कृत्रिम बुद्धिमत्ता
एकल प्रश्न के लिए जीपीटी-शैली की भाषा मॉडल बनाना

चीन के शोधकर्ताओं ने जीपीटी-3 शैली की प्राकृतिक भाषा प्रसंस्करण प्रणाली बनाने के लिए एक आर्थिक तरीका विकसित किया है, जिसमें उच्च मात्रा वाले डेटासेट को प्रशिक्षित करने में समय और पैसे के बढ़ते खर्च से बचा जा सकता है – एक बढ़ती प्रवृत्ति जो अन्यथा अंततः इस क्षेत्र को एआई के लिए फांग खिलाड़ियों और उच्च-स्तरीय निवेशकों के लिए प्रतिबंधित कर देगी।
प्रस्तावित फ्रेमवर्क को टास्क-ड्रिवन लैंग्वेज मॉडलिंग (टीएलएम) कहा जाता है। अरबों शब्दों और हजारों लेबल और वर्गों के विशाल निगम पर एक विशाल और जटिल मॉडल को प्रशिक्षित करने के बजाय, टीएलएम एक बहुत छोटा मॉडल प्रशिक्षित करता है जो वास्तव में मॉडल के अंदर सीधे एक प्रश्न को शामिल करता है।

बाएं, उच्च मात्रा वाले भाषा मॉडल के लिए एक典型 हाइपरस्केल दृष्टिकोण; दाएं, टीएलएम का स्लिमलाइन तरीका एक विषय या प्रश्न प्रति आधार पर एक बड़े भाषा निगम का अन्वेषण करने के लिए। स्रोत: https://arxiv.org/pdf/2111.04130.pdf
वास्तव में, एक अद्वितीय एनएलपी एल्गोरिदम या मॉडल एकल प्रश्न का उत्तर देने के लिए उत्पादित किया जाता है, एक विशाल और अव्यावहारिक सामान्य भाषा मॉडल बनाने के बजाय जो व्यापक विविधता के प्रश्नों का उत्तर दे सकता है।
टीएलएम का परीक्षण करते समय, शोधकर्ताओं ने पाया कि नई दृष्टिकोण प्रीट्रेन्ड लैंग्वेज मॉडल जैसे रॉबर्टा-लार्ज, और हाइपरस्केल एनएलपी सिस्टम जैसे ओपनएआई के जीपीटी-3, गूगल के ट्रिलियन पैरामीटर स्विच ट्रांसफॉर्मर मॉडल, कोरिया के हाइपरक्लोवर, एआई21 लैब्स के जुरासिक 1, और माइक्रोसॉफ्ट के मेगाट्रॉन-ट्यूरिंग एनएलजी 530बी के समान या बेहतर परिणाम प्राप्त करता है।
चार डोमेन में आठ वर्गीकरण डेटासेट पर टीएलएम के परीक्षण में, लेखकों ने अतिरिक्त रूप से पाया कि प्रणाली प्रशिक्षण फ्लॉप्स (फ्लोटिंग पॉइंट ऑपरेशन प्रति सेकंड) को दो ऑर्डर के द्वारा कम करती है। शोधकर्ताओं को उम्मीद है कि टीएलएम एक क्षेत्र को ‘लोकतांत्रिक’ कर सकता है जो बढ़ती एलिट हो रहा है, जिसमें एनएलपी मॉडल इतने बड़े हैं कि उन्हें वास्तव में स्थानीय रूप से स्थापित नहीं किया जा सकता है, और इसके बजाय जीपीटी-3 के मामले में ओपनएआई और अब माइक्रोसॉफ्ट एज्योर के महंगे और सीमित-अクセस एपीआई के पीछे बैठते हैं।
लेखकों का कहना है कि प्रशिक्षण समय को दो ऑर्डर से कम करने से 1,000 जीपीयू पर एक दिन के लिए प्रशिक्षण लागत 8 जीपीयू पर 48 घंटे तक कम हो जाती है।
नई रिपोर्ट का शीर्षक बिना बड़े पैमाने पर प्रीट्रेनिंग के एनएलपी: एक सरल और कुशल फ्रेमवर्क है, और बीजिंग में त्सिंगहुआ विश्वविद्यालय के तीन शोधकर्ताओं और चीन स्थित एआई विकास कंपनी रिकरेंट एआई, इंक से एक शोधकर्ता से आता है।
असहनीय उत्तर
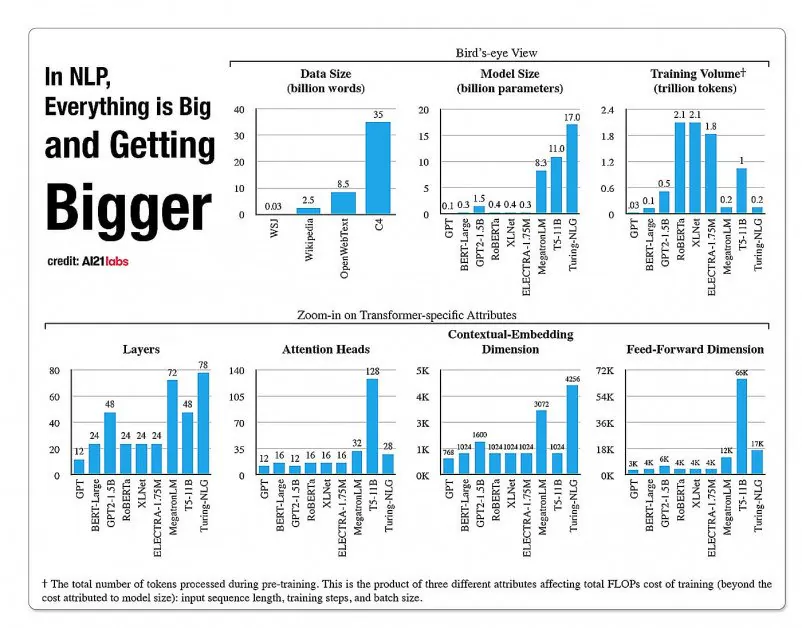
प्रभावी और सर्व-purpose भाषा मॉडल को प्रशिक्षित करने की लागत बढ़ती हुई एक संभावित ‘थर्मल सीमा’ के रूप में वर्णित की जा रही है जिस तक प्रदर्शनी और सटीक एनएलपी वास्तव में संस्कृति में फैल सकती है।

