Kecerdasan buatan
Enfabrica Meluncurkan Memory Fabric Berbasis Ethernet yang Dapat Mengubah Inferensi AI Skala Besar
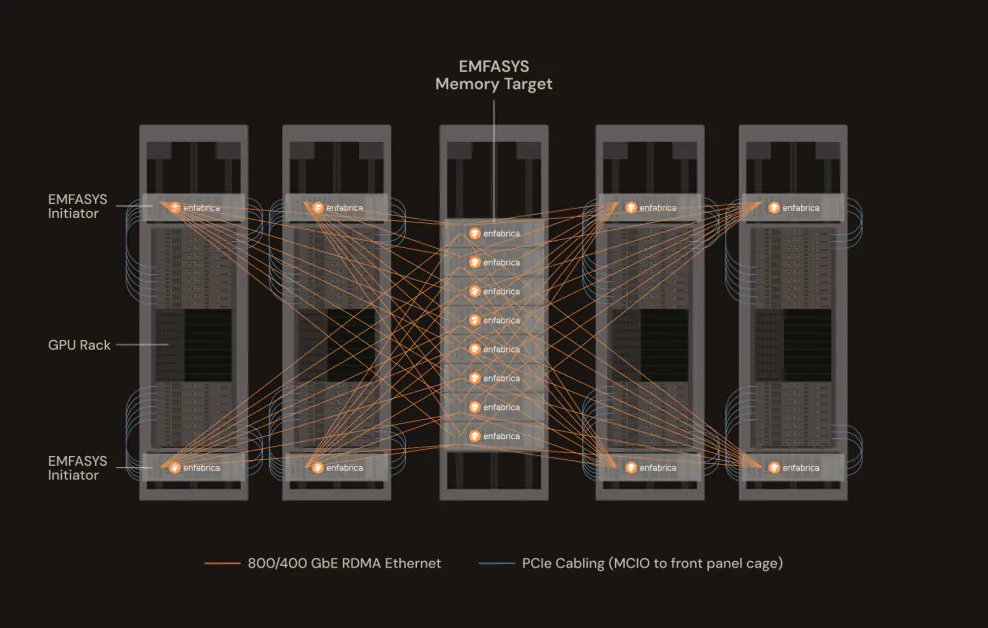
Enfabrica, sebuah startup yang berbasis di Silicon Valley dan didukung oleh Nvidia, telah meluncurkan produk inovatif yang dapat secara signifikan mengubah cara kerja beban AI skala besar diterapkan dan diperbesar. Sistem Memory Fabric Elastis (EMFASYS) baru dari perusahaan ini adalah memory fabric berbasis Ethernet pertama yang tersedia secara komersial, yang dirancang khusus untuk mengatasi bottleneck inti inferensi AI generatif: akses memori.
Pada saat model AI menjadi lebih kompleks, sadar konteks, dan persisten – memerlukan jumlah memori yang besar per sesi pengguna – EMFASYS menyediakan pendekatan baru untuk melepaskan memori dari komputasi, memungkinkan pusat data AI untuk secara dramatis meningkatkan kinerja, mengurangi biaya, dan meningkatkan utilisasi sumber daya termahal mereka: GPU.
Apa itu Memory Fabric – dan Mengapa Hal Ini Penting?
Secara tradisional, memori di pusat data telah terikat erat dengan server atau node tempat memori tersebut berada. Setiap GPU atau CPU hanya memiliki akses ke memori berkecepatan tinggi yang terikat langsung dengannya – biasanya HBM untuk GPU atau DRAM untuk CPU. Arsitektur ini bekerja dengan baik ketika beban kerja kecil dan dapat diprediksi. Namun, AI generatif telah mengubah permainan. LLM memerlukan akses ke jendela konteks yang besar, riwayat pengguna, dan memori multi-agents – semuanya harus diproses dengan cepat dan tanpa keterlambatan. Tuntutan memori ini sering kali melebihi kapasitas memori lokal yang tersedia, menciptakan bottleneck yang menghambat inti GPU dan meningkatkan biaya infrastruktur.
Sebuah memory fabric memecahkan masalah ini dengan mengubah memori menjadi sumber daya yang dibagikan dan terdistribusi – semacam memori yang terhubung ke jaringan yang dapat diakses oleh GPU atau CPU mana pun di klaster. Bayangkan ini sebagai menciptakan “awan memori” di dalam rak pusat data. Alih-alih mereplikasi memori di seluruh server atau membebani HBM yang mahal, sebuah fabric memungkinkan memori untuk diagregasi, didistribusikan, dan diakses sesuai kebutuhan melalui jaringan kecepatan tinggi. Ini memungkinkan beban kerja inferensi AI untuk diperbesar dengan lebih efisien tanpa terikat oleh batasan memori fisik dari node tunggal.
