कृत्रिम बुद्धिमत्ता
ChatGPT की पहली वर्षगांठ: एआई इंटरैक्शन के भविष्य को फिर से परिभाषित करना

ChatGPT के पहले वर्ष पर विचार करते हुए, यह स्पष्ट है कि यह टूल एआई दृश्य को काफी बदल दिया है। 2022 के अंत में लॉन्च किया गया, ChatGPT अपने उपयोगकर्ता-मित्र, वार्तालाप शैली के कारण खड़ा हुआ जिसने एआई के साथ बातचीत करना एक मशीन की तुलना में एक व्यक्ति के साथ बातचीत करने जैसा महसूस कराया। यह नया दृष्टिकोण जल्द ही सार्वजनिक की नजर में आया। इसके रिलीज़ के पांच दिनों के भीतर, ChatGPT ने पहले ही एक मिलियन उपयोगकर्ताओं को आकर्षित कर लिया था। 2023 की शुरुआत में, यह संख्या लगभग 100 मिलियन मासिक उपयोगकर्ताओं तक बढ़ गई, और अक्टूबर तक, प्लेटफ़ॉर्म दुनिया भर में लगभग 1.7 बिलियन विज़िट आकर्षित कर रहा था। ये संख्याएं इसकी लोकप्रियता और उपयोगिता के बारे में बहुत कुछ कहती हैं।
पिछले एक वर्ष में, उपयोगकर्ताओं ने ChatGPT का उपयोग करने के लिए सभी प्रकार के रचनात्मक तरीके खोजे हैं, सरल कार्यों जैसे कि ईमेल लिखना और रिज्यूमे अपडेट करने से लेकर सफल व्यवसाय शुरू करने तक। लेकिन यह केवल इतना नहीं है कि लोग इसका उपयोग कैसे कर रहे हैं; प्रौद्योगिकी स्वयं बढ़ी और सुधार हुई है। शुरू में, ChatGPT एक नि:शुल्क सेवा थी जो विस्तृत पाठ प्रतिक्रियाएं प्रदान करती थी। अब, ChatGPT Plus है, जिसमें ChatGPT-4 शामिल है। यह अद्यतन संस्करण अधिक डेटा पर प्रशिक्षित है, कम गलत उत्तर देता है, और जटिल निर्देशों को बेहतर ढंग से समझता है।
एक सबसे बड़ा अद्यतन यह है कि ChatGPT अब कई तरह से बातचीत कर सकता है – यह सुन सकता है, बोल सकता है, और यहां तक कि छवियों को संसाधित कर सकता है। इसका मतलब है कि आप इसके मोबाइल ऐप के माध्यम से इसके साथ बातचीत कर सकते हैं और इसके लिए प्रतिक्रिया प्राप्त करने के लिए तस्वीरें दिखा सकते हैं। इन परिवर्तनों ने एआई के लिए नए अवसर खोले हैं और लोगों ने अपने जीवन में एआई की भूमिका के बारे में कैसे सोचा है, इसे बदल दिया है।
इसकी शुरुआत एक तकनीकी प्रदर्शन के रूप में हुई थी लेकिन अब यह तकनीकी दुनिया में एक प्रमुख खिलाड़ी है, ChatGPT की यात्रा काफी प्रभावशाली है। शुरू में, यह तकनीक को परीक्षण और सुधार करने के लिए एक तरीके के रूप में देखा गया था जो सार्वजनिक प्रतिक्रिया प्राप्त करके हासिल किया जा सकता है। लेकिन यह जल्द ही एआई परिदृश्य का एक आवश्यक हिस्सा बन गया। यह सफलता यह दिखाती है कि बड़े भाषा मॉडल (एलएलएम) को पर्यवेक्षित शिक्षण और मानव प्रतिक्रिया दोनों के साथ ठीक करना कितना प्रभावी है। इसके परिणामस्वरूप, ChatGPT विभिन्न प्रश्नों और कार्यों को संभाल सकता है।
