कृत्रिम बुद्धिमत्ता
SofGAN: एक जीएन फेस जेनरेटर जो अधिक नियंत्रण प्रदान करता है
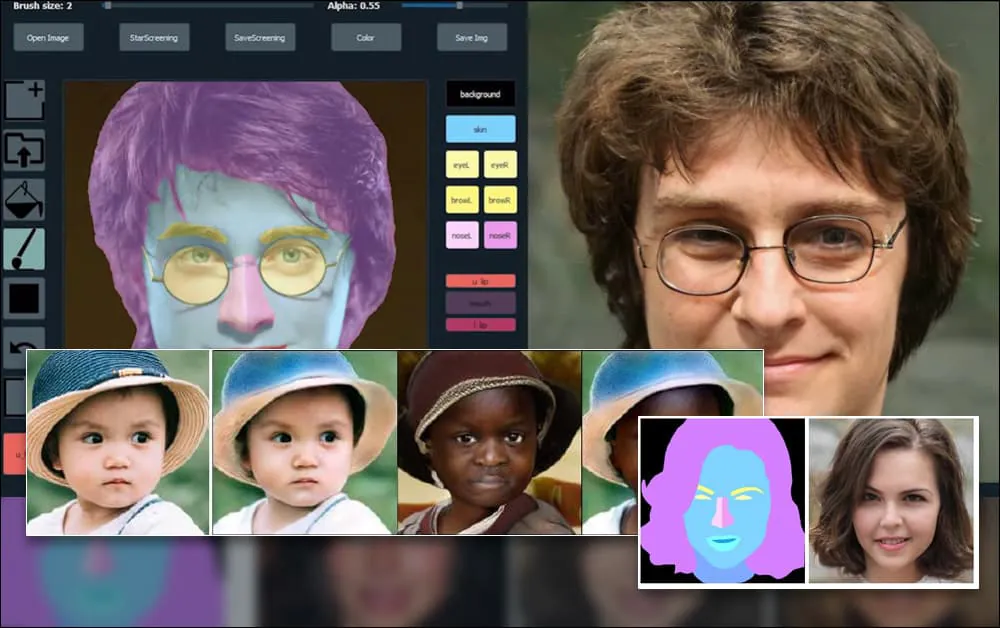
शंघाई और संयुक्त राज्य अमेरिका के शोधकर्ताओं ने एक जीएन-आधारित पोर्ट्रेट जेनरेशन सिस्टम विकसित किया है जो उपयोगकर्ताओं को बाल, आंखें, चश्मा, बनावट और रंग जैसे व्यक्तिगत पहलुओं पर पहले से उपलब्ध नहीं होने वाले स्तर के नियंत्रण के साथ नए चेहरे बनाने की अनुमति देता है।
सिस्टम की बहुमुखी प्रकृति को प्रदर्शित करने के लिए, निर्माताओं ने एक फोटोशॉप-शैली का इंटरफेस प्रदान किया है जिसमें उपयोगकर्ता सीधे सेमेंटिक सेगमेंटेशन तत्वों को आकर्षित कर सकते हैं जो वास्तविक छवियों में पुनः व्याख्या की जा सकती है, और यहां तक कि मौजूदा फोटोग्राफ पर सीधे आकर्षित करके भी प्राप्त की जा सकती है।
नीचे दिए गए उदाहरण में, अभिनेता डैनियल रेडक्लिफ की एक तस्वीर का उपयोग एक ट्रेसिंग टेम्पलेट के रूप में किया जाता है (और उद्देश्य उनके समान नहीं है, बल्कि एक सामान्य रूप से फोटोरियलिस्टिक छवि बनाना है)। जैसे ही उपयोगकर्ता विभिन्न तत्वों को भरता है, जिनमें चश्मा जैसे विविध पहलू शामिल हैं, वे पहचाने जाते हैं और आउटपुट ड्राइंग छवि में व्याख्या की जाती है:
