AI 101
बायेस थियोरम क्या है?
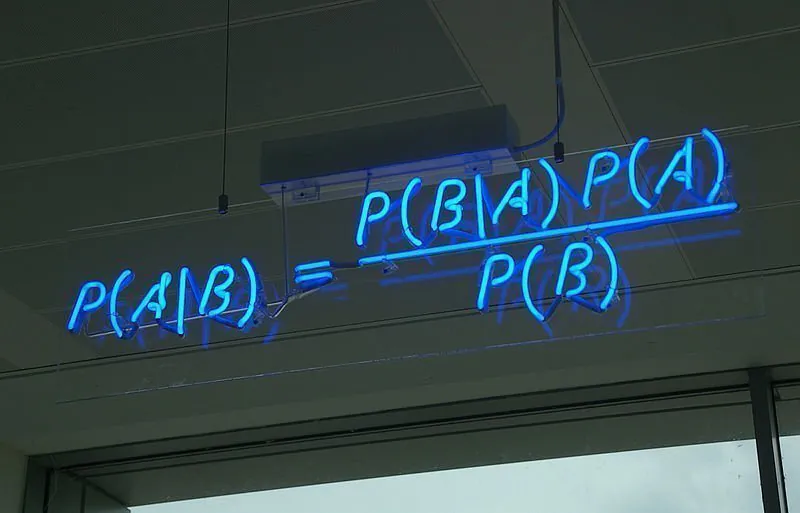
यदि आप डेटा साइंस या मशीन लर्निंग के बारे में सीख रहे हैं, तो संभावना है कि आपने पहले “बायेस थियोरम” शब्द सुना होगा, या “बायेस क्लासिफायर”। ये अवधारणाएं थोड़ी भ्रमित करने वाली हो सकती हैं, खासकर यदि आप परंपरागत, फ्रीक्वेंटिस्ट स्टैटिस्टिक्स परिप्रेक्ष्य से संभावना के बारे में सोचने के अभ्यस्त नहीं हैं। यह लेख बायेस थियोरम के पीछे के सिद्धांतों और मशीन लर्निंग में इसका उपयोग कैसे किया जाता है, इसकी व्याख्या करने का प्रयास करेगा।
बायेस थियोरम क्या है?
बायेस थियोरम एक सशर्त संभावना की गणना करने का तरीका है। सशर्त संभावना (एक घटना की संभावना कि एक अलग घटना के होने पर) की गणना करने का पारंपरिक तरीका सशर्त संभावना सूत्र का उपयोग करना है, घटना एक और घटना दो के एक ही समय में होने की संयुक्त संभावना की गणना करना और फिर इसे घटना दो के होने की संभावना से विभाजित करना। हालांकि, सशर्त संभावना की गणना बायेस थियोरम का उपयोग करके थोड़े अलग तरीके से भी की जा सकती है।
सशर्त संभावना की गणना बायेस थियोरम के साथ, आप निम्नलिखित चरणों का उपयोग करते हैं:
- स्थिति बी के सच होने की संभावना का निर्धारण करें, यह मानते हुए कि स्थिति ए सच है।
- घटना ए के सच होने की संभावना का निर्धारण करें।
- दो संभावनाओं को एक साथ गुणा करें।
- घटना बी के होने की संभावना से विभाजित करें।
इसका मतलब है कि बायेस थियोरम का सूत्र इस प्रकार व्यक्त किया जा सकता है:
पी(ए|बी) = पी(बी|ए)*पी(ए) / पी(बी)
सशर्त संभावना की गणना इस तरह विशेष रूप से उपयोगी है जब उल्टी सशर्त संभावना की गणना आसानी से की जा सकती है, या जब संयुक्त संभावना की गणना करना बहुत चुनौतीपूर्ण होगा।
बायेस थियोरम का उदाहरण
यह अधिक व्याख्या करने में आसान हो सकता है यदि हम एक उदाहरण पर कुछ समय बिताते हैं कि आप बायेसियन तर्क और बायेस थियोरम को कैसे लागू करेंगे। मान लें कि आप एक सरल गेम खेल रहे हैं जहां कई प्रतिभागी आपको एक कहानी सुनाते हैं और आपको यह निर्धारित करना होता है कि प्रतिभागियों में से कौन आपको झूठ बोल रहा है। आइए इस कल्पनात्मक परिदृश्य में चरों के साथ बायेस थियोरम के लिए समीकरण भरें।
हम यह भविष्यवाणी करने का प्रयास कर रहे हैं कि प्रत्येक व्यक्ति झूठ बोल रहा है या सच बता रहा है, इसलिए यदि आपके अलावा तीन खिलाड़ी हैं, तो श्रेणीबद्ध चर ए1, ए2, और ए3 के रूप में व्यक्त किया जा सकता है। उनके झूठ/सच के लिए साक्ष्य उनका व्यवहार है। जैसे कि पोकर खेलने के दौरान, आप कुछ “टेल्स” की तलाश करेंगे जो यह संकेत देते हैं कि व्यक्ति झूठ बोल रहा है और अपने अनुमान को सूचित करने के लिए उस जानकारी का उपयोग करेंगे। या यदि आपको उनसे प्रश्न पूछने की अनुमति दी जाती है, तो यह उनकी कहानी में कोई भी साक्ष्य होगा जो जोड़ता नहीं है। हम झूठ बोलने वाले व्यक्ति के साक्ष्य को बी के रूप में प्रस्तुत कर सकते हैं।