एआई प्रणालियों को विकसित करने की दौड़ जो सबसे सक्षम और बहुमुखी हैं, ने खुले स्रोत और प्रोप्राइटरी मॉडल जैसे ChatGPT के प्रसार को जन्म दिया है। उनकी सामान्य क्षमताओं को समझने के लिए विभिन्न कार्यों के व्यापक स्पेक्ट्रम में संपूर्ण बेंचमार्क की आवश्यकता है। यह अनुभाग इन बेंचमार्क की खोज करता है, जो यह दिखाता है कि विभिन्न मॉडल, ChatGPT सहित, एक दूसरे के खिलाफ कैसे खड़े होते हैं।
एलएलएम का मूल्यांकन: बेंचमार्क
- एमटी-बेंच: यह बेंचमार्क आठ डोमेन में बहु-मोड़ बातचीत और निर्देश-अनुसरण क्षमताओं का परीक्षण करता है: लेखन, भूमिका-निभाना, जानकारी निकालना, तर्क, गणित, कोडिंग, विज्ञान ज्ञान, और मानविकी/सामाजिक विज्ञान। मजबूत एलएलएम जैसे जीपीटी-4 का उपयोग मूल्यांकनकर्ता के रूप में किया जाता है।
- अल्पाकाएवल: अल्पाकाफार्म मूल्यांकन सेट पर आधारित, यह एलएलएम-आधारित स्वचालित मूल्यांकनकर्ता मॉडल को उन्नत एलएलएम जैसे जीपीटी-4 और क्लॉड की प्रतिक्रियाओं के खिलाफ बेंचमार्क करता है, उम्मीदवार मॉडल की जीत दर की गणना करता है।
- ओपन एलएलएम लीडरबोर्ड: भाषा मॉडल मूल्यांकन हार्नेस का उपयोग करते हुए, यह लीडरबोर्ड एलएलएम को तर्क चुनौतियों और सामान्य ज्ञान परीक्षणों सहित सात प्रमुख बेंचमार्क पर मूल्यांकन करता है, ज़ीरो-शॉट और कुछ-शॉट सेटिंग्स दोनों में।
- बिग-बेंच: यह सहयोगी बेंचमार्क 200 से अधिक नए भाषा कार्यों को कवर करता है, विभिन्न विषयों और भाषाओं की एक विविध श्रृंखला को शामिल करता है। इसका उद्देश्य एलएलएम की जांच करना और उनकी भविष्य की क्षमताओं की भविष्यवाणी करना है।
- चैटइवल: एक बहु-एजेंट बहस ढांचा जो टीमों को स्वचालित रूप से विभिन्न मॉडलों से प्रतिक्रियाओं की गुणवत्ता पर चर्चा और मूल्यांकन करने की अनुमति देता है, खुले प्रश्नों और पारंपरिक प्राकृतिक भाषा पीढ़ी कार्यों पर।
तुलनात्मक प्रदर्शन
सामान्य बेंचमार्क के संदर्भ में, खुले स्रोत एलएलएम ने उल्लेखनीय प्रगति दिखाई है। लामा-2-70बी, उदाहरण के लिए, निर्देश डेटा के साथ फ़ाइन-ट्यूनिंग के बाद विशेष रूप से प्रभावशाली परिणाम हासिल किए। इसके वेरिएंट, लामा-2-चैट-70बी, अल्पाकाएवल में 92.66% जीत दर के साथ उत्कृष्ट प्रदर्शन किया, जीपीटी-3.5-टर्बो को पीछे छोड़ दिया। हालांकि, जीपीटी-4 अभी भी 95.28% जीत दर के साथ अग्रणी बना हुआ है।