एनएलपी मॉडल आर्किटेक्चर में फेसेट्स के विकास के आंकड़े, ए121 लैब्स की 2020 की रिपोर्ट से। स्रोत: https://arxiv.org/pdf/2004.08900.pdf
2019 में एक शोधकर्ता गणना की कि एक्सएलनेट मॉडल (एक्सएलनेट मॉडल) को 2.5 दिनों में 512 कोर पर 64 डिवाइस पर प्रशिक्षित करने में $61,440 यूएसडी का खर्च आता है, जबकि जीपीटी-3 को प्रशिक्षित करने में $12 मिलियन का खर्च आया – इसके पूर्ववर्ती जीपीटी-2 के खर्च से 200 गुना अधिक (हालांकि हाल के पुनर्मूल्यांकन का दावा है कि इसे अब केवल $4,600,000 पर न्यूनतम मूल्य वाले क्लाउड जीपीयू पर प्रशिक्षित किया जा सकता है)।
प्रश्न आवश्यकताओं के आधार पर डेटा के उपसेट
इसके बजाय, नई प्रस्तावित वास्तुकला एक प्रश्न को एक फिल्टर के रूप में उपयोग करके एक बड़े भाषा डेटाबेस से जानकारी का एक उपसेट प्राप्त करने का प्रयास करती है जो प्रशिक्षित किया जाएगा, साथ ही प्रश्न के साथ मिलकर सीमित विषय पर उत्तर प्रदान करने के लिए।
लेखकों का कहना है:
‘टीएलएम दो मुख्य विचारों से प्रेरित है। पहला, मानव एक कार्य को पूरा करने के लिए विश्व ज्ञान के एक छोटे से हिस्से का उपयोग करते हैं (उदाहरण के लिए, छात्रों को परीक्षा की तैयारी के लिए दुनिया भर की किताबों में से कुछ अध्यायों की समीक्षा करने की आवश्यकता होती है)। ‘
‘हमें लगता है कि एक विशिष्ट कार्य के लिए एक बड़े निगम में बहुत अधिक अतिरेक है। दूसरा, अनलेबल्ड डेटा पर भाषा मॉडलिंग ऑब्जेक्टिव को अनुकूलित करने की तुलना में पर्यवेक्षित लेबल वाले डेटा पर प्रशिक्षण करना डाउनस्ट्रीम प्रदर्शन के लिए बहुत अधिक डेटा कुशल है। टीएलएम कार्य डेटा को सामान्य निगम से एक छोटे से उपसेट को पुनर्प्राप्त करने के लिए क्वेरी के रूप में उपयोग करता है। इसके बाद दोनों पुनर्प्राप्त डेटा और कार्य डेटा का उपयोग करके एक पर्यवेक्षित कार्य ऑब्जेक्टिव और एक भाषा मॉडलिंग ऑब्जेक्टिव को संयुक्त रूप से अनुकूलित किया जाता है।’
इसके अलावा, टीएलएम का उपयोग करके अत्यधिक प्रभावी एनएलपी मॉडल प्रशिक्षण को सस्ती बनाने, शोधकर्ताओं को अधिक लचीलापन मिल सकता है, जिसमें क्रम अनुक्रम, टोकनाइजेशन, हाइपरपैरामीटर ट्यूनिंग और डेटा प्रतिनिधित्व के लिए कस्टम रणनीतियां शामिल हैं।
शोधकर्ताओं को आगे भी हाइब्रिड भविष्य की प्रणालियों का विकास दिखाई देता है जो सीमित प्रीट्रेनिंग को अधिक बहुमुखी प्रतिभा और सामान्यीकरण के खिलाफ प्रशिक्षण समय के साथ व्यापार करते हैं। वे प्रणाली को इन-डोमेन जीरो-शॉट सामान्यीकरण विधियों के विकास के लिए एक कदम के रूप में मानते हैं।
परीक्षण और परिणाम
टीएलएम को चार डोमेन में आठ कार्यों पर वर्गीकरण चुनौतियों पर परीक्षण किया गया था – जैव चिकित्सा विज्ञान, समाचार, समीक्षा और कंप्यूटर विज्ञान। कार्यों को उच्च-संसाधन और निम्न-संसाधन श्रेणियों में विभाजित किया गया था। उच्च संसाधन कार्यों में 5,000 से अधिक कार्य डेटा शामिल थे, जैसे कि एजी न्यूज और आरसीटी, अन्य लोगों के बीच; निम्न-संसाधन कार्यों में केमप्रोट और एसीएल-एआरसी, साथ ही हाइपरपार्टिसन समाचार पता लगाने वाले डेटासेट शामिल थे।
शोधकर्ताओं ने दो प्रशिक्षण सेट विकसित किए जिन्हें कॉर्पस-बर्ट और कॉर्पस-रॉबर्टा कहा जाता है, बाद वाला पूर्व के आकार से दस गुना बड़ा है। प्रयोगों ने सामान्य प्रीट्रेन्ड लैंग्वेज मॉडल बर्ट (गूगल से) और रॉबर्टा (फेसबुक से) की तुलना नई वास्तुकला से की।
लेख में कहा गया है कि हालांकि टीएलएम एक सामान्य विधि है, और इसका दायरा और अनुप्रयोग_state-of-the-art मॉडल की तुलना में अधिक सीमित होना चाहिए, यह डोमेन-आधारित फाइन-ट्यूनिंग विधियों के करीब प्रदर्शन करने में सक्षम है।

