AI 101
Mitkä ovat RNN:t ja LSTMit syvän oppimisen alalla?
Monet merkittävimmistä edistysaskelista luonnollisen kielen prosessoinnissa ja AI-keskustelurobooteissa perustuvat Toistuvasti Neuroverkkoihin (RNN) ja Pitkän Lyhytaikaisen Muistin (LSTM) verkkoihin. RNN:t ja LSTMit ovat erityisiä neuroverkkoarkkitehtuureja, jotka pystyvät prosessoimaan sekvenssi-dataa, dataa, jossa aikajärjestys on merkittävä. LSTMit ovat periaatteessa parannettuja versioita RNN:istä, jotka pystyvät tulkkaamaan pidempiä datajonoja. Tarkastellaan, miten RNN:t ja LSTMit ovat rakennettu ja miten ne mahdollistavat monimutkaisten luonnollisen kielen prosessointijärjestelmien luomisen.
Mitä ovat Feed-Forward Neuroverkkot?
Ennen kuin puhumme siitä, miten Long Short-Term Memory (LSTM) ja Convolutional Neuroverkkot (CNN) toimivat, meidän tulisi keskustella neuroverkon yleisestä muodosta.
Neuroverkko on tarkoitettu tutkimaan dataa ja oppimaan merkittäviä kuvioita, jotta nämä kuvioita voidaan soveltaa muihin datoihin ja uusia datoja voidaan luokitella. Neuroverkkot on jaettu kolmeen osaan: syötekerrokseen, piilotettuun kerrokseen (tai useisiin piilotettuihin kerroksiin) ja ulostuskerrokseen.
Syötekerros on se, joka ottaa datan neuroverkkoon, kun taas piilotetut kerrokset ovat ne, jotka oppivat datan kuvioita. Piilotetut kerrokset datassa ovat yhdistetty syöte- ja ulostuskerroksiin “painoilla” ja “harhoilla”, jotka ovat vain oletuksia siitä, miten datapisteet liittyvät toisiinsa. Nämä painot säätetään koulutuksen aikana. Kun verkko koulutetaan, mallin arvaukset koulutusdatasta (ulostusarvot) verrataan todellisiin koulutusmerkintöihin. Koulutuksen aikana verkko tulisi (toivottavasti) tulla tarkemmaksi ennustamaan suhteita datapisteiden välillä, jotta se voi tarkalleen luokitella uusia datapisteitä. Syvät neuroverkkot ovat verkkot, joissa on enemmän kerroksia keskellä/enemmän piilotettuja kerroksia. Mitä enemmän piilotettuja kerroksia ja solmuja mallissa on, sitä paremmin malli tunnistaa kuvioita datassa.
Tavalliset, eteenpäin suuntautuvat neuroverkkot, kuten ne, joista olen kuvannut yllä, kutsutaan usein “tiheiksi neuroverkoiksi”. Nämä tiheät neuroverkkot yhdistetään erilaisiin verkkorakenteisiin, jotka erikoistuvat erilaisten datojen tulkintaan.
Mitä ovat RNN:t (Toistuvasti Neuroverkkot)?

Toistuvasti Neuroverkkot ottavat yleisen periaatteen eteenpäin suuntautuvista neuroverkoista ja mahdollistavat niiden käsittelyn sekvenssi-dataa antamalla mallille sisäisen muistin. “Toistuva” osa RNN:n nimestä tulee siitä, että syöte ja ulostus kierrätetään. Kun verkon ulostus on tuotettu, ulostus kopioituu ja palautetaan verkkoon syötteenä. Kun tehdään päätös, ei vain nykyistä syötettä ja ulostusta analyysoida, vaan myös edellistä syötettä otetaan huomioon. Toisin sanoen, jos alkuperäinen syöte verkolle on X ja ulostus on H, sekä H että X1 (seuraava syöte datajonoissa) syötetään verkkoon seuraavaan koulutusjaksoon. Tällä tavoin datan konteksti (edelliset syötteet) säilytetään, kun verkko koulutetaan.
Tämän arkkitehtuurin seuraus on, että RNN:t pystyvät käsittelemään sekvenssi-dataa. RNN:t kuitenkin kärsivät joistakin ongelmista. RNN:t kärsivät häviävän gradientin ja räjähtävän gradientin ongelmista.
RNN:ien tulkittavissa olevien sekvenssien pituus on melko rajoitettu, erityisesti verrattuna LSTMeihin.
Mitä ovat LSTMit (Pitkän Lyhytaikaisen Muistin Verkkot)?