ज़ेफ़र-7बी, एक छोटा मॉडल, अल्पाकाएवल और एमटी-बेंच में 70बी एलएलएम के समान क्षमता प्रदर्शित की, विशेष रूप से। इसके बीच, विज़ार्डएलएम-70बी, जो विविध निर्देश डेटा के साथ फ़ाइन-ट्यून किया गया था, खुले स्रोत एलएलएम में एमटी-बेंच पर उच्चतम स्कोर किया, हालांकि यह जीपीटी-3.5-टर्बो और जीपीटी-4 से पीछे रहा।
एक दिलचस्प प्रवेश, गोडज़िल्ला2-70बी, ओपन एलएलएम लीडरबोर्ड पर एक प्रतिस्पर्धी स्कोर हासिल किया, जो विभिन्न डेटासेट को जोड़ने वाले प्रायोगिक मॉडल की संभावना को प्रदर्शित करता है। इसी तरह, यी-34बी, जो शून्य से विकसित किया गया था, जीपीटी-3.5-टर्बो के साथ तुलनीय स्कोर के साथ खड़ा था और केवल जीपीटी-4 से थोड़ा पीछे था।
उल्ट्रालामा, जो विविध और उच्च गुणवत्ता वाले डेटा पर फ़ाइन-ट्यून किया गया था, जीपीटी-3.5-टर्बो को अपने प्रस्तावित बेंचमार्क में मिला और यहां तक कि कुछ क्षेत्रों में विश्व और पेशेवर ज्ञान में इसे पार कर गया।
स्केलिंग अप: जाइंट एलएलएम का उदय
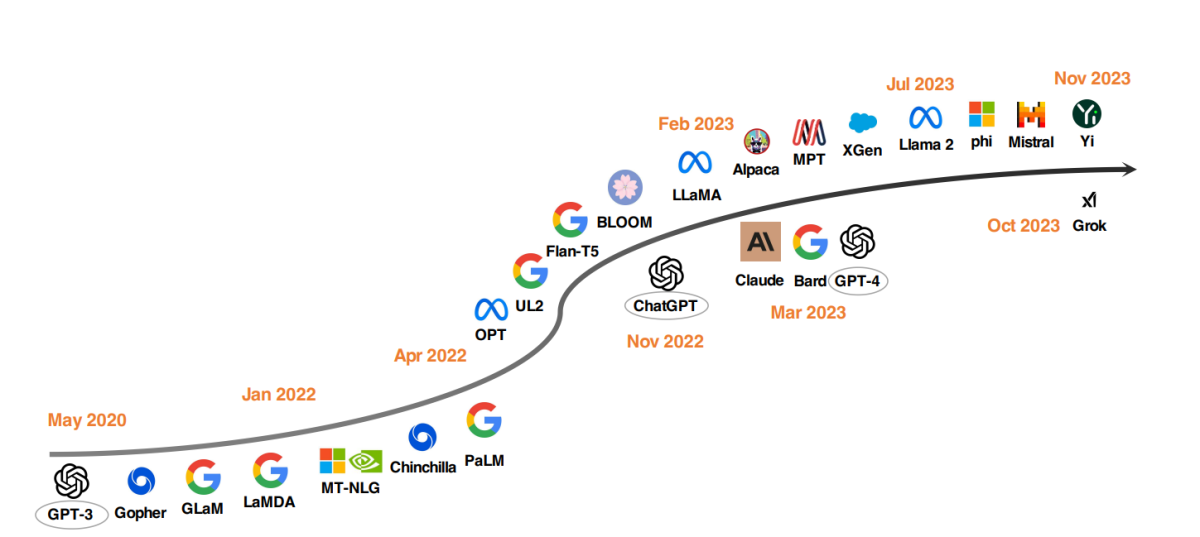
2020 से शीर्ष एलएलएम मॉडल
एलएलएम विकास में एक उल्लेखनीय रुझान मॉडल पैरामीटर को स्केल करना रहा है। जैसे मॉडल गोफर, जीएलएएम, लाम्डा, एमटी-एनएलजी, और पालएम ने सीमाओं को आगे बढ़ाया है, जो 540 बिलियन पैरामीटर तक के मॉडल में परिणत हुआ। इन मॉडलों ने असाधारण क्षमता दिखाई है, लेकिन उनकी बंद स्रोत प्रकृति ने उनके व्यापक अनुप्रयोग को सीमित कर दिया है। यह सीमा खुले स्रोत एलएलएम विकसित करने में रुचि को बढ़ावा दे रही है, जो एक रुझान है जो गति प्राप्त कर रहा है।
मॉडल के आकार को बढ़ाने के अलावा, शोधकर्ताओं ने वैकल्पिक रणनीतियों का अन्वेषण किया है। बड़े मॉडल बनाने के बजाय, उन्होंने छोटे मॉडलों के पूर्व-प्रशिक्षण में सुधार पर ध्यान केंद्रित किया है। चिंचिला और यूएल2 जैसे उदाहरण हैं जो दिखाते हैं कि अधिक हमेशा बेहतर नहीं होता; स्मार्ट रणनीतियां कुशल परिणाम प्रदान कर सकती हैं। इसके अलावा, भाषा मॉडल के निर्देश ट्यूनिंग पर काफी ध्यान दिया गया है, जिसमें फ्लैन, टी0, और फ्लैन-टी5 जैसी परियोजनाएं इस क्षेत्र में महत्वपूर्ण योगदान कर रही हैं।
चैटजीपीटी कैटालिस्ट
ओपनएआई के चैटजीपीटी की शुरुआत एनएलपी अनुसंधान में एक मोड़ का प्रतीक थी। ओपनएआई के साथ प्रतिस्पर्धा करने के लिए, कंपनियों जैसे गूगल और एंथ्रोपिक ने अपने मॉडल, बार्ड और क्लॉड को लॉन्च किया। जबकि ये मॉडल कई कार्यों में चैटजीपीटी के समान प्रदर्शन दिखाते हैं, वे अभी भी ओपनएआई के नवीनतम मॉडल, जीपीटी-4 से पीछे हैं। इन मॉडलों की सफलता मुख्य रूप से मानव प्रतिक्रिया से प्रबलित सीखने (आरएलएचएफ) तकनीक के लिए जिम्मेदार है, जो आगे सुधार के लिए बढ़ती अनुसंधान ध्यान का केंद्र है।