स्पष्ट करने के लिए, हम यह भविष्यवाणी करने का प्रयास कर रहे हैं कि संभावना (ए झूठ बोल रहा है/सच बता रहा है|उनके व्यवहार के साक्ष्य दिए गए)। ऐसा करने के लिए हमें बी दिए गए ए की संभावना का पता लगाना होगा, या झूठ बोल रहे हैं या सच बता रहे हैं इसके आधार पर उनके व्यवहार की संभावना का पता लगाना होगा। आप यह निर्धारित करने का प्रयास कर रहे हैं कि आप जो व्यवहार देख रहे हैं वह किन परिस्थितियों में सबसे ज्यादा समझ में आता है। यदि आप तीन व्यवहार देख रहे हैं, तो आप प्रत्येक व्यवहार के लिए गणना करेंगे। उदाहरण के लिए, पी(बी1, बी2, बी3 * ए)। आप खेल में खुद के अलावा प्रत्येक व्यक्ति के लिए ऐसा करेंगे। यह समीकरण का यह हिस्सा है:
पी(बी1, बी2, बी3,|ए) * पी|ए
अंत में, आप इसे बी की संभावना से विभाजित करते हैं।
यदि हमें इस समीकरण में वास्तविक संभावनाओं के बारे में कोई साक्ष्य मिलता है, तो हम अपने प्रायोरिक मॉडल को फिर से बनाएंगे, जिसमें नए साक्ष्य को ध्यान में रखा जाएगा। इसे अपने प्रायोरिक्स को अपडेट करना कहा जाता है, क्योंकि आप देखे गए घटनाओं के होने की प्रायोरिक संभावना के बारे में अपने अनुमानों को अपडेट करते हैं।
मशीन लर्निंग अनुप्रयोग बायेस थियोरम के लिए
बायेस थियोरम का उपयोग मशीन लर्निंग में सबसे आम रूप नेव बायेस एल्गोरिदम के रूप में होता है।
नेव बायेस द्विआधारी और मल्टी-क्लास डेटासेट दोनों के वर्गीकरण के लिए उपयोग किया जाता है, नेव बायेस अपना नाम इस तथ्य से प्राप्त करता है कि साक्षियों के साक्ष्य/विशेषताओं – बीएस को पी(बी1, बी2, बी3 * ए) में – एक दूसरे से स्वतंत्र माना जाता है। यह माना जाता है कि ये विशेषताएं एक दूसरे को प्रभावित नहीं करती हैं ताकि मॉडल को सरल बनाया जा सके और गणना संभव हो सके, इसके बजाय प्रत्येक विशेषता के बीच संबंधों की गणना करने का जटिल कार्य करने के बजाय। इस सरलीकृत मॉडल के बावजूद, नेव बायेस एक वर्गीकरण एल्गोरिदम के रूप में बहुत अच्छा प्रदर्शन करता है, यहां तक कि जब यह धारणा शायद सच नहीं है (जो अधिकांश समय होता है)।
नेव बायेस क्लासिफायर के सामान्य रूप से उपयोग किए जाने वाले वेरिएंट में मल्टीनोमियल नेव बायेस, बर्नौली नेव बायेस, और गॉसियन नेव बायेस शामिल हैं।
मल्टीनोमियल नेव बायेस एल्गोरिदम अक्सर दस्तावेजों के वर्गीकरण के लिए उपयोग किया जाता है, क्योंकि यह एक दस्तावेज़ में शब्दों की आवृत्ति की व्याख्या करने में प्रभावी है।
बर्नौली नेव बायेस मल्टीनोमियल नेव बायेस के समान काम करता है, लेकिन एल्गोरिदम द्वारा दिए गए पूर्वानुमान बूलियन होते हैं। इसका मतलब है कि जब एक वर्ग की भविष्यवाणी की जाती है, तो मान बाइनरी होते हैं, हां या ना।
यदि प्रेडिक्टर्स/विशेषताओं के मान विविक्त नहीं हैं बल्कि निरंतर हैं, तो गॉसियन नेव बायेस का उपयोग किया जा सकता है। यह माना जाता है कि निरंतर विशेषताओं के मान एक गॉसियन वितरण से नमूने लिए गए हैं।