टीएलएम के प्रदर्शन की तुलना बर्ट और रॉबर्टा-आधारित सेट के साथ। परिणाम तीन अलग-अलग प्रशिक्षण स्केल पर औसत एफ1 स्कोर सूचीबद्ध करते हैं, और पैरामीटर की संख्या, कुल प्रशिक्षण गणना (फ्लॉप्स) और प्रशिक्षण निगम के आकार को सूचीबद्ध करते हैं।
लेखकों का निष्कर्ष है कि टीएलएम पीएलएम के समान या बेहतर परिणाम प्राप्त करने में सक्षम है, जिसमें फ्लॉप्स की आवश्यकता में काफी कमी है, और केवल 1/16 वें प्रशिक्षण निगम की आवश्यकता होती है। मध्यम और बड़े पैमाने पर, टीएलएम कथित तौर पर 0.59 और 0.24 अंकों द्वारा प्रदर्शन में सुधार कर सकता है, जबकि प्रशिक्षण डेटा आकार को दो ऑर्डर से कम कर सकता है।
‘इन परिणामों से पता चलता है कि टीएलएम बहुत सटीक और पीएलएम की तुलना में अधिक कुशल है। इसके अलावा, टीएलएम बड़े पैमाने पर अधिक लाभ प्राप्त करता है। यह दर्शाता है कि बड़े पैमाने पर पीएलएम को एक विशिष्ट कार्य के लिए उपयोगी नहीं होने वाले सामान्य ज्ञान को संग्रहीत करने के लिए प्रशिक्षित किया जा सकता है।’













{kind=link}