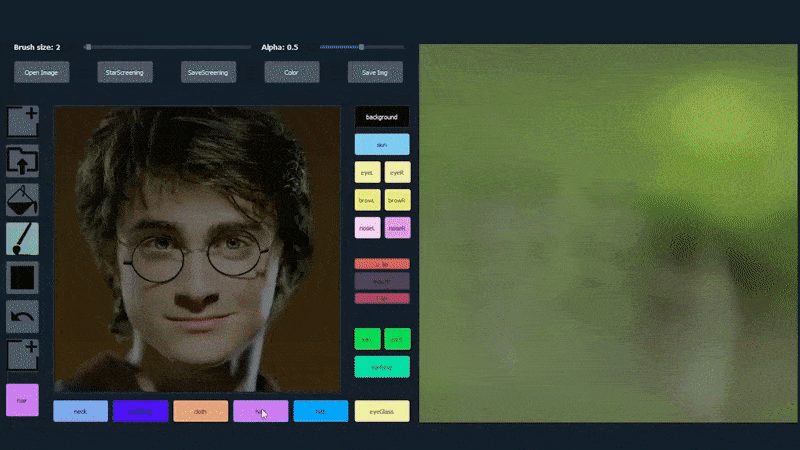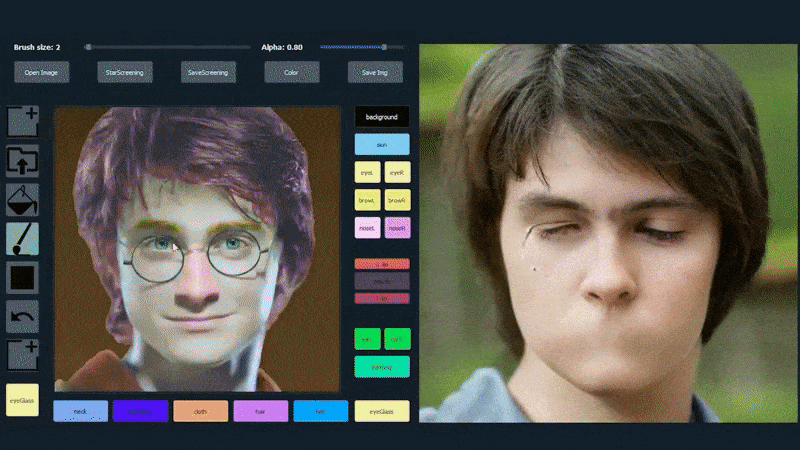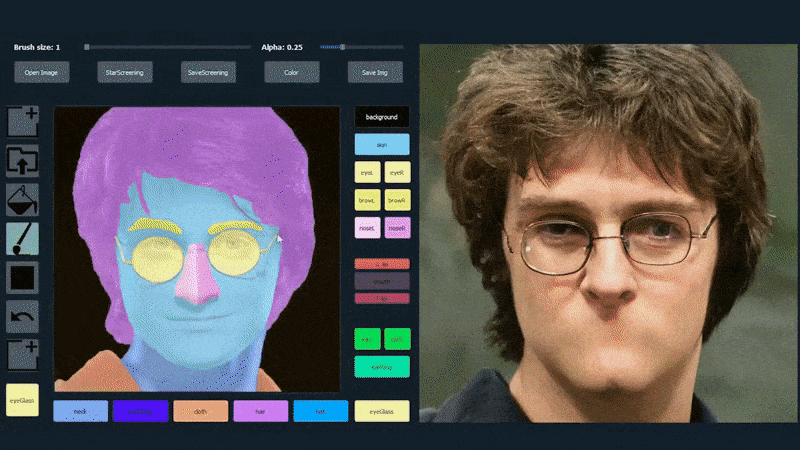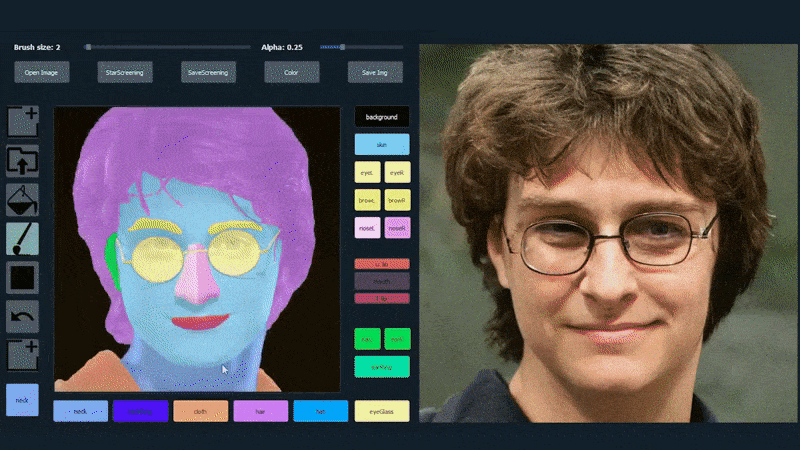
एक छवि का उपयोग SofGAN-जेनरेटेड पोर्ट्रेट के लिए ट्रेसिंग सामग्री के रूप में किया जा रहा है। स्रोत: https://www.youtube.com/watch?v=xig8ZA3DVZ8
लेख का शीर्षक पेपर है जो SofGAN: एक पोर्ट्रेट इमेज जेनरेटर के साथ डायनामिक स्टाइलिंग है, और इसका नेतृत्व Anpei Chen और Ruiyang Liu, साथ ही शंघाईटेक यूनिवर्सिटी और सैन डिएगो में कैलिफोर्निया विश्वविद्यालय के दो अन्य शोधकर्ताओं द्वारा किया जाता है।
विशेषताओं को अलग करना
कार्य का प्राथमिक योगदान उपयोगकर्ता-मित्री यूएक्स प्रदान करने में नहीं है, बल्कि सीखे गए चेहरे की विशेषताओं, जैसे कि मुद्रा और बनावट को ‘अलग करने’ में है, जो SofGAN को कैमरा दृष्टिकोण के अप्रत्यक्ष कोणों पर चेहरे भी बनाने की अनुमति देता है।

