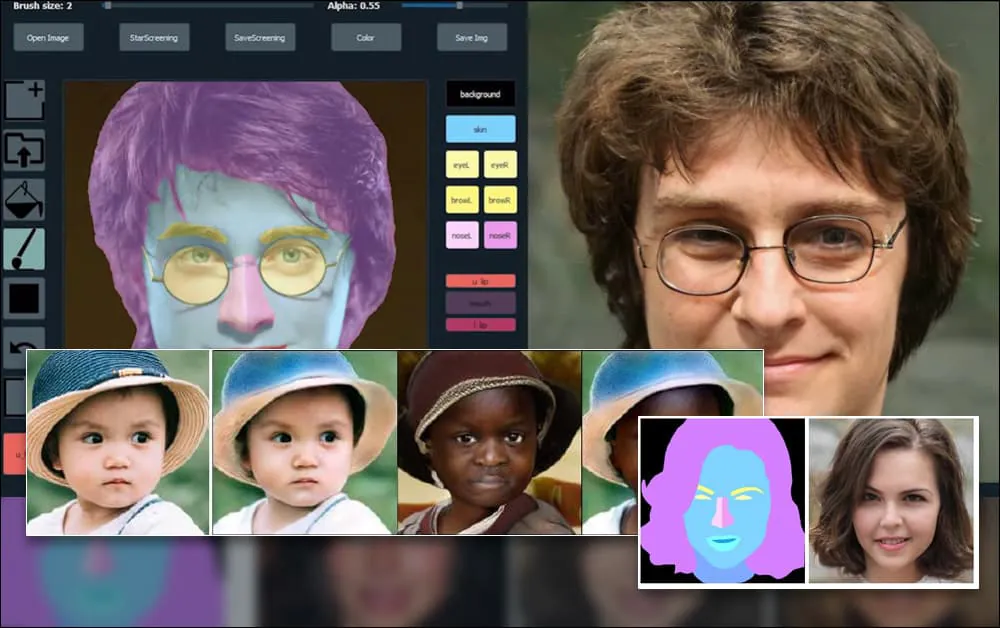
Peneliti di Shanghai dan AS telah mengembangkan sistem generasi potret berbasis GAN yang memungkinkan pengguna membuat wajah baru dengan tingkat kontrol yang belum pernah ada sebelumnya atas aspek individu seperti rambut, mata, kacamata, tekstur, dan warna.
Untuk mendemonstrasikan kemampuan sistem, para pencipta telah menyediakan antarmuka seperti Photoshop yang memungkinkan pengguna menggambar elemen segmentasi semantik secara langsung yang akan diinterpretasikan menjadi gambar realistis, dan bahkan dapat diperoleh dengan menggambar langsung di atas foto yang ada.
Dalam contoh di bawah, gambar aktor Daniel Radcliffe digunakan sebagai template penggambaran (dan tujuannya bukan untuk menghasilkan kesamaan dengan dia, tetapi gambar yang secara umum realistis). Ketika pengguna mengisi berbagai elemen, termasuk fasad diskrit seperti kacamata, mereka diidentifikasi dan diinterpretasikan dalam gambar output:
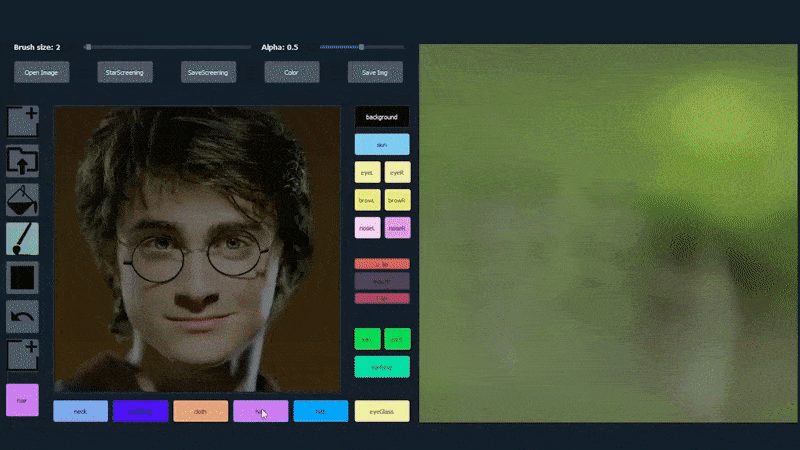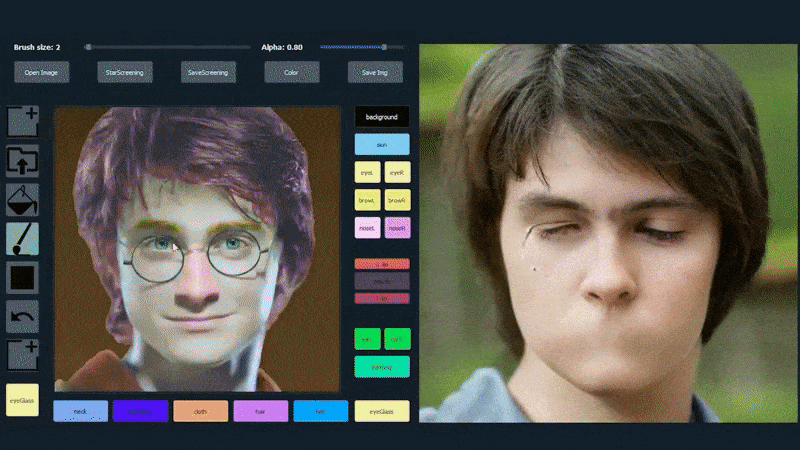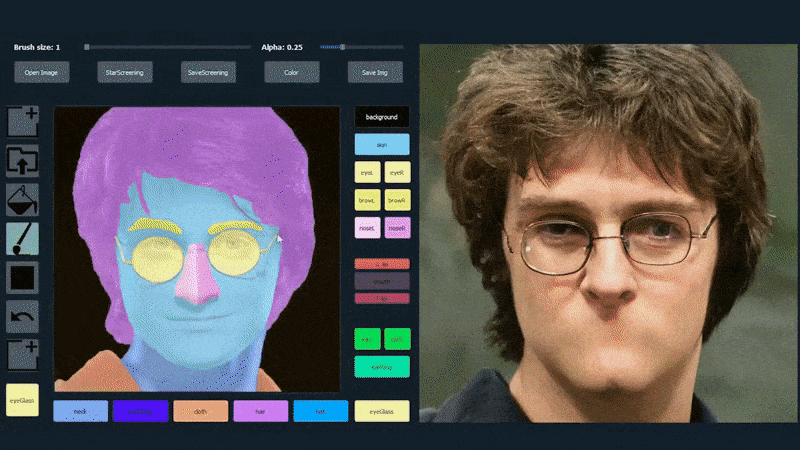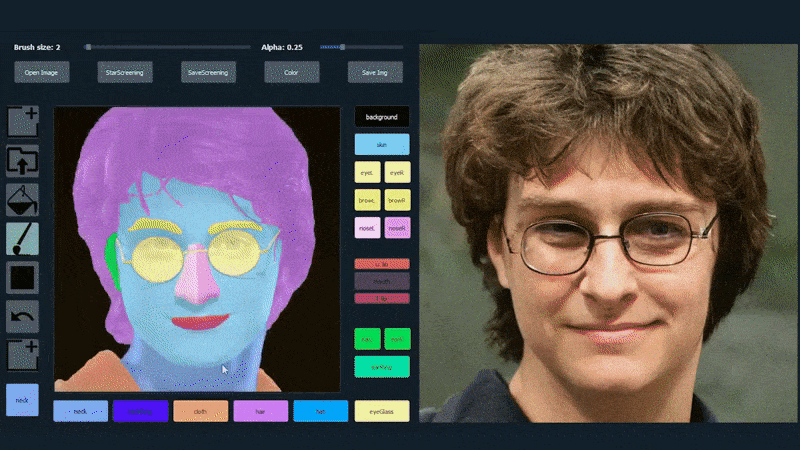
Menggunakan satu gambar sebagai bahan penggambaran untuk potret yang dihasilkan oleh SofGAN Sumber: https://www.youtube.com/watch?v=xig8ZA3DVZ8
Makalah ini berjudul SofGAN: A Portrait Image Generator dengan Dynamic Styling, dan dipimpin oleh Anpei Chen dan Ruiyang Liu, bersama dengan dua peneliti lain dari ShanghaiTech University dan satu dari University of California di San Diego.
Disentangling Fitur
Kontribusi utama dari karya ini bukanlah menyediakan antarmuka pengguna yang ramah, tetapi lebih pada ‘disentangling’ karakteristik fitur wajah yang dipelajari, seperti pose dan tekstur, yang memungkinkan SofGAN juga menghasilkan wajah yang berada pada sudut yang tidak langsung ke kamera.