ओपनएआई के क्यू* (क्यू स्टार) के आसपास अफवाहें और अनुमान
हाल की रिपोर्ट सुझाव देती हैं कि ओपनएआई में शोधकर्ताओं ने एक नए मॉडल क्यू* (क्यू स्टार) के विकास के साथ एक महत्वपूर्ण प्रगति हासिल की हो सकती है। कथित तौर पर, क्यू* प्राथमिक स्तर की गणित करने में सक्षम है, जो विशेषज्ञों के बीच कृत्रिम सामान्य बुद्धिमत्ता (एजीआई) की ओर एक मील का पत्थर होने की चर्चा को उत्तेजित करता है। जबकि ओपनएआई ने इन रिपोर्टों पर टिप्पणी नहीं की है, क्यू* की कथित क्षमताओं ने सोशल मीडिया और एआई उत्साही लोगों के बीच काफी उत्साह और अनुमान पैदा किया है।
क्यू* का विकास उल्लेखनीय है क्योंकि मौजूदा भाषा मॉडल जैसे चैटजीपीटी और जीपीटी-4, जबकि कुछ गणितीय कार्यों में सक्षम हैं, उन्हें विश्वसनीय रूप से संभालने में特别 नहीं हैं। चुनौती यह है कि एआई मॉडल को न केवल पैटर्न को पहचानना चाहिए, जैसा कि वे वर्तमान में गहरे शिक्षण और ट्रांसफॉर्मर के माध्यम से करते हैं, बल्कि तर्क और अमूर्त अवधारणाओं को समझना चाहिए। गणित, एक तर्क के लिए एक बेंचमार्क होने के नाते, एआई को कई चरणों की योजना और निष्पादन की आवश्यकता है, जो अमूर्त अवधारणाओं की गहरी समझ को प्रदर्शित करता है। यह क्षमता एआई क्षमताओं में एक महत्वपूर्ण छलांग लगाएगी, संभावित रूप से गणित से परे अन्य जटिल कार्यों तक बढ़ सकती है।
हालांकि, विशेषज्ञ इस विकास को बढ़ा-चढ़ाकर पेश करने के खिलाफ चेतावनी देते हैं। जबकि एक एआई प्रणाली जो विश्वसनीय रूप से गणितीय समस्याओं का समाधान करती है, एक प्रभावशाली उपलब्धि होगी, यह आवश्यक रूप से सुपरइंटेलिजेंट एआई या एजीआई के आगमन का संकेत नहीं देती है। वर्तमान एआई अनुसंधान, ओपनएआई द्वारा किए गए प्रयासों सहित, मूलभूत समस्याओं पर केंद्रित है, जिसमें जटिल कार्यों में विभिन्न डिग्री की सफलता है।
क्यू* जैसी प्रगति के संभावित अनुप्रयोग व्यापक हैं, जो व्यक्तिगत ट्यूटरिंग से लेकर वैज्ञानिक अनुसंधान और इंजीनियरिंग में सहायता प्रदान करने तक हैं। हालांकि, यह महत्वपूर्ण है कि अपेक्षाओं को प्रबंधित किया जाए और ऐसी प्रगति से जुड़े सीमाओं और सुरक्षा चिंताओं को पहचाना जाए। एआई के अस्तित्व के जोखिमों के बारे में चिंताएं, ओपनएआई की एक मूल चिंता, विशेष रूप से प्रासंगिक रहती हैं क्योंकि एआई प्रणालियां वास्तविक दुनिया के साथ अधिक बातचीत करना शुरू करती हैं।