जेनरेटिव एडवर्सेरियल नेटवर्क पर आधारित चेहरे के जेनरेटर के बीच असामान्य, SofGAN दृष्टिकोण को अपनी मर्जी से बदल सकता है, प्रशिक्षण डेटा में मौजूद कोणों की सरणी की सीमा के भीतर। स्रोत: https://arxiv.org/pdf/2007.03780.pdf
चूंकि बनावट अब ज्यामिति से अलग हो गई है, चेहरे का आकार और बनावट को अलग-अलग इकाइयों के रूप में बदला जा सकता है। वास्तव में, यह स्रोत चेहरे की नस्ल बदलने की अनुमति देता है, एक विवादास्पद अभ्यास जिसका अब संभावित रूप से उपयोगी अनुप्रयोग है, निर्माण के लिए रacially- संतुलित मशीन लर्निंग डेटासेट।

SofGAN को कृत्रिम उम्र बढ़ाने और विशेषता-संगत शैली समायोजन का समर्थन भी करता है, जो NVIDIA के GauGAN और Intel के गेम-आधारित न्यूरल रेंडरिंग सिस्टम जैसे समान विभाजन>छवि प्रणालियों में देखे गए स्तर की तुलना में एक अनोखे स्तर पर करता है।

SofGAN उम्र बढ़ाने को एक पुनरावृत्ति शैली के रूप में लागू कर सकता है।
SofGAN की विधि के लिए एक और सफलता यह है कि प्रशिक्षण के लिए जोड़े गए सेगमेंटेशन/वास्तविक छवियों की आवश्यकता नहीं है, बल्कि यह सीधे अनजोड़े वास्तविक दुनिया की छवियों पर प्रशिक्षित किया जा सकता है।
शोधकर्ता कहते हैं कि SofGAN की ‘अलग करने’ वाली वास्तुकला पारंपरिक छवि रेंडरिंग प्रणालियों से प्रेरित थी, जो एक छवि के व्यक्तिगत पहलुओं को अलग करती है। दृश्य प्रभाव वर्कफ्लो में, एक संयोजन के लिए तत्वों को नियमित रूप से सबसे छोटे घटकों में तोड़ दिया जाता है, जिसमें प्रत्येक घटक के लिए विशेषज्ञ शामिल होते हैं।
सेमेंटिक ऑक्यूपेंसी फील्ड (एसओएफ)
इसे एक मशीन लर्निंग इमेज सिंथेसिस फ्रेमवर्क में प्राप्त करने के लिए, शोधकर्ताओं ने एक सेमेंटिक ऑक्यूपेंसी फील्ड (एसओएफ) विकसित किया, जो पारंपरिक ऑक्यूपेंसी फील्ड का एक विस्तार है जो चेहरे के पोर्ट्रेट के व्यक्तिगत तत्वों को अलग करता है। एसओएफ को कैलिब्रेटेड मल्टी-व्यू सेमेंटिक सेगमेंटेशन मैप्स पर प्रशिक्षित किया गया था, लेकिन किसी भी ग्राउंड ट्रुथ पर्यवेक्षण के बिना।

एकल सेगमेंटेशन मैप (नीचे बाएं) से कई पुनरावृत्तियां।
इसके अतिरिक्त, 2डी सेगमेंटेशन मैप्स एसओएफ के आउटपुट को रे ट्रेसिंग करके प्राप्त किए जाते हैं, और फिर एक जीएन जेनरेटर द्वारा बनावट की जाती है। ‘सिंथेटिक’ सेमेंटिक सेगमेंटेशन मैप्स को भी एक तीन-परत वाले एनकोडर के माध्यम से एक कम-आयामी स्थान में एनकोड किया जाता है ताकि दृष्टिकोण बदलने पर आउटपुट की निरंतरता सुनिश्चित की जा सके।
प्रशिक्षण योजना प्रत्येक सेमेंटिक क्षेत्र के लिए दो यादृच्छिक शैलियों को स्थानिक रूप से मिलाती है:

SofGAN की वास्तुकला।
शोधकर्ता दावा करते हैं कि SofGAN वर्तमान वैकल्पिक राज्य-ऑफ-द-आर्ट (एसओटीए) दृष्टिकोणों की तुलना में एक कम फ्रेचेट इन्सेप्शन डिस्टेंस (एफआईडी) प्राप्त करता है, साथ ही साथ एक उच्च सीखा हुआ प्रतिबिंबित छवि पैच समानता (एलपीआईपीएस) मीट्रिक।
पिछले स्टाइलजीएन दृष्टिकोण अक्सर विशेषता जुड़ाव से बाधित रहे हैं, जिसमें एक छवि के घटक अविभाज्य रूप से एक दूसरे के साथ जुड़े हुए होते हैं, जिससे एक वांछित तत्व (जैसे कान के आकार को सूचित करने वाली एक तस्वीर में कान के बाल) के साथ अवांछित तत्व दिखाई देते हैं।

रे मार्चिंग सेमेंटिक सेगमेंटेशन मैप्स के आयतन की गणना करने के लिए किया जाता है, जो कई दृष्टिकोणों को सक्षम बनाता है।
डेटासेट और प्रशिक्षण
SofGAN के विभिन्न कार्यान्वयन के विकास में तीन डेटासेट का उपयोग किया गया था: CelebAMask-HQ, जो 30,000 उच्च-रिज़ॉल्यूशन छवियों का एक भंडार है जो CelebA-HQ डेटासेट से लिया गया है; NVIDIA का Flickr-Faces-HQ (FFHQ), जिसमें 70,000 छवियां हैं, जहां शोधकर्ताओं ने एक पूर्व-प्रशिक्षित चेहरे के पार्सर का उपयोग करके छवियों को लेबल किया; और एक स्व-उत्पादित समूह 122 पोर्ट्रेट स्कैन के साथ जिनमें मैन्युअल रूप से लेबल किए गए सेमेंटिक क्षेत्र हैं।
एसओएफ में तीन प्रशिक्षित उप-मॉड्यूल हैं – हाइपर-नेट, एक रे मार्चर (ऊपर दी गई छवि देखें), और एक वर्गीकरणकर्ता। परियोजना के सेमेंटिक इंस्टेंस वाइज्ड (एसआईडब्ल्यू) स्टाइलजीएन जेनरेटर को स्टाइलजीएन2 के समान कुछ पहलुओं में कॉन्फ़िगर किया गया है। डेटा ऑगमेंटेशन को यादृच्छिक स्केलिंग और क्रॉपिंग के माध्यम से लागू किया जाता है, और प्रशिक्षण में हर चार कदम पर पथ नियमितीकरण होता है। पूरी प्रशिक्षण प्रक्रिया में 22 दिन लगे 800,000 पुनरावृत्तियों तक पहुंचने के लिए चार आरटीएक्स 2080 टी जीपीयू पर CUDA 10.1 पर।
लेख में 2080 कार्डों की कॉन्फ़िगरेशन का उल्लेख नहीं किया गया है, जो 11GB-22GB VRAM प्रत्येक को समायोजित कर सकता है, जिसका अर्थ है कि SofGAN को प्रशिक्षित करने के लिए उपयोग किए जाने वाले कुल VRAM लगभग 44GB और 88GB के बीच है।
शोधकर्ता观察 करते हैं कि सामान्यीकृत, उच्च-स्तरीय परिणाम प्रशिक्षण के शुरू में ही दिखाई देने लगे, 1500 पुनरावृत्तियों पर, तीन दिनों में प्रशिक्षण। प्रशिक्षण का शेष भाग बाल और आंख जैसी विस्तृत विवरण जैसे विस्तृत विवरण प्राप्त करने के लिए एक धीमी गति से आगे बढ़ा।
SofGAN आमतौर पर NVIDIA के SPADE और Pix2PixHD, और SEAN जैसे प्रतिद्वंद्वी विधियों की तुलना में एक ही सेगमेंटेशन मैप से अधिक वास्तविक परिणाम प्राप्त करता है।

नीचे शोधकर्ताओं द्वारा जारी वीडियो है। अधिक स्व-होस्टेड वीडियो परियोजना पृष्ठ पर उपलब्ध हैं।
https://www.youtube.com/watch?v=xig8ZA3DVZ8