Pitkän Lyhytaikaisen Muistin verkkot voidaan pitää RNN:ien laajennuksina, jotka soveltavat edelleen syötteiden kontekstin säilyttämisen periaatetta. LSTMit on kuitenkin muutettu useilla tärkeillä tavoilla, jotka mahdollistavat niiden tulkinnan aiempaa dataa paremmilla menetelmillä. LSTMeihin tehtyjen muutosten ansiosta ne pystyvät ratkaisemaan häviävän gradientin ongelman ja käsittelemään paljon pidempiä syötejonoja.

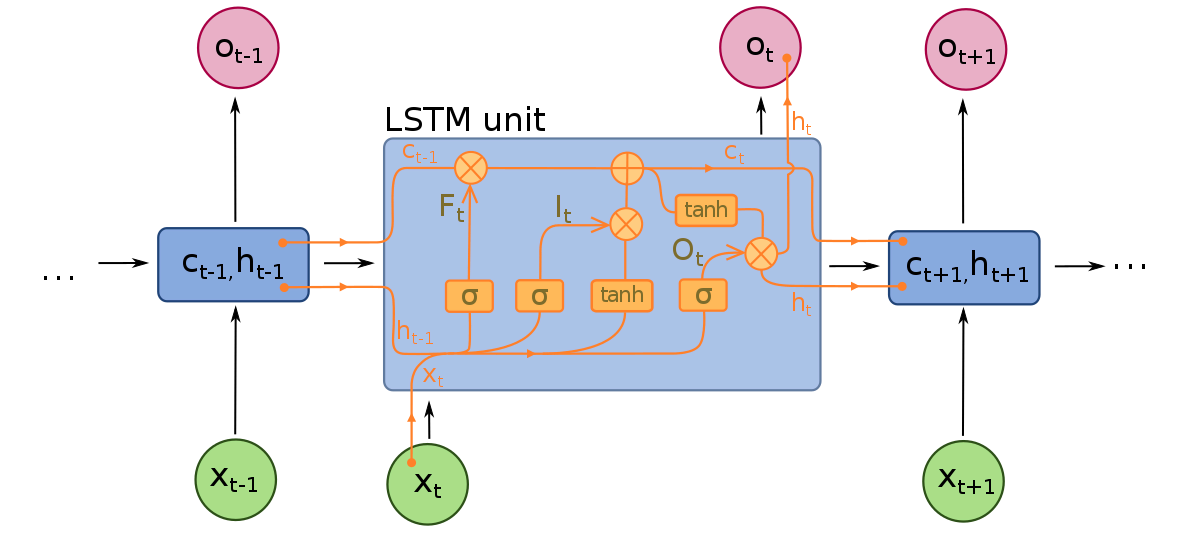
LSTM-mallit koostuvat kolmesta eri komponentista, tai porteista. On syöteportti, ulosteportti ja unohdusportti. Kuten RNN:t, LSTMit ottaa huomioon edellisen aikajanan syötteitä muuttaessaan mallin muistia ja syötepainoja. Syöteportti tekee päätöksiä siitä, mitkä arvot ovat tärkeitä ja mitkä pitäisi päästää mallin läpi. Sigmoid-funktiota käytetään syöteportissa, joka tekee päätöksiä siitä, mitkä arvot pitäisi välittää toistuvan verkon läpi. Nolla pudottaa arvon, kun taas 1 säilyttää sen. TanH-funktiota käytetään myös tässä, joka päättää, kuinka tärkeitä syötearvot ovat mallille, vaihdellen -1:stä 1:een.
Kun nykyiset syötteet ja muistitila on otettu huomioon, ulosteportti päättää, mitkä arvot pitäisi välittää seuraavaan aikaskaskaan laskuun. Ulostusportissa arvot analyysoidaan ja niille annetaan tärkeys, joka vaihtelee -1:stä 1:een. Tämä säätelee dataa ennen kuin se siirretään seuraavaan aikaskaskaan laskuun. Lopulta, unohdusportin tehtävä on pudottaa tietoa, jonka malli pitää tarpeettomana päätöksenteon kannalta syötearvojen luonteesta. Unohdusportissa sigmoid-funktiota käytetään arvoille, josta tulee luvut välillä 0 (unohda tämä) ja 1 (säilytä tämä).
LSTM-neuroverkko koostuu sekä erityisistä LSTM-kerroksista, jotka voivat tulkita sekvenssi-sanadataa, että tiiviisti yhdistetyistä kerroksista, kuten yllä on kuvattu. Kun data kulkee LSTM-kerrosten läpi, se siirtyy tiiviisti yhdistettyihin kerroksiin.








