रोबोटिक्स
रोबोट ने रीनफोर्समेंट लर्निंग के माध्यम से चलना सिखाया
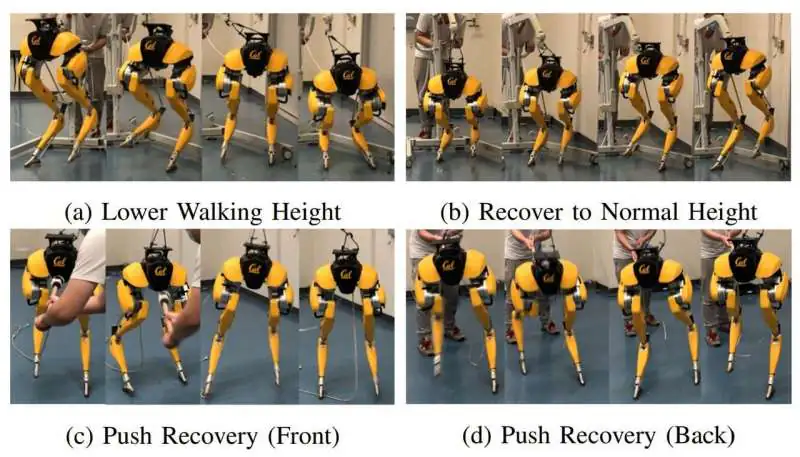
जबकि बोस्टन डायनामिक्स और नृत्य करने वाले रोबोट आमतौर पर सबसे अधिक ध्यान आकर्षित करते हैं, वहाँ कुछ प्रमुख विकास हो रहे हैं जो पर्याप्त कवरेज नहीं प्राप्त करते हैं। उनमें से एक विकास बर्कले लैब से आता है, जहाँ एक रोबोट कैसी ने रीनफोर्समेंट लर्निंग के माध्यम से चलना सिखाया।
परीक्षण और त्रुटि के बाद, रोबोटिक पैरों की जोड़ी ने एक सिम्युलेटेड वातावरण में नेविगेट करना सीखा trước कि वास्तविक दुनिया में परीक्षण किया जाए। शुरू में, रोबोट ने सभी दिशाओं में चलने, झुककर चलने, संतुलन से धक्का देने पर खुद को पुनः स्थापित करने और विभिन्न प्रकार की सतहों के अनुसार समायोजित करने की क्षमता प्रदर्शित की।
कैसी रोबोट दो पैरों वाले रोबोट का पहला उदाहरण है जिसने चलने के लिए रीनफोर्समेंट लर्निंग का सफलतापूर्वक उपयोग किया है।
नृत्य करने वाले रोबोट की आश्चर्य
जबकि बोस्टन डायनामिक्स जैसे रोबोट अत्यधिक प्रभावशाली हैं और लगभग सभी को जो उन्हें देखते हैं आश्चर्यचकित करते हैं, वहाँ कुछ प्रमुख कारक हैं। सबसे उल्लेखनीय बात यह है कि ये रोबोट हाथ से प्रोग्राम किए जाते हैं और निर्देशित किए जाते हैं ताकि परिणाम प्राप्त किया जा सके, लेकिन यह वास्तविक दुनिया की स्थितियों में पसंदीदा तरीका नहीं है।
प्रयोगशाला के बाहर, रोबोट को मजबूत, लचीला, और अधिक होना चाहिए। इसके अलावा, उन्हें अप्रत्याशित स्थितियों का सामना करने और उन्हें स्वयं संभालने में सक्षम होना चाहिए, जो केवल उन्हें ऐसी स्थितियों को संभालने में सक्षम बनाने से किया जा सकता है।
ज़ोंगयू ली बर्कले विश्वविद्यालय में कैसी पर काम करने वाली टीम का हिस्सा था।
“इन वीडियो को देखकर कुछ लोग सोच सकते हैं कि यह एक हल किया गया और आसान समस्या है,” ली कहते हैं। “लेकिन हमें मानवीय वातावरण में मानवीय रोबोट को विश्वसनीय रूप से संचालित करने और रहने के लिए अभी भी एक लंबा रास्ता तय करना है।”
https://www.youtube.com/watch?v=goxCjGPQH7U
रीनफोर्समेंट लर्निंग
एक ऐसा रोबोट बनाने के लिए, बर्कले टीम ने रीनफोर्समेंट लर्निंग पर भरोसा किया, जिसे डीपमाइंड जैसी कंपनियों ने मानवों को दुनिया के सबसे जटिल खेलों में हराने के लिए एल्गोरिदम को प्रशिक्षित करने के लिए उपयोग किया है। रीनफोर्समेंट लर्निंग परीक्षण और त्रुटि पर आधारित है, जिसमें रोबोट अपनी गलतियों से सीखता है।
कैसी रोबोट ने एक सिम्युलेशन में चलना सीखने के लिए रीनफोर्समेंट लर्निंग का उपयोग किया, जो पहली बार इस दृष्टिकोण का उपयोग नहीं किया गया है। हालांकि, यह आमतौर पर सिम्युलेटेड वातावरण से बाहर निकलकर वास्तविक दुनिया में नहीं आता है। एक छोटा सा अंतर भी रोबोट को चलने में विफल कर सकता है।
शोधकर्ताओं ने एक के बजाय दो सिम्युलेशन का उपयोग किया, जिसमें पहला एक ओपन सोर्स प्रशिक्षण वातावरण म्यूजोको था। इस पहले सिम्युलेशन में, एल्गोरिदम ने संभावित आंदोलनों की एक लाइब्रेरी से परीक्षण और सीखा, और दूसरे सिम्युलेशन सिममेकेनिक्स में, रोबोट ने अधिक वास्तविक दुनिया की स्थितियों में उन्हें परीक्षण किया।
दो सिम्युलेशन में विकसित होने के बाद, एल्गोरिदम को बारीक ट्यूनिंग की आवश्यकता नहीं थी। यह पहले से ही वास्तविक दुनिया में तैयार था। न केवल यह चलने में सक्षम था, बल्कि यह बहुत कुछ कर सकता था। शोधकर्ताओं के अनुसार, कैसी रोबोट के घुटने में दो मोटर्स के दोषपूर्ण होने के बाद भी यह पुनः स्थापित हो सकता था।
जबकि कैसी के पास अन्य रोबोटों की तरह सभी घंटियाँ और सीटी नहीं हो सकती हैं, यह कई मायनों में कहीं अधिक प्रभावशाली है। इसके अलावा यह वास्तविक दुनिया के उपयोग के लिए प्रौद्योगिकी के लिए बड़े प्रभाव हैं, क्योंकि एक ऐसा चलने वाला रोबोट विभिन्न क्षेत्रों में उपयोग किया जा सकता है।












