
Etika
A jelenlegi mesterséges intelligencia gyakorlatok lehetővé tehetik a szerzői jogi trollok új generációját

A Huawei és az akadémia közötti új kutatási együttműködés azt sugallja, hogy a mesterséges intelligenciával és a gépi tanulással kapcsolatos jelenlegi legfontosabb kutatások nagy része peres eljárásnak lehet kitéve, amint kereskedelmileg feltűnővé válik, mivel az áttörést lehetővé tevő adatkészleteket érvénytelen adatokkal terjesztik. olyan licencek, amelyek nem tartják tiszteletben azon nyilvános domainek eredeti feltételeit, amelyekről az adatokat szerezték.
Valójában ennek két szinte elkerülhetetlen lehetséges következménye van: hogy a nagyon sikeres, kereskedelmi forgalomba hozott mesterséges intelligencia-algoritmusok, amelyekről ismert, hogy ilyen adatkészleteket használtak, az opportunista szabadalmi trollok jövőbeni célpontjai lesznek, akiknek a szerzői jogait nem tartották tiszteletben az adataik lekaparásakor; és hogy a szervezetek és egyének ugyanazokat a jogi sebezhetőségeket használhatják fel arra, hogy tiltakozzanak az általuk kifogásolhatónak tartott gépi tanulási technológiák alkalmazása vagy elterjedése ellen.
A papír címet viseli Használhatom ezt a nyilvánosan elérhető adatkészletet kereskedelmi mesterséges intelligencia szoftverek készítésére? Nagy valószínűséggel nem, és a Huawei Canada és a Huawei China, valamint az Egyesült Királyság York Egyeteme és a Kanadai Victoria Egyetem együttműködése.
Hatból öt (népszerű) nyílt forráskódú adatkészlet, amely jogilag nem használható
A kutatáshoz a szerzők arra kérték a Huawei részlegeit, hogy válasszák ki a legkívánatosabb nyílt forráskódú adatkészleteket, amelyeket kereskedelmi projektekben szeretnének hasznosítani, és a válaszok közül kiválasztották a hat legkeresettebb adatkészletet: CIFAR-10 (egy részhalmaza a 80 millió apró kép adatkészlet, mivel visszavont a „becsmérlő kifejezések” és „sértő képek” esetében, bár származékai szaporodnak); ImageNet; Városképek (amely kizárólag eredeti anyagot tartalmaz); FFHQ; VGGFace2és MSCOCO.
Annak elemzésére, hogy a kiválasztott adatkészletek alkalmasak-e a kereskedelmi projektekben történő legális felhasználásra, a szerzők egy új csővezetéket fejlesztettek ki a licencek láncolatának visszakövetésére, amennyire ez az egyes halmazoknál lehetséges volt, bár gyakran kellett webarchívum-rögzítéseket igénybe venniük annak érdekében, hogy megkeresni a lejárt tartományokból származó licenceket, és bizonyos esetekben a legközelebbi elérhető információk alapján kellett „kitalálnia” a licenc állapotát.
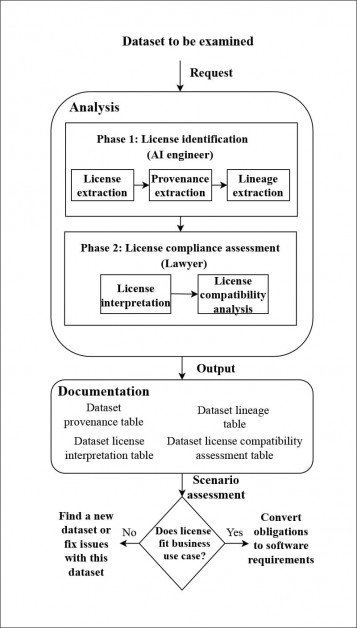
A szerzők által kidolgozott eredet-nyomozó rendszer architektúrája. Forrás: https://arxiv.org/pdf/2111.02374.pdf
A szerzők azt találták, hogy a hat adatkészletből öthöz licencek „legalább egy kereskedelmi felhasználási kontextushoz kapcsolódó kockázatokat tartalmaznak”:
„[Megfigyeljük], hogy az MS COCO kivételével a vizsgált licencek egyike sem teszi lehetővé a gyakorló szakemberek számára, hogy a betanított AI-modell adatain vagy akár kimenetén alapuló mesterségesintelligencia-modellt kereskedelmi forgalomba hozzanak. Ez az eredmény azt is hatékonyan megakadályozza, hogy a gyakorló szakemberek még az ezeken az adatkészleteken betanított, előre képzett modelleket is használhassanak. A nyilvánosan elérhető adatkészletek és az ezekre előre kiképzett mesterséges intelligencia modellek széles körben használják a kereskedelemben.' *
A szerzők megjegyzik továbbá, hogy a hat vizsgált adatkészlet közül három további licencsértést eredményezhet kereskedelmi termékekben, ha az adatkészletet módosítják, mivel ezt csak az MS-COCO teszi lehetővé. Ám az adatbővítés, valamint a befolyásos adatkészletek részhalmazai és szuperhalmazai általános gyakorlat.