ओपन-सोर्स एलएलएम आंदोलन
ओपन-सोर्स एलएलएम अनुसंधान को बढ़ावा देने के लिए, मेटा ने लामा श्रृंखला मॉडल जारी की, जो लामा पर आधारित नए विकास की लहर को ट्रिगर करता है। इसमें अल्पाका, विकुना, लीमा, और विज़ार्डएलएम जैसे मॉडल शामिल हैं जो निर्देश डेटा के साथ फ़ाइन-ट्यून किए गए हैं। अनुसंधान लामा-आधारित ढांचे के भीतर एजेंट क्षमताओं, तर्कसंगत तर्क, और लंबे संदर्भ मॉडलिंग में सुधार पर भी शाखा लगा रहा है।
इसके अलावा, शक्तिशाली एलएलएम को शून्य से विकसित करने की एक बढ़ती हुई प्रवृत्ति है, जिसमें एमपीटी, फाल्कन, एक्सजेन, फी, बैचुआन, मिस्ट्रल, ग्रोक, और यी जैसी परियोजनाएं शामिल हैं। ये प्रयास बंद स्रोत एलएलएम की क्षमताओं को लोकतांत्रिक बनाने की प्रतिबद्धता को प्रतिबिंबित करते हैं, उन्नत एआई टूल को अधिक सुलभ और कुशल बनाते हैं।
चैटजीपीटी और ओपन सोर्स मॉडल का स्वास्थ्य सेवा पर प्रभाव
हम एक भविष्य की ओर देख रहे हैं जहां एलएलएम नैदानिक नोट्स लेने, पुनर्भुगतान के लिए फॉर्म भरने, और चिकित्सकों को निदान और उपचार योजना में सहायता करने में मदद करेंगे। यह दोनों प्रौद्योगिकी दिग्गजों और स्वास्थ्य सेवा संस्थानों का ध्यान आकर्षित किया है।
माइक्रोसॉफ्ट के एपिक के साथ चर्चा, एक प्रमुख इलेक्ट्रॉनिक स्वास्थ्य रिकॉर्ड सॉफ्टवेयर प्रदाता के साथ, एलएलएम को स्वास्थ्य सेवा में एकीकरण का संकेत देता है। पहले से ही यूसी सैन डिएगो हेल्थ और स्टैनफोर्ड यूनिवर्सिटी मेडिकल सेंटर में पहल शुरू की जा चुकी है। इसी तरह, गूगल के मायो क्लिनिक के साथ साझेदारी और अमेज़न वेब सेवाओं द्वारा हेल्थस्क्राइब, एक एआई क्लिनिकल डॉक्यूमेंटेशन सेवा के लॉन्च ने इस दिशा में महत्वपूर्ण कदम उठाए हैं।
हालांकि, इन तेजी से तैनाती चिंताएं उठाती हैं कि चिकित्सा पर निगरानी को कॉर्पोरेट हितों को सौंपा जा रहा है। इन एलएलएम की प्रोप्राइटरी प्रकृति उन्हें मूल्यांकन करना मुश्किल बनाती है। उनके संभावित संशोधन या लाभकारी कारणों से बंद करना रोगी देखभाल, गोपनीयता, और सुरक्षा को खतरे में डाल सकता है।
स्वास्थ्य सेवा में एलएलएम विकास के लिए तत्काल आवश्यकता एक खुला और समावेशी दृष्टिकोण है। स्वास्थ्य सेवा संस्थानों, शोधकर्ताओं, चिकित्सकों, और रोगियों को वैश्विक स्तर पर एक साथ मिलकर स्वास्थ्य सेवा के लिए खुले स्रोत एलएलएम बनाने के लिए मिलकर काम करना चाहिए। यह दृष्टिकोण, ट्रिलियन पैरामीटर कंसोर्टियम के समान, कम्प्यूटेशनल, वित्तीय संसाधनों, और विशेषज्ञता को पूल करने की अनुमति देगा।