Tidak seperti generator wajah berbasis Generative Adversarial Networks, SofGAN dapat mengubah sudut pandang dengan kehendak, dalam batas array sudut yang ada dalam data pelatihan Sumber: https://arxiv.org/pdf/2007.03780.pdf
Karena tekstur sekarang dipisahkan dari geometri, bentuk wajah dan tekstur juga dapat dimanipulasi sebagai entitas terpisah. Pada dasarnya, ini memungkinkan perubahan ras pada wajah sumber, praktik skandal yang sekarang memiliki aplikasi yang berguna, untuk membuat dataset pembelajaran mesin yang seimbang secara rasial.

SofGAN juga mendukung penuaan buatan dan penyesuaian gaya konsisten atribut pada tingkat granular yang belum pernah terlihat pada sistem segmentasi>gambar serupa seperti NVIDIA’s GauGAN dan Intel’s game-based neural rendering system.

SofGAN dapat mengimplementasikan penuaan sebagai gaya iteratif
Pemecahan lain untuk metodologi SofGAN adalah bahwa pelatihan tidak memerlukan gambar riil yang dipasangkan dengan segmentasi, tetapi dapat dilatih langsung pada gambar riil yang tidak dipasangkan.
Para peneliti menyatakan bahwa arsitektur ‘disentangling’ SofGAN terinspirasi oleh sistem rendering gambar tradisional, yang memecah elemen individual dari gambar. Dalam alur kerja efek visual, elemen untuk komposit secara rutin dipecah menjadi komponen terkecil, dengan spesialis yang didedikasikan untuk setiap komponen.
Semantic Occupancy Field (SOF)
Untuk mencapai ini dalam kerangka sintesis gambar pembelajaran mesin, para peneliti mengembangkan semantic occupancy field (SOF), sebuah ekstensi dari lapangan okupansi tradisional yang membedakan elemen komponen potret wajah. SOF dilatih pada peta segmentasi semantik multi-tampilan yang dikalibrasi, tetapi tanpa supervisi kebenaran dasar.

Iterasi multiple dari peta segmentasi tunggal (kiri bawah).
Selain itu, peta segmentasi 2D diperoleh dengan melakukan ray-tracing pada output SOF, sebelum diwarnai oleh generator GAN. Peta segmentasi semantik sintetis juga dikodekan dalam ruang dimensi rendah melalui tiga lapis encoder untuk memastikan kontinuitas output ketika sudut pandang diubah.