Pendekatan Enfabrica: Ethernet dan CXL, Bersama untuk Pertama Kalinya
EMFASYS mencapai arsitektur memori skala rak ini dengan menggabungkan dua teknologi kuat: RDMA over Ethernet dan Compute Express Link (CXL). Yang pertama memungkinkan transfer data ultra-rendah-latensi dan kecepatan tinggi melalui jaringan Ethernet standar. Yang kedua memungkinkan memori untuk dilepaskan dari CPU dan GPU dan dipool ke sumber daya bersama, yang dapat diakses melalui tautan CXL kecepatan tinggi.
Di inti EMFASYS terdapat chip ACF-S Enfabrica, sebuah “SuperNIC” 3,2 terabit-per-detik (Tbps) yang menggabungkan jaringan dan kontrol memori ke dalam satu perangkat. Chip ini memungkinkan server untuk berinterface dengan kumpulan memori DDR5 yang besar – hingga 18 terabyte per node – yang didistribusikan di seluruh rak. Yang penting, ini dilakukan menggunakan port Ethernet standar, memungkinkan operator untuk memanfaatkan infrastruktur pusat data yang ada tanpa harus berinvestasi pada interkoneksi khusus.
Apa yang membuat EMFASYS sangat menarik adalah kemampuannya untuk secara dinamis memindahkan beban kerja yang terikat memori dari HBM GPU yang mahal ke DRAM yang jauh lebih terjangkau, semua sambil mempertahankan latensi akses mikrodetik. Tumpukan perangkat lunak di balik EMFASYS termasuk mekanisme caching dan load-balancing cerdas yang menyembunyikan latensi dan mengatur pergerakan memori dengan cara yang transparan bagi LLM yang berjalan di sistem.
Implikasi untuk Industri AI
Ini lebih dari sekadar solusi perangkat keras yang cerdas – ini mewakili pergeseran filosofis dalam cara infrastruktur AI dibangun dan diperbesar. Ketika AI generatif berubah dari novelti menjadi kebutuhan, dengan miliaran pertanyaan pengguna diproses setiap hari, biaya untuk melayani model ini telah menjadi tidak berkelanjutan bagi banyak perusahaan. GPU sering kali tidak termanfaatkan bukan karena kurangnya komputasi, tetapi karena mereka menganggur menunggu memori. EMFASYS mengatasi ketidakseimbangan tersebut secara langsung.
Dengan memungkinkan memori yang dipool dan terhubung ke fabric yang dapat diakses melalui Ethernet, Enfabrica menawarkan operator pusat data alternatif yang dapat diperbesar untuk membeli lebih banyak GPU atau HBM. Sebagai gantinya, mereka dapat meningkatkan kapasitas memori secara modular, menggunakan DRAM dan jaringan cerdas, mengurangi jejak keseluruhan dan memperbaiki ekonomi inferensi AI.
Implikasinya melampaui penghematan biaya langsung. Arsitektur yang terdisagregasi ini membuka jalan bagi model memori-sebagai-layanan, di mana konteks, riwayat, dan keadaan agen dapat bertahan melampaui satu sesi atau server, membuka pintu untuk sistem AI yang lebih pintar dan lebih personal. Ini juga menyiapkan panggung untuk awan AI yang lebih tangguh, di mana beban kerja dapat didistribusikan secara elastis di seluruh rak atau seluruh pusat data tanpa batasan memori yang kaku.
Melihat ke Depan
Enfabrica’s EMFASYS saat ini sedang disampling dengan pelanggan terpilih, dan meskipun perusahaan belum mengungkapkan siapa mitra tersebut, Reuters melaporkan bahwa penyedia awan AI besar sudah mempelajari sistem ini. Ini menempatkan Enfabrica tidak hanya sebagai pemasok komponen, tetapi sebagai pengaktif kunci dalam generasi berikutnya infrastruktur AI.
Dengan melepaskan memori dari komputasi dan membuatnya tersedia di seluruh jaringan Ethernet kecepatan tinggi yang komoditas, Enfabrica meletakkan dasar untuk era baru arsitektur AI – di mana inferensi dapat diperbesar tanpa kompromi, di mana sumber daya tidak lagi terjebak, dan di mana ekonomi penerapan model bahasa besar akhirnya mulai masuk akal.
Di dunia yang semakin didefinisikan oleh sistem AI yang kaya konteks, multi-agents, memori tidak lagi menjadi aktor pendukung – ini adalah panggung. Dan Enfabrica bertaruh bahwa siapa pun yang membangun panggung terbaik akan menentukan kinerja AI selama bertahun-tahun mendatang.