A CIFAR-10 esetében az eredeti fordítók egyáltalán nem hoztak létre hagyományos licencformát, csupán azt követelték meg, hogy az adatkészletet használó projektek tartalmazzák az adatkészlet kiadását kísérő eredeti cikkre való hivatkozást, ami további akadályt jelent a létrehozásban. az adatok jogállása.
Ezenkívül csak a CityScapes adatkészlet tartalmaz olyan anyagokat, amelyeket kizárólag az adatkészlet létrehozói hoznak létre, ahelyett, hogy hálózati forrásokból „kurálták volna” (lekaparták), a CIFAR-10 és az ImageNet több forrást használ, amelyek mindegyikét meg kell vizsgálni. és visszavezethető bármilyen szerzői jogi mechanizmus (vagy akár értelmes felelősségkizárás) létrehozása érdekében.
No Way Out
Úgy tűnik, hogy a kereskedelmi mesterséges intelligencia vállalatok három tényezőre támaszkodnak, hogy megvédjék őket az olyan termékekkel kapcsolatos peres eljárásoktól, amelyek szabadon és engedély nélkül használtak fel szerzői jog által védett tartalmat az AI algoritmusok betanításához. Ezek egyike sem nyújt sok (vagy semmilyen) megbízható hosszú távú védelmet:
1: Laissez Faire nemzeti törvények
Bár a kormányok szerte a világon kénytelenek lazítani az adatleírással kapcsolatos törvényeken annak érdekében, hogy ne essenek vissza a teljesítményes mesterséges intelligencia felé (amely nagy mennyiségű valós adatokra támaszkodik, amelyek esetében a szerzői jogok rendszeres betartása és engedélyezése irreális) lenne, csak az Egyesült Államok teljes jogú mentességet kínál e tekintetben, a A méltányos használat doktrínája – egy irányelv, amelyet 2015-ben ratifikáltak a következtetés Az Authors Guild kontra Google, Inc. ügyében, amely megerősítette, hogy a keresőóriás szabadon felhasználhat szerzői jog által védett anyagokat a Google Books projektjéhez, anélkül, hogy jogsértéssel vádolnák.
Ha a méltányos használat doktrína politikája valaha is megváltozik (vagyis válaszul egy másik mérföldkőnek számító esetre, amely kellően nagy hatalommal rendelkező szervezeteket vagy vállalatokat érint), az valószínűleg eleve állapot a jelenlegi szerzői jogokat sértő adatbázisok kihasználása, a korábbi felhasználás védelme szempontjából; de nem folyamatban lévő olyan rendszerek használata és fejlesztése, amelyeket szerzői joggal védett anyagokon keresztül engedélyeztek megállapodás nélkül.
Ez a méltányos használat doktrína jelenlegi védelmét nagyon ideiglenes alapokra helyezi, és ebben a forgatókönyvben potenciálisan megkövetelheti a bevett, kereskedelmi forgalomba hozott gépi tanulási algoritmusok működésének leállítását azokban az esetekben, amikor származásukat szerzői joggal védett anyagok tette lehetővé – még olyan esetekben is, amikor modellé súlyok most már kizárólag az engedélyezett tartalommal foglalkoznak, de az illegálisan másolt tartalmakra kioktatták (és hasznosítják őket).
Az Egyesült Államokon kívül, amint azt a szerzők az új tanulmányban megjegyzik, a politika általában kevésbé engedékeny. Az Egyesült Királyság és Kanada csak a szerzői jog által védett adatok nem kereskedelmi célú felhasználását kártalanítja, míg az EU szöveg- és adatbányászati törvénye (amelyet nem írt felül teljesen a legújabb javaslatai formálisabb mesterségesintelligencia-szabályozás) kizárja az eredeti adatok szerzői jogi követelményeinek nem megfelelő AI-rendszerek kereskedelmi hasznosítását is.
Ez utóbbi megoldások azt jelentik, hogy egy szervezet nagyszerű dolgokat érhet el mások adataival, egészen addig – de nem ideértve –, hogy akár pénzt is kereshet belőle. Ebben a szakaszban a termék vagy jogilag nyilvánosságra kerülne, vagy megállapodásokat kellene kötni a szó szoros értelmében több millió szerzőijog-tulajdonossal, akik közül sokan ma már nyomon követhetetlenek az internet változó természete miatt – ez lehetetlen és megfizethetetlen lehetőség.
2: Figyelmeztetés Emptor
Azokban az esetekben, amikor a jogsértő szervezetek abban reménykednek, hogy elhalasztják a hibáztatást, az új lap azt is megjegyzi, hogy a legnépszerűbb nyílt forráskódú adatkészletek licencei automatikusan kártalanítják magukat a szerzői joggal való visszaélés miatti követelésekkel szemben:
„Például az ImageNet licence kifejezetten előírja a gyakorló szakembereknek, hogy kártalanítsák az ImageNet csapatát az adatkészlet használatából eredő bármely követelés ellen. Az FFHQ, VGGFace2 és MS COCO adatkészletek megkövetelik, hogy az adatkészletet, ha terjesztik vagy módosítják, ugyanazon licenc alatt kell bemutatni.
Ez gyakorlatilag arra kényszeríti a FOSS-adatkészleteket használókat, hogy elnyeljék a szerzői joggal védett anyagok használatáért való felelősséget, az esetleges peres eljárásokkal szemben (bár ez nem feltétlenül védi meg az eredeti fordítókat abban az esetben, ha a „biztonságos kikötő” jelenlegi légkörét magában foglalja).
3: Kártalanítás a homályon keresztül
A gépi tanulási közösség kollaboratív jellege meglehetősen nehézzé teszi a vállalati okkultizmus felhasználását a szerzői jogokat sértő adatkészletekből hasznot húzó algoritmusok jelenlétének elfedésére. A hosszú távú kereskedelmi projektek gyakran nyílt FOSS-környezetekben kezdődnek, ahol az adatkészletek használata nyilvántartásba vehető, a GitHubon és más nyilvánosan elérhető fórumokon, vagy ahol a projekt eredetét előzetesen nyomtatott vagy lektorált dokumentumokban tették közzé.
Még akkor is, ha ez nem így van, modell inverziója is egyre inkább képes az adathalmazok tipikus jellemzőinek feltárására (vagy akár kifejezetten kimenet a forrásanyag egy része), vagy önmagában bizonyítékot szolgáltat, vagy eléggé gyanús jogsértést tesz lehetővé ahhoz, hogy bíróság által elrendelt hozzáférést biztosítson az algoritmus fejlesztésének történetéhez és a fejlesztés során használt adatkészletek részleteihez.
Következtetés
Az írás az engedély nélkül megszerzett szerzői joggal védett anyagok kaotikus és ad hoc felhasználását mutatja be, valamint egy sor licencláncot, amely az adatok eredeti forrásáig logikusan követve több ezer szerzőijog-tulajdonossal, akiknek művét bemutatták, tárgyalásokat igényelne. sokféle licencfeltételt tartalmazó webhelyek égisze alatt, sok esetben kizárva a származékos kereskedelmi alkotásokat.
A szerzők megállapítják:
„A nyilvánosan elérhető adatkészleteket széles körben használják kereskedelmi mesterséges intelligencia szoftverek készítésére. Ezt akkor lehet megtenni, ha [és] csak akkor, ha a nyilvánosan elérhető adatkészlethez tartozó licenc erre jogosít fel. Nem könnyű azonban ellenőrizni a nyilvánosan elérhető adatkészletekhez kapcsolódó licencben biztosított jogokat és kötelezettségeket. Mert időnként az engedély nem egyértelmű, vagy esetleg érvénytelen.
Újabb új mű, melynek címe Jogi adatkészletek készítéseA Szingapúri Menedzsment Egyetem Számítási Jogi Központja által november 2-án közzétett cikk szintén hangsúlyozza, hogy az adattudósoknak fel kell ismerniük, hogy az ad hoc adatgyűjtés „vadnyugati” korszaka a végéhez közeledik, és tükrözi a Huawei ajánlásait. szigorúbb szokások és módszertanok elfogadására törekszik annak biztosítása érdekében, hogy az adatkészlet-használat ne tegye ki a projektet jogi következményeknek, mivel a kultúra idővel változik, és mivel a gépi tanulási szektorban folyó jelenlegi globális tudományos tevékenység kereskedelmi megtérülést keres a több éves befektetésből. . A szerző megjegyzi*:
„[A] ML adatkészleteket érintő jogszabályok állománya növekedni fog, a jelenlegi törvények által kínált aggodalmak közepette elégtelen biztosítékok. Az AIA tervezete [Az EU mesterséges intelligenciáról szóló törvénye], ha elfogadják, jelentősen megváltoztatná a mesterséges intelligenciát és az adatkezelési környezetet; más joghatóságok követhetik példájukat saját törvényeikkel. '
* A szövegközi hivatkozások hiperhivatkozásokká alakítása